Jiaheng Liu∗,†, Dawei Zhu∗,†, Zhiqi Bai★, Yancheng He★, Huanxuan Liao★, Haoran Que★, Zekun Wang★, Chenchen Zhang★, Ge Zhang★, Jiebin Zhang★, Yuanxing Zhang★, Zhuo Chen, Hangyu Guo, Shilong Li, Ziqiang Liu, Yong Shan, Yifan Song, Jiayi Tian, Wenhao Wu, Zhejian Zhou, Ruijie Zhu, Junlan Feng, Yang Gao, Shizhu He, Zhoujun Li, Tianyu Liu, Fanyu Meng, Wenbo Su, Yingshui Tan, Zili Wang, Jian Yang, Wei Ye, Bo Zheng, Wangchunshu Zhou, Wenhao Huang†, Sujian Li†, Zhaoxiang Zhang†
所属机构: NJU, PKU, CASIA, Alibaba, ByteDance, Tencent, Kuaishou, M-A-P
摘要
在自然语言处理领域,高效处理长上下文一直是一个持续的追求。随着长文档、长对话和其他文本数据的日益增多,开发能够有效且高效地处理和分析大量输入的长上下文语言模型 (LCLMs) 变得至关重要。在本文中,我们对大型语言模型在长上下文建模方面的最新进展进行了一次全面的综述。我们的综述围绕三个关键方面展开:如何获得有效且高效的LCLMs,如何高效地训练和部署LCLMs,以及如何全面地评估和分析LCLMs。对于第一个方面,我们讨论了面向长上下文处理的数据策略、架构设计和工作流方法。对于第二个方面,我们详细考察了LCLM训练和推理所需的基础设施。对于第三个方面,我们提出了长上下文理解和长格式生成的评估范式,以及LCLMs的行为分析和机理可解释性。除了这三个关键方面,我们还深入探讨了现有LCLMs已经部署的各种应用场景,并勾勒了有前景的未来发展方向。本综述提供了关于长上下文LLMs文献的最新回顾,我们希望它能成为研究人员和工程师的宝贵资源。一个收集了最新论文和代码库的相关GitHub仓库可在以下地址找到:LCLM-Horizon。
图 1. 长上下文处理随时间的演变。LCLMs 的出现可以在几分钟内高效处理数百万的数据,并解锁了各种有趣的应用。
* 项目负责人 (同等贡献). ★ 核心贡献者 (同等贡献). † 通讯作者.
arXiv:2503.17407v1 [cs.CL] 20 Mar 2025
1. 引言
高效的数据处理长期以来一直是人类的夙愿,因为我们的生物学限制使我们只能进行局部、串行的阅读,导致手动处理长上下文数据效率极其低下。如图1所示,回顾这些历史时刻:公元前300年,亚历山大图书馆的图书管理员必须手动抄写、校对和编纂目录,以管理数十万册古代文献[553]。在800年代,唐朝的天文官员需要手动处理大量的天文测量数据来计算节气[554]。在1400年代,排字工人在报纸印刷前必须手动排列大量的印版[552]。即使到了1900年代,学者们仍然需要在一头扎进一个课题之前,仔细研究数十甚至数百份相关文件,才能获得全面的理解。
随着语言模型[42, 108, 197, 312, 320, 503, 546, 566, 599, 600, 633, 635]的出现,一场革命性的飞跃终于到来,它们带来了在几分钟内自动处理文本数据的希望。这些语言模型在一个固定的上下文窗口内运作,通过概率建模输入序列并进行下一个词元的预测。早期的语言模型仅能处理几个或几十个词元[36, 61, 362, 445]。随着上下文长度扩展到几百或几千个词元,以BERT[101]和GPT-3[37]为代表,自动处理段落、文档和多轮对话首次成为可能。