前言
之前看论文总想留下点什么痕迹(比如写个笔记),但是发现有时候这也算是一种造轮子的行为,因为每个划时代的研究早就有无数人(包括大牛)写过总结,且已经总结的很好了。所以我反思了一下,这篇博客便诞生了,主旨是不为每篇经典单独造一个轮子,而是做一个索引,指向那些漂亮优秀的轮子(包括源码、总结等)。而我自己,只附上我对每一个模型的一段话总结(我希望每段话都是经过深思熟虑,总结到位的)。
1 词向量
1.1 word2vec
1.2 FastText
1.3 ELMo
2 预训练(语言)模型
2.1 Transformer
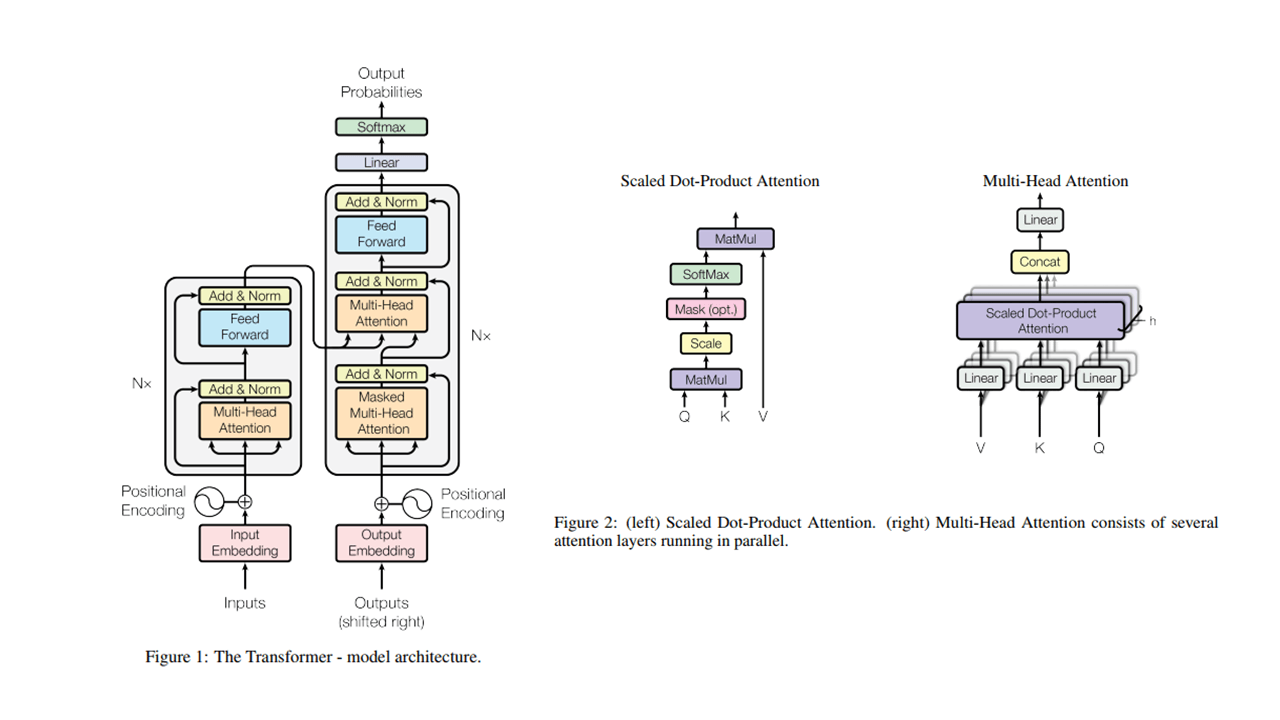
2.1.1 一段话总结
集self-attention及很多新技术为一体的特征抽取模型,特征结合的非常自然,且并行化程度极高。刚提出时是用于机器翻译的Encoder-Decoder结构,后面Encoder和Decoder都有单独被人拿出来做研究,且不断刷榜。目前在神经机器翻译已完成统治,20年在CV领域也大放异彩,21年竟然刷到了GAN的SOTA
2.1.2 模型源码
- attention-is-all-you-need-pytorch - jadore801120 (pytorch版本,首推,无其他冗余代码)
- The Annotated Transformer - harvardnlp (pytorch版本,哈佛大学,有较多注释, 附中文版)
- tensor2tensor - tensorflow (tensorflow版本,官方实现,有较多冗余代码)
2.1.3 优质文章索引
了解篇(先读论文再阅读):
