1 背景
- 目前的众多推荐算法不能很好的用到新闻中潜在的语义信息
- 新闻推荐有很高的时间敏感性,新旧更替很频繁,使传统的以ID为基础的协同过滤效果降低
- 根据用户的历史浏览信息来动态衡量候选项目是解决新闻推荐的关键因素
- 传统的语义模型/主题模型都是基于词的共现/词簇结构,不能很好地发现潜在的知识
2 创新点
- 把新闻题目中的每个单词、该单词所对应的实体、这些实体的上下文信息作为多渠道信息(三维,上文中每一个渠道信息都是一层)输送到网络里(兼顾了语义层面和知识层面),而一般的模型最多只是把这些信息向量简单的头尾相连起来
- 使用了注意力机制,对不同的浏览历史做不同的权重处理
3 算法思路
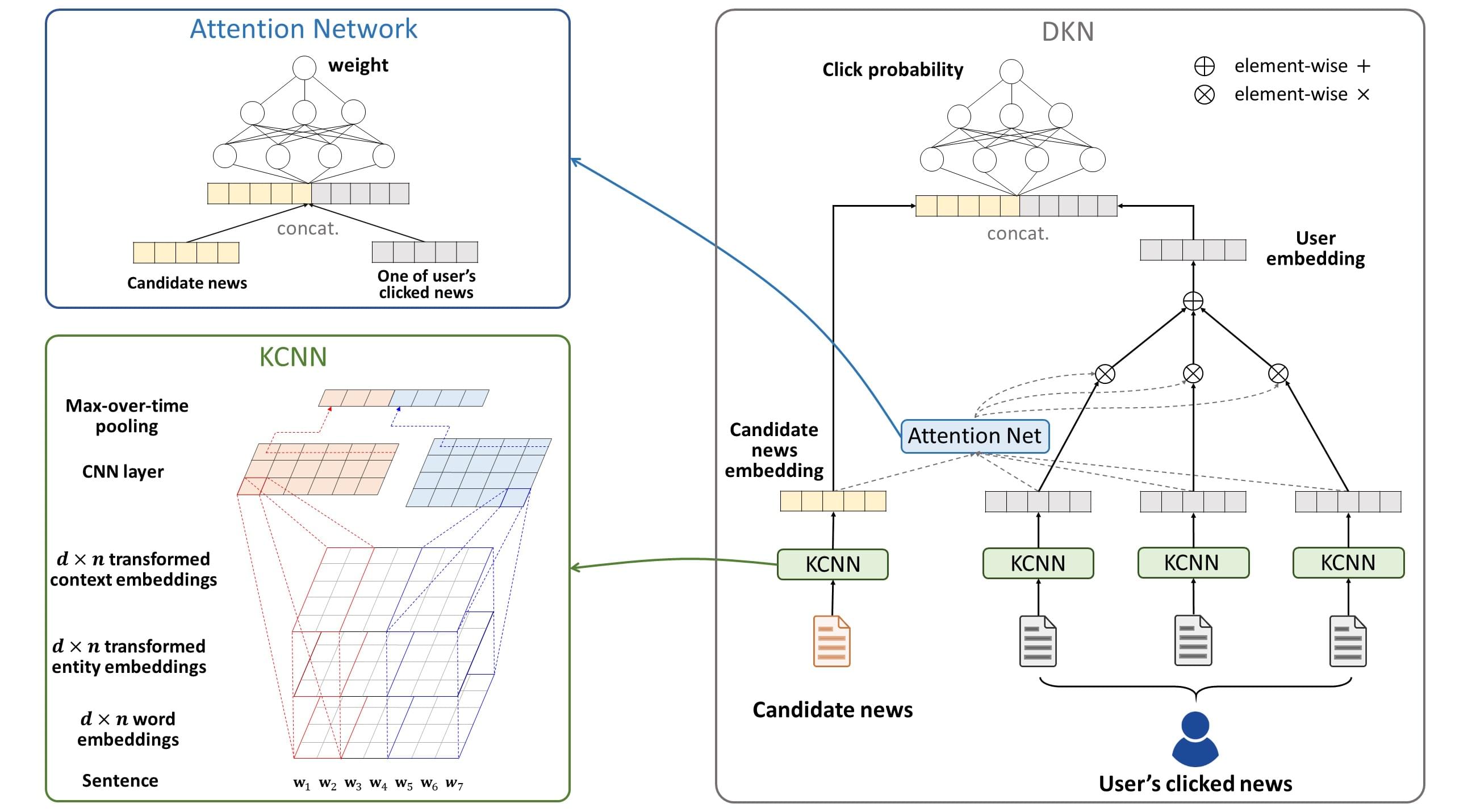
3.1 算法性质
基于内容的推荐,目的是评估点选率
3.2 输入/输出
$input$: 一条候选新闻、一个用户的多条历史浏览新闻 $output$: 这个用户选择候选新闻的概率
3.3 算法流程
- 对于每条新闻,其标题中的每个单词,都进行向知识图谱的实体链接,构建包含所有实体的子图,并将实体全部表示成向量
- 将每条新闻标题中单词的(词向量 + 其对应的实体向量[注:若无对应实体,则以零填充] + 其对应的上下文实体向量均值[注:处理方法同上])喂给KCNN,得到该条新闻的表示向量(KCNN的优点 ①多渠道输入 ②单词与实体得到了对齐)
- 用注意力模型(attention moudle)计算候选新闻与每条用户历史新闻的权重,将历史新闻加权平均得到用户表示向量
- 使用DNN计算候选新闻向量与用户表示向量的概率
4 文中模型
4.1 Knowledge Distilation(知识蒸馏/萃取)
- 实体链接: 把新闻题目中出现的实体与给定知识图谱中的实体对应起来
- 构建子图:抽取出这些实体以及他们的关系构建一个子图(为了解决稀疏性的问题,将这些实体的一跳实体也添加进该子图)
- 表示学习:将子图中的所有实体用知识图谱表示学习算法(TransH/TransR/TransD)表示成向量。
- 对于每个新闻单词对应实体的所有上下文实体向量,对他们进行求均值处理,得到实体的上下文表示向量