在这些进步的基础上,近年来我们见证了长上下文语言模型(LCLMs)的诞生,其上下文长度从4K呈指数级增长到128K[154]、1M[596]甚至10M[499]词元,使得单次处理托尔斯泰规模的小说(56万词)成为可能,并将人类需要60小时的阅读时间有效压缩到几分钟的计算处理中。更重要的是,这些扩展的上下文长度为测试时扩展(test-time scaling)[164, 386]提供了充足的空间,模型可以在单个上下文中进行探索、反思、回溯和总结,这从根本上改变了我们与生成式AI的互动方式,并解锁了一系列引人入胜的能力,包括:o1-like长推理[164, 373, 386]、复杂的Agent工作流[506]、卓越的上下文学习[366, 499]、高效的信息检索与理解[262, 531],以及先进的多模态智能[507, 550]。
在本文中,我们对长上下文语言建模进行了一次全面的综述。如图2所示,我们的综述围绕以下三个关键维度展开:RQ1:如何获得有效且高效的LCLMs? RQ2:如何高效地训练和部署LCLMs? RQ3:如何全面地评估和分析LCLMs? 除了这三个关键方面,我们还深入探讨了现有LCLMs的各种应用场景。
首先,为了获得有效且高效的LCLMs(RQ1),我们回顾了数据策略(§ 2)、架构设计(§ 3)和工作流设计(§ 4)。在数据策略方面,我们详细讨论了在预训练和后训练阶段构建LCLMs的数据工程工作,包括数据选择、数据过滤、数据合成、数据混合等。在架构设计方面,我们首先考察了LCLMs常用的位置嵌入及其外推策略,然后系统地讨论了三种主要的架构设计:基于Transformer的修改、线性复杂度架构以及结合两种范式的混合方法。在此之上,我们进一步介绍了扩展单个LCLM范围的工作流设计,包括提示压缩、基于记忆的工作流、基于RAG的工作流和基于Agent的工作流。
其次,为了高效地训练和部署LCLMs(RQ2),我们全面总结了AI基础设施优化策略(§ 5)。对于训练基础设施,我们考察了I/O优化、GPU约束和内存访问优化以及通信-计算重叠优化。对于推理基础设施,我们回顾了五种高效的推理策略,包括量化、内存管理、预填充-解码分离架构、GPU-CPU并行推理和推测性解码。
第三,在有效LCLMs和高效基础设施的基础上,我们接着讨论它们的性能评估(§ 6)和分析(§ 7)(RQ3)。评估部分将长上下文能力分为两大类:长上下文理解和长格式生成。对于每个类别,我们讨论评估范式,并概述现有的基准。在分析部分,我们既包括外部性能分析(例如,有效上下文长度、PPL指标、中间丢失现象),也包括内部模型结构分析(例如,位置嵌入、注意力头、MLP层)。
最后,在第8节中,我们总结了长上下文大型语言模型(LLMs)的主要应用,包括Agent、RAG、代码、多模态任务等。在第9节中,我们为LCLMs提出了五个潜在的未来方向,包括长思维链推理、有效的长上下文扩展、高效的架构和基础设施、可靠的评估以及机理可解释性。
如表1所示,我们还将本综述与现有的关于长上下文建模的综述[106, 327, 397]进行了比较,发现现有综述通常只关注长上下文建模中的几个特定主题。相比之下,本篇全面的综述深入探讨了快速发展的LCLMs领域,并通过涵盖广泛的主题来解决上述研究问题。
总之,通过对当前长上下文语言模型现状的全面概述,本综述旨在为自然语言处理领域的研究人员、实践者和爱好者提供宝贵的资源。我们希望能阐明迄今为止取得的进展,突出剩余的挑战,并激发在这一激动人心的研究领域中未来的创新。

图 2. 长上下文语言建模技术分类图。
| 综述 | 数据 | 架构 | 工作流设计 | 基础设施 | 评估 | 分析 |
|---|---|---|---|---|---|---|
