背景
集成学习是一种联合多个学习器进行协同决策的机器学习方法,通过整合多个学习器的决策结果可以有效减小预测结果的方差与偏置,显著提升模型的泛化能力,达到比单学习器更好的效果。对于神经机器翻译中的集成学习,实验室李北师兄的论文《On Ensemble Learning of Neural Machine Translation》针对NMT中的模型集成进行了大量的实验对比。本人也在不同规模的数据集上进行了尝试,将经验总结如下。
1 NMT中的模型集成方法
在模型层面,有模型参数平均和预测结果融合两种方法,两种方法相对独立,可以先做单个模型的检查点平均,再做不同模型的融合,都会带来提升。在数据层面,也可以通过finetuning和bagging两种策略构造子模型,这里暂不提及。
1.1 模型参数平均
即将单一模型最近保存的N个检查点的参数矩阵进行平均。
在fairseq中,可以通过以下工具实现:
python ~/fairseq/scripts/average_checkpoints.py \
--inputs ckpts_dir --output ensemble_ckpt_path \
--num-epoch-checkpoints N --checkpoint-upper-bound U
有几个问题:
- 平均多少个检查点最好?这个需要自己尝试,基本就是5、10、15、20,很容易找到最适合的。
- 这些检查点保存的方式和间隔是多少?这与数据集的规模有关。大规模数据集(一般>2M)训练到最后会比较稳定,所以直接按照epoch保存,取最后的N个检查点即可。小规模数据集(一般10w-100w)训练到最后会出现过拟合,训练到一定程度后验证集ppl会不降反升。这里就需要更频繁的保存检查点,或者根据step,或者根据时间(Vaswani等建议每隔10分钟保存一次模型)。
1.2 预测结果融合
即在解码过程中,在经过Softmax得到归一化的目标语言词表上的概率分布后,整合不同模型得到的概率分布,进而预测下一个词。
由于不需要参数平均,那么模型的结构就不需要一致,这里又有两种手段构造子模型:
- 使用相同模型结构,不同的参数初始化分布或不同的随机初始化种子
- 使用不同的模型结构
在fairseq中,可以通过以下方式实现:
使用fairseq-generate和fairseq-interactive命令,传递--path模型地址时,
将多个模型的路径用:连接在一起。例:--path model1.pt:model2.pt
注意:
- 这些模型需要共享一个词表,也就是data-bin目录
- 由于要同时加载多个模型,所以可能需要用内存更大的cpu来进行生成(参数:
--cpu)
2 实验步骤
这是师兄论文中比较关键的部分,将步骤和结果列在下面。
2.1 数据筛选
使用WMT18中英数据,平行语料16M,英文单语24M。还用了18CWMT平行语料9M。
- 对双语平行语料进行乱码过滤,剔除混有乱码的语料如控制字符、UTF-8转码生成的单字节乱码等
- 对双语平行语料进行NiuTrans分词处理,保留目标英文单词的大小写敏感,对中文端的标点符号进行全角转半角操作
- 对双语语料进行长度比过滤,过滤源语端与目标语端超过100个词的句子,同时保证源语与目标语长度比在0.4~3.0范围内
- 应用fast-align脚本对大规模双语语料做词对齐学习,在此基础上生成中英互译词典。清除源语与目标语端词典覆盖率小于0.3的双语语料
- 使用过滤后的双语语料的英文单语训练语言模型,根据语言模型筛选提供的英文单语语料,通过back-translation方式生成伪数据,用作数据增强
- 混合筛选的双语平行语料与生成的伪数据,做去重操作
筛选后,保留了12M的平行语料,4M的伪数据。对训练集进行BPE处理,BPE词表大小为32K,源语端训练词表大小为48K,目标端训练词表大小为33K
2.2 实验结果
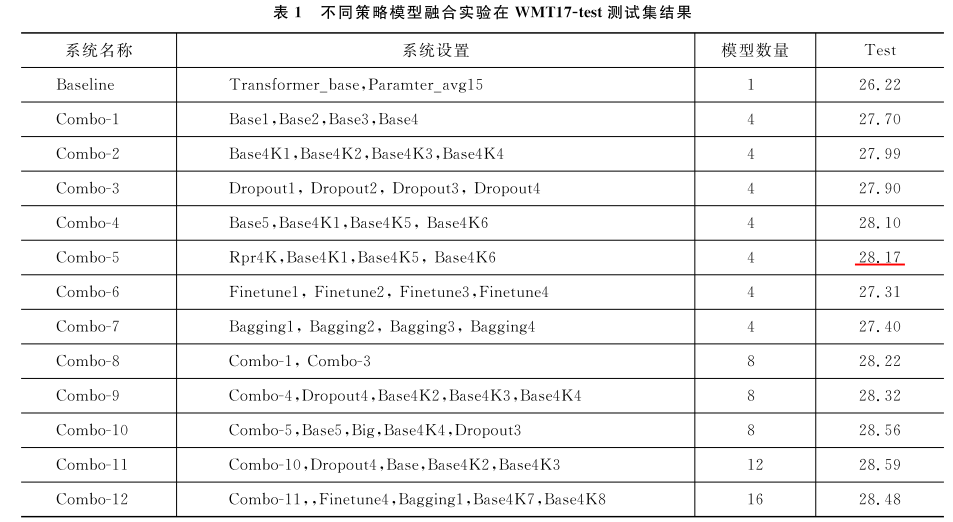
下表中的Baseline是未参数平均的模型,其余模型均是平均了15个检查点的模型
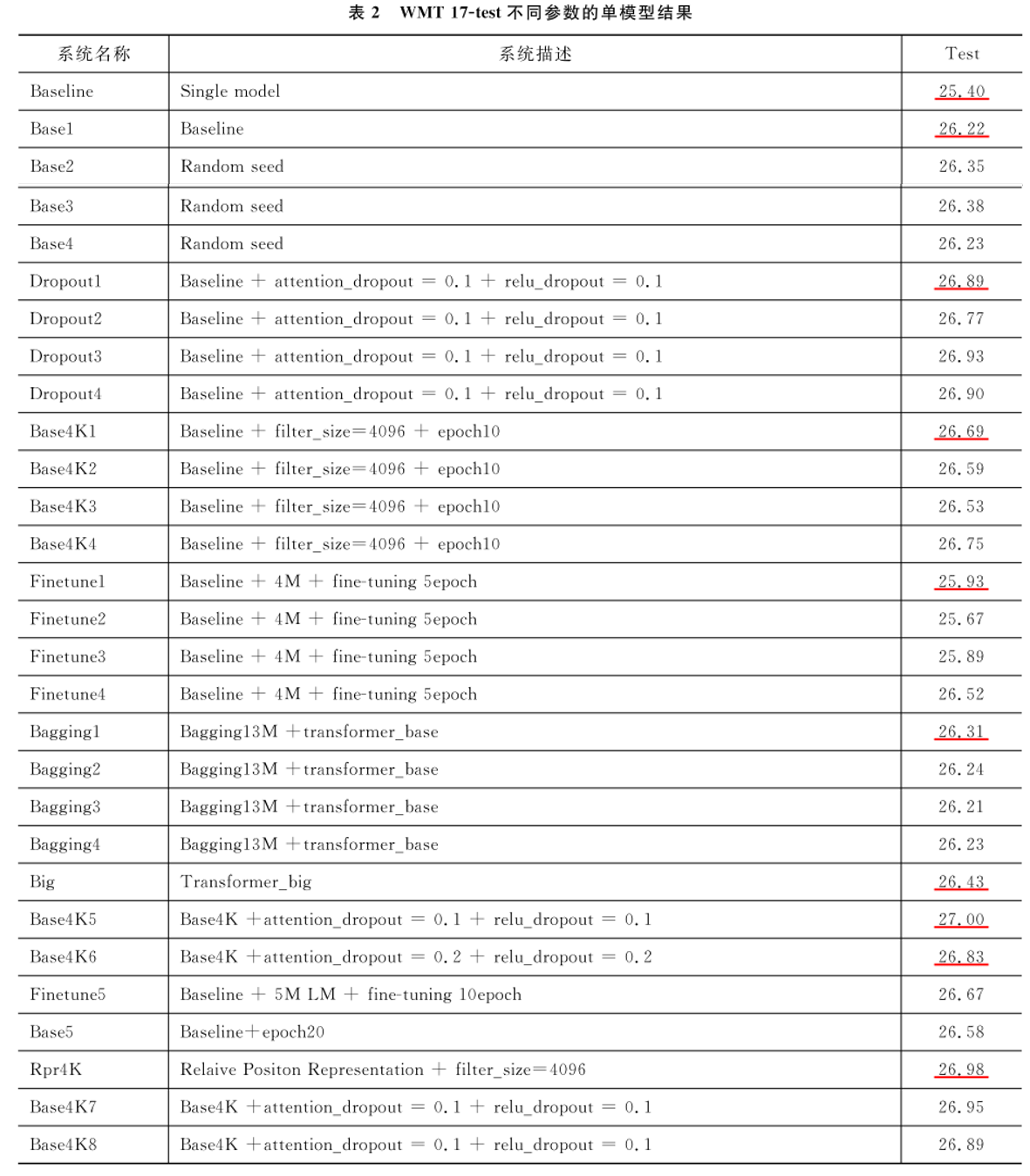
下表中是多模型融合的结果