4.2 Knowledge-aware CNN(KCNN)
- 对于每条新闻,将其表示成一个$d×n$的矩阵的形式,$d$为每个单词向量的维度,$n$为单词数。(文中说可以从一个巨大的语料库预训练得到或者随机生成)
- 将实体表示向量和上下文表示向量通过两种方式①线性 $g(e)=Me $②非线性 $g(e)=tanh(Me+b)$,将实体的维度$k$转化成与单词向量的维度$d$相同($M是一个可训练的d×k阶矩阵$)
- 将单词向量/对应的实体向量/上下文表示向量堆叠起来(如果这个单词没有对应的实体,则后两部分用0表示),形成一个$d×n×3$的张量
- 通过卷积、最大池化得到新闻表示向量
4.3 Attention-based User Interest Extraction
- 由于用户历史浏览的每个新闻都会对候选新闻产生不同影响,采用注意力机制加权分配这些影响
- 用DNN计算每条历史新闻与候选新闻之间的影响,用$softmax$函数实现归一化
- 加权分配这些影响,得到最终的用户表示向量
- 用一个另外的DNN计算用户点击候选新闻的概率
5 代码实现
5.1 源码地址
A tensorflow implementation of DKN (Deep Knowledge-aware Network for News Recommendation)
Running the code:
$ cd data/news
$ python news_preprocess.py
$ cd ../kg
$ python prepare_data_for_transx.py
$ cd Fast-TransX/transE/ (note: you can also choose other KGE methods)
$ g++ transE.cpp -o transE -pthread -O3 -march=native
$ ./transE
$ cd ../..
$ python kg_preprocess.py
$ cd ../../src
$ python main.py (note: use -h to check optional arguments)