| Huang et al. [199] | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Zhao et al. [664] | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Li et al. [297] | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Dong et al. [106] | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| 本综述 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
表 1. 我们的综述与其他相关长上下文建模综述的比较。
2. 数据
在本节中,我们讨论与长上下文建模相关的数据主题。具体来说,如图3所示,长上下文数据在预训练和后训练阶段都会被使用。为了说明LCLMs的数据处理流程,我们首先介绍长上下文预训练数据(§ 2.1)的策略,包括数据过滤、数据混合和数据合成。然后,我们介绍长上下文后训练数据(§ 2.2)的策略,包括数据过滤和数据合成。

图 3. LCLMs训练流程图。
2.1 预训练
2.1.1 数据过滤
许多研究表明,基础模型的性能受到预训练数据质量的显著影响[110, 162, 421, 635],并且已经采用了各种方法来提高数据质量。具体而言,一些工作[423, 464, 635]实施了许多启发式规则(例如,移除短条目)和去重方法(例如,MinHashLSH去重[267])来改善数据质量。此外,SemDeDup[3]被提出来利用现有预训练模型的嵌入来移除语义重复项。另外,还提出了几种方法来提高数据的多样性和复杂性。例如,Maharana等人[350]将多样性和难度视为互补因素,采用带有双向消息传递的数据集图进行数据选择,而Tirumala等人[509]则应用聚类技术来扩大数据多样性。然而,上述方法主要针对标准的预训练数据集,通常限制在4000或8000个词元。最近,研究人员已经从不同角度开发了专门的标准来评估扩展上下文的质量。例如,工作[326]引入了一个评估长文本质量的综合框架,主要包括三个核心语言学方面:连贯性、衔接性和复杂性。为了量化这些方面,已经提出了包括统计测量和基于预训练语言模型的评估在内的各种指标。同时,除了Longwanjuan,另一项代表性工作[58]被提出来根据其长程依赖特性来评估训练样本。该方法还利用三个关键指标(即依赖强度、依赖距离、依赖特异性)来评估和优先选择对增强模型长上下文理解能力特别有益的样本。最近,一些工作开始使用注意力模式来选择高质量的长上下文数据。例如,LongAttn[561]使用自注意力机制来量化长程依赖,以实现准确高效的数据选择。
2.1.2 数据混合
语言模型训练通常利用来自不同来源的数据集[37, 82, 109, 132, 135]。例如,The Pile[132]是一个广泛使用的数据集,包含各种成分,包括24%的网页内容、9%的维基百科和4%的GitHub等。此外,许多工作观察到预训练数据的构成显著影响LM的性能[109, 184],而当前确定领域权重(每个来源的采样概率)的方法通常依赖于直觉或特定的下游任务。例如,The Pile采用启发式选择的权重,这可能不是最优的。PaLM[82]和GLaM[109]根据选定的下游任务微调这些权重,这需要用不同的权重配置训练大量的LMs。为了解决这个限制,Data Mixing Laws[613]和RegMix[319]研究了数据混合的缩放定律,以最小的训练成本找到最优的领域混合,从而提高预训练效率。然而,上述方法通常关注于有限上下文窗口内(例如4k/8k)的预训练数据,而一些工作已经开始关注长上下文预训练的数据混合。例如,[127]探索了五种类型的长上下文数据构成,包括“在4K处切分文档”、“在128K处切分文档”、“全局上采样”、“按来源上采样”和“上采样Arxiv/Book/Github”,并得出以下观察结果:(1)在少量长上下文数据上进行持续预训练可以显著提高7B模型在长上下文输入上准确检索信息的能力。(2)在扩展上下文长度时,过采样长序列至关重要,同时要保持预训练数据集的原始领域多样性。ProLong[135]表明,将代码库和长篇书籍作为长上下文来源,并将其与高质量的短上下文来源混合,对于提高在扩展输入上的性能至关重要,同时也能保持模型在短上下文上的熟练度。GrowLength方法[228]在整个预训练过程中逐步扩展输入大小,优化了计算资源并提高了效率。