- The Illustrated Transformer - Jay Alammar (首推,以图像形式详细介绍了计算细节,例如block中的$QKV$矩阵运算、多头、前馈部分,附中文版)
- Dissecting BERT Part 1: The Encoder - Miguel Romero Calvo (推荐,也是编码器部分,但较上一篇更严谨,展示了维度的变化,并给出更多真实的矩阵示例)
- Dissecting BERT Appendix: The Decoder - Miguel Romero Calvo (必读,详细介绍了前两篇很少提及的解码器部分,包括sequence mask、编码器与解码器间的attention、src_length与tgt_length转换)
- 几篇对位置编码作用的分析1, 2, 3(中文)
深入篇(复现时阅读有奇效):
- Transformer Details Not Described in The Paper (论文发布后,官方代码其实有不少改动,在此文章中能找到很多答案。附中文版)
2.2 GPT
2.3 Bert
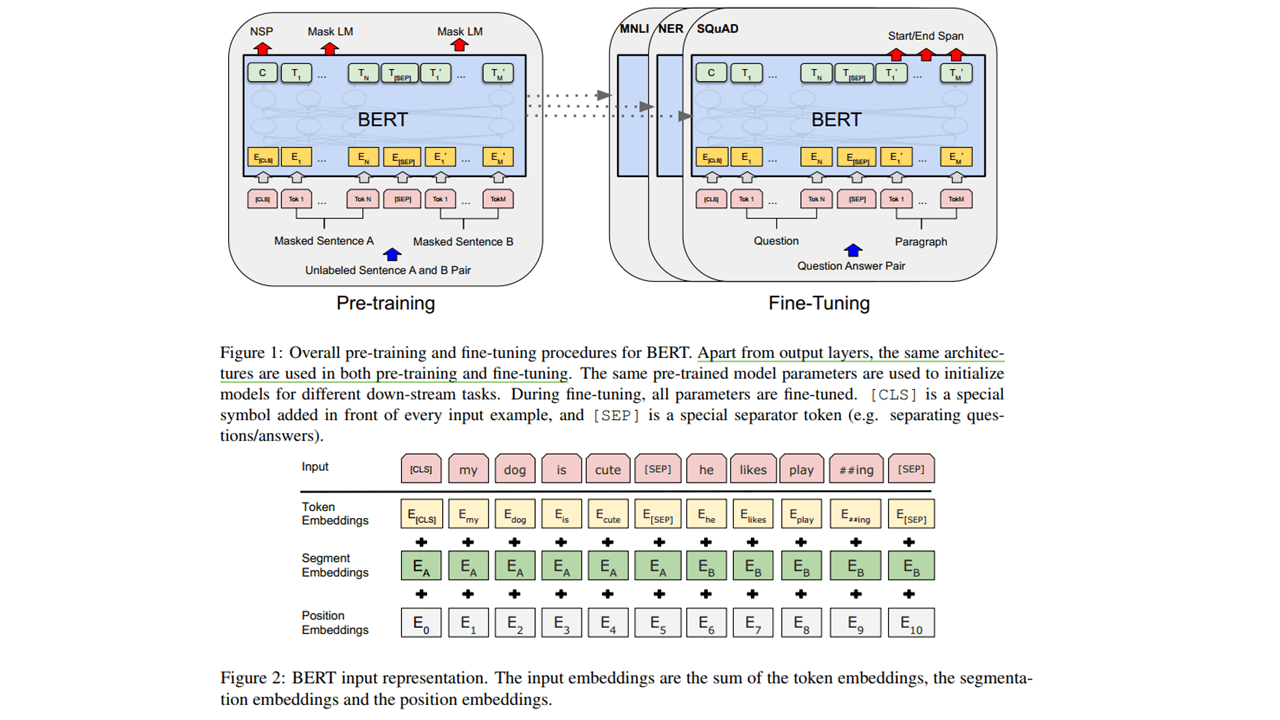
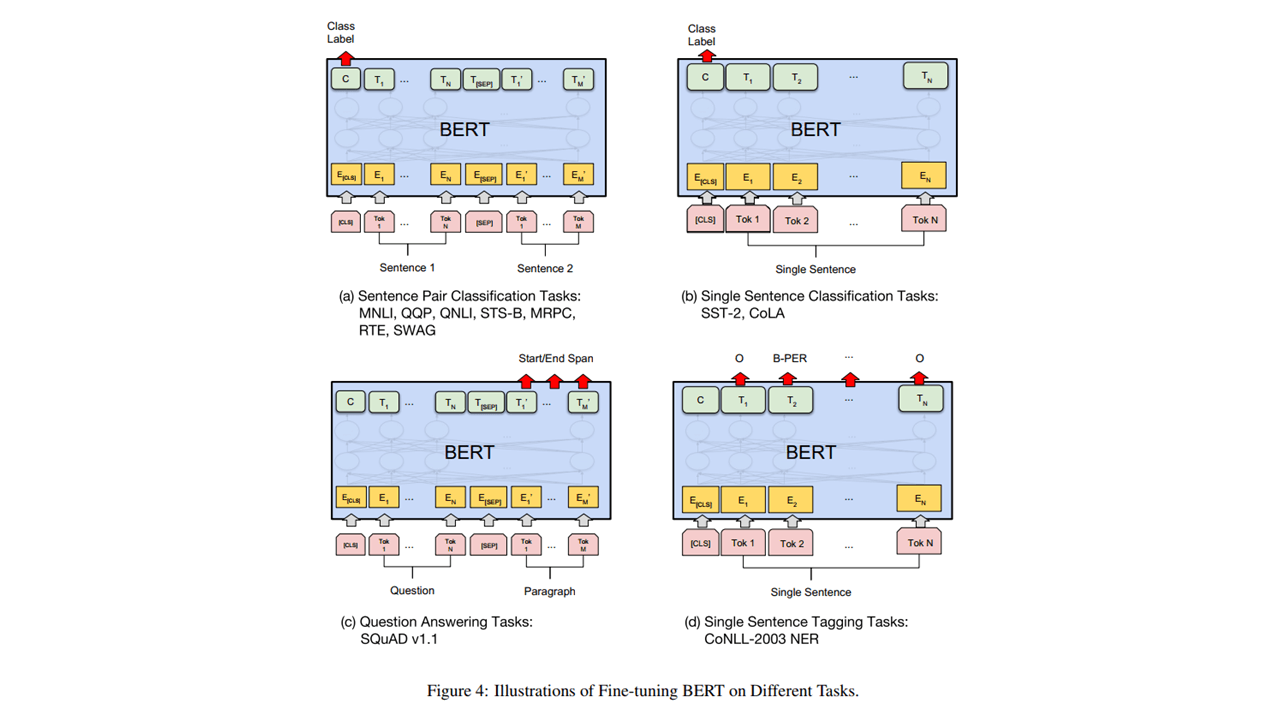
2.3.1 一段话总结
2.3.2 模型源码
- BERT-pytorch - codertimo (pytorch版本,首推)
- bert - google-research (tensorflow版本,官方实现,附源码解析1,2)
2.3.3 优质文章索引