2.1.3 数据合成
由于长上下文数据在现实世界的语料库中(如网页文档)通常很少见,许多方法被提出来合成或构建长上下文预训练数据。例如,一种方法是在单个上下文窗口内聚类语义相关的文本[166],而另一项工作[271]则通过在预训练样本中加入相关的、非相邻的句子来改善句子表示。此外,为了解决文档冗余问题,ICP[456]采用了旅行商算法。此外,SPLICE[471]涉及结构化打包,即通过组合多个相似的检索文档来创建训练样本。另外,还提出了一种以查询为中心的合成方法Quest[130],用于聚合多样化但语义上相关的文档。该方法利用生成模型为每个文档预测潜在的查询,随后根据相似的查询和关键词将文档分组。
2.2 后训练
2.2.1 数据过滤
与预训练不同,后训练中的数据过滤策略通常旨在选择有影响力的样本,以增强LLMs的指令遵循能力。Chen等人[54, 57]、Liu等人[323]、Wu等人[561]探索使用来自专有语言模型的反馈来筛选训练样本。同时,Cao等人[41]、Ge等人[141]、Li等人[281]、Xia等人[577]开发了基于开源LLMs的复杂指标来评估样本的重要性。然而,这些方法只关注选择短格式的SFT数据,忽略了长上下文对齐所带来的特定挑战。最近,GATEAU[462]引入了两个组件(即“同源模型指导”和“上下文感知测量”),以识别具有长程依赖关系的有影响力的样本。
2.2.2 数据合成
对于后训练的数据合成,我们需要有效地构建长上下文查询,许多工作已经在这方面进行了探索。例如,Ziya-Reader[175]构建了一个量身定制的多文档问答任务,要求模型关注上下文中不同位置的内容,以解决“中间丢失”问题[317]。Xiong等人[584]提出从预训练语料库中选择一个文档,并提示语言模型根据所选块中的信息编写问答对。最近,An等人[13]提出了一种信息密集型训练方法来克服中间丢失问题,该方法利用一个合成的长上下文问答数据集,包括两种类型的问题(即,对一个短片段的细粒度信息感知,以及对两个或多个片段信息的整合与推理)。Xu等人[590]提出将所有相关段落组装起来,并随机插入真实摘要,以模拟一个真实的长文档,从而获得长上下文指令。Chen等人[71]提出了多智能体交互式多跳生成(MIMG)框架,该框架包含一个质量验证智能体、一个单跳问题生成智能体、一个多问题采样策略和一个多跳问题合并智能体,以提高长上下文指令数据的质量。
最近,一些工作[493, 638]开始关注长上下文模型的偏好优化[387, 422],以使模型与人类偏好对齐。一个代表性的工作DPO[422]可以消除对独立奖励模型的需求,并教会模型以不同分配的预测分数来“拒绝”不一致的响应和“接受”偏好的响应。同时,已经做出了许多努力来增强DPO的有效性和效率,例如SimPO[358]、ORPO[185]、TPO[438]、2D-DPO[287]和Constitutional DPO[538]。然而,这些多样化的方法主要关注短上下文场景,而长上下文偏好优化被忽略了。最近,一些关于长上下文偏好优化的工作被提了出来。例如,LongReward[638]利用一个现成的LLM,从四个以人为本的维度(帮助性、逻辑性、忠实性和完整性)为长上下文模型响应提供奖励,然后基于合成的查询获得偏好对。LOGO[492]引入了使用自动评估器进行评分的重要性,以在长上下文理解场景中合成偏好(对齐)和非偏好(不对齐)数据。最近,长上下文生成引起了广泛关注,Ping等人[405]提出了LongDPO方法,该方法使用蒙特卡洛树搜索来收集逐步的偏好对,并采用步级DPO来提高现有LLMs的能力。
2.3 训练数据
长上下文预训练和后训练数据集的摘要如表2所示。
| 训练数据 | 特征 | 阶段 |
|---|---|---|
| Longwanjuan [326] | 双语,从SlimPajama[464]和Wanjuan[172]过滤 | 预训练 |
| Long-Data-Collections [2] | 多样化的数据源 | 预训练 |
| LongAttn [561] | 使用注意力模式选择的长程依赖 | 后训练 |
| LongAlign [19] | 多样的任务和来源,自指令 | 后训练 |
| FILM [13] | 信息密集,上下文长度平衡,多跳推理 | 后训练 |
| PAM QA [175] | 位置无关,多跳推理 | 后训练 |
| LongAlpaca [69] | 自收集,指令遵循 | 后训练 |
| ChatQA2 [590] | 从NarrativeQA[246]合成 | 后训练 |
| LongMIT [71] | 多跳,多样化,自动化 | 后训练 |
| LongWriter-6k [21] | 长格式生成,输出长度从2k到32k词 | 后训练 |
| Long Reward [638] | 双语,偏好优化 | 后训练 |
| LOGO [493] | 偏好优化 | 后训练 |
| LongDPO [405] | 长格式生成,偏好优化,步级 | 后训练 |
表 2. 长上下文建模训练数据集概览。
3. 架构
对于长上下文语言模型,架构设计面临双重挑战:在训练和推理阶段,既要有效处理极长的文本,又要保持计算效率。本节全面回顾了为长上下文建模量身定制的架构设计。首先,我们考察了LCLMs中常用的位置嵌入及其外推策略(§ 3.1)。然后,我们系统地讨论了三种主要的架构设计:基于Transformer的修改(§ 3.2.1)、线性复杂度架构(§ 3.2.2),以及整合两种范式的混合方法(§ 3.2.3)。
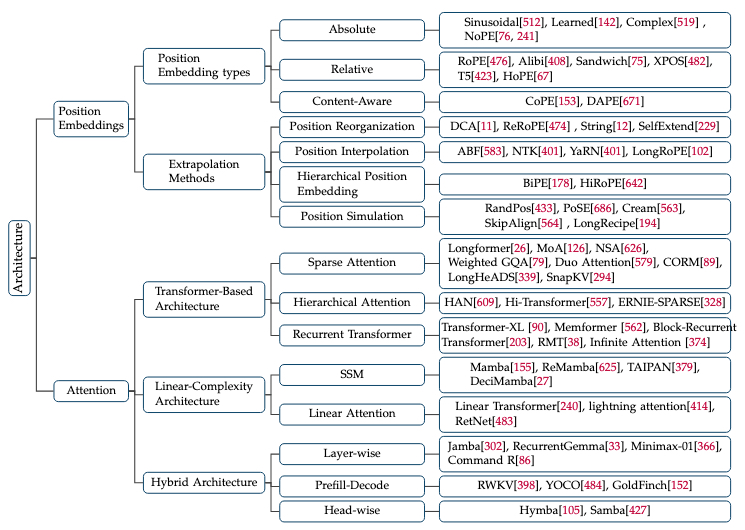
图 4. 长上下文模型架构分类图。
3.1 位置嵌入
大多数长上下文LLMs都基于流行的Transformer架构。由于Transformer并行计算所有词元的表示,因此有必要借助位置编码来整合序列中的位置信息。在本小节中,我们将首先介绍Transformer中使用的不同类型的位置嵌入,然后演示如何将位置编码调整以适应更长的序列长度。
3.1.1 位置嵌入类型
如表3所示,根据其位置信息的形式,LLMs中的位置嵌入可以分为绝对位置嵌入、相对位置嵌入和内容感知位置嵌入。
| 类别 | 位置嵌入 | 参数化 | 表示方式 | 注入方法 |
|---|---|---|---|---|
| 绝对 | Sinusoidal [512] | ✗ | Embedding | Add |
| Learned [142] | ✓ | Embedding | Add | |
| Complex [519] | ✓ | Embedding | Multiply | |
| NoPE [76, 241] | ✗ | NA | NA | |
| 相对 | Relative Position [451] | ✓ | Embedding | Add |
| T5 [423] | ✓ | Bias | Add | |
| Alibi [408] | ✗ | Bias | Add | |
| Kerple [74] | ✓ | Bias | Add | |
| Sandwich [75] | ✗ | Embedding | Add | |
| FIRE [285] | ✓ | Bias | Add | |
| RoPE [476] | ✗ | Embedding | Multiply | |