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) - Jay Alammar (首推,站在NLP中Transfer Learning的角度,对比了ELMo,GPT等模型,重点讲解Bert,风格偏图像)
- Understanding BERT Part 2: BERT Specifics - Francisco Ingham (推荐,文中除Bert的训练细节外,还有很多自问自答、与GPT的对比、实验,便于更清楚的了解Bert)
- 一文读懂BERT(原理篇) - 废柴当自强 (推荐,一篇集大成的中文文章,引用了前几篇文章的很多内容,但总结的非常全面,涵盖了之前很少展开讲的层归一化、padding mask等,以及两种mask的结合方式)
其他优质文章
- 从word2vec开始,说下GPT庞大的家族系谱 (背景宏大的一篇文章,内容如标题)
- Attention? Attention! - Lilian Weng (一篇主要注意力机制的文章)
- 《Attention is All You Need》浅读(简介+代码)- 苏剑林 (作者是大神)
- TRANSFORMERS FROM SCRATCH (类似哈佛的文章,讲解+代码,附中文版)
- 碎碎念:Transformer的细枝末节 - 小莲子 (一个很有趣的小姐姐对Transformer的深入思考)
- 关于BERT的若干问题整理记录 - Adherer (如题目所说)
- Bert时代的创新(应用篇):Bert在NLP各领域的应用进展 - 张俊林 (关于Bert的应用的文章,作者非常有洞察力)