| XPOS [482] | ✗ | Embedding | Multiply | |
| HoPE [67] | ✗ | Embedding | Multiply | |
| 内容感知 | CoPE [153] | ✓ | Embedding | Add |
| DAPE [670, 671] | ✓ | Bias | Add |
表 3. Transformer架构中位置嵌入的概览。
绝对位置嵌入 绝对位置嵌入为序列中的每个词元提供其绝对位置信息。这种方法可分为三种类型:(1)通过函数式方法直接为每个位置指定位置嵌入(PE);(2)将每个位置的PE设为可训练的向量,在训练过程中更新;(3)完全省略位置嵌入,依赖于解码器-仅架构中的单向注意力来隐式学习位置。具体如下:
- 函数式位置嵌入 [512]。函数式位置嵌入最典型的例子是正弦位置嵌入,由原始Transformer[512]提出,并广泛用于基于Transformer的变体模型中。它通过周期性的正弦和余弦函数来编码位置信息。在Transformer中,它通常与词嵌入相加,以向网络注入绝对位置信息。
- 学习式位置嵌入 [142]。它最初由Meta提出,用于将位置信息引入卷积序列到序列学习中。不同位置的嵌入表示被视为可学习的参数,并与网络一起训练。这在BERT[101]、GPT[37]和OPT[647]等模型中广泛使用。还有一些变体[519]在复平面中表示位置嵌入,并将其与同样在复向量中表示的连续词嵌入相结合。
- 无位置嵌入 (NoPE) [76, 241]。NoPE提出在Transformer中不加入显式的位置编码。研究发现模型仍然能学习到词元的排列顺序。NoPE在语言建模和一些探测任务中也是有效的。[76]证明了在因果语言模型中的NoPE可以融入隐式的绝对位置信息。注意,NoPE也传达了相对位置信息[241]。
相对位置嵌入 与关注绝对位置信息不同,相对位置嵌入[451]捕捉词元之间的相对距离,因为它假设相对位置信息对语言理解更为关键。对于LCLMs,常用的相对位置嵌入可分为以下三种类型:
- T5-风格 [423]。T5最初将位置i和j的词元之间的相对距离$(i-j)$映射到一个标量偏置值 $b = f(i-j)$,其中$f$代表一个查找表。随后,在自注意力机制中,将相对偏置$b$(在训练过程中学习)加入到查询和键的点积中。该查找表对超过某个阈值的距离分配相同的参数,从而有助于泛化到未见过的距离。基于T5的位置嵌入,FIRE[285]提出将位置表示映射为一个可学习的函数。为了解决测试长度变化时的长度泛化问题,FIRE通过查询位置索引对距离进行归一化,实现了渐进式插值。通过这种方式,FIRE可以将任何测试长度映射到训练范围内。
- ALiBi [408]及其变体。ALiBi,在BLOOM[439]和Baichuan[595]中采用,与T5的位置编码相似。但不同之处在于它从注意力分数中减去一个标量偏置。这个偏置与查询和键词元之间的距离成线性比例增加。因此,这实际上产生了一种对位置更近的词元的偏好,这被称为新近度偏置。Alibi可以公式化为: \(\mathbf{q}_i \mathbf{k}_j^T = (\mathbf{x}_i \mathbf{W}_q)(\mathbf{x}_j \mathbf{W}_k)^T + m(i-j) \quad (1)\) 其中 $m$ 是一个与头相关的标量超参数。$i$ 和 $j$ 表示查询q和键k的位置索引。$W_q$ 和 $W_k$ 表示注意力中的投影层。在ALiBi的基础上,Kerple[74]引入了两个可训练参数以实现更好的长度外推,而Sandwich[75]则简化了正弦位置嵌入的形式,仅考虑位置嵌入的交叉项,以减轻正弦位置嵌入的过拟合问题。
- 旋转位置嵌入 (RoPE) [476]及其变体。RoPE在进行点积注意力之前,通过一个与它们的绝对位置成比例的角度来旋转查询和键的表示。由于这种旋转,注意力点积将仅依赖于词元之间的相对距离,从而有效地将其转换为相对位置编码。为了说明,给定一个隐藏向量 $\mathbf{h} = [h_0, h_1, …, h_{d-1}]$,其中 $d$ 是隐藏维度,以及一个位置索引 $m$,RoPE操作如下: \(f(\mathbf{h}, m) = \begin{pmatrix} h_0 \\ h_1 \\ h_2 \\ h_3 \\ \vdots \\ h_{d-2} \\ h_{d-1} \end{pmatrix} \otimes \begin{pmatrix} \cos m\theta_0 \\ \cos m\theta_0 \\ \cos m\theta_1 \\ \cos m\theta_1 \\ \vdots \\ \cos m\theta_{d/2-1} \\ \cos m\theta_{d/2-1} \end{pmatrix} + \begin{pmatrix} -h_1 \\ h_0 \\ -h_3 \\ h_2 \\ \vdots \\ -h_{d-1} \\ h_{d-2} \end{pmatrix} \otimes \begin{pmatrix} \sin m\theta_0 \\ \sin m\theta_0 \\ \sin m\theta_1 \\ \sin m\theta_1 \\ \vdots \\ \sin m\theta_{d/2-1} \\ \sin m\theta_{d/2-1} \end{pmatrix} \quad (2)\) 其中 $\theta_j = 10000^{-2j/d}, j \in {0, 1, …, d/2 - 1}$。给定位置 $m$ 的查询 $\mathbf{q}$ 和位置 $n$ 的键 $\mathbf{k}$,注意力分数 $a(\mathbf{q}, \mathbf{k})$ 定义为: \(\begin{aligned} a(\mathbf{q}, \mathbf{k}) &= <f(\mathbf{q}, m), f(\mathbf{k}, n)> \\ &= \sum_{i=0}^{d/2-1} [(q_{2i}k_{2i} + q_{2i+1}k_{2i+1})\cos(m-n)\theta_i + (q_{2i}k_{2i+1} - q_{2i+1}k_{2i})\sin(m-n)\theta_i] \\ &:= g(\mathbf{q}, \mathbf{k}, (m-n)\theta) \quad (3) \end{aligned}\) 其中 $g(\cdot)$ 是一个仅依赖于 $\mathbf{q}, \mathbf{k}$ 和 $(m-n)\theta$ 的抽象映射函数。受益于这种良好特性,RoPE成为LLMs时代最普遍的位置嵌入策略,包括LLaMA[510]、Qwen[596]等。Sun等人[482]认为RoPE的外推能力较弱与其注意力期望中的显著振荡有关。为解决此问题,他们提出了XPOS,该方法加入了一个平衡项来惩罚不稳定维度的振荡,同时保持稳定维度的分布。同样基于RoPE的基础,HoPE[67]通过用与位置无关的成分替换特定成分,同时仅保留高频信号,来增强长度外推能力。
内容感知位置嵌入 最近,对内容感知位置嵌入[153, 671]的兴趣日益增长,它认为位置测量应考虑更具语义意义的单位,如单词或句子,如下所示:
- CoPE [153]。CoPE通过利用词元的内容及其在序列中的位置来联合建模内容和位置信息。具体来说,CoPE首先计算依赖于上下文的门控值,然后利用这些值通过累加求和过程来确定词元位置。通过这种方式,位置嵌入被赋予了上下文信息。
- DAPE [670, 671]。它提出用注意力机制动态地建模位置信息。具体来说,DAPE不仅根据位置索引,还根据语义信息来确定位置偏置。通过这种方式,DAPE克服了不灵活性,并通过在每个特定输入数据上动态调整,为每个单独的实例实现了相对最优的性能。
3.1.2 位置嵌入的外推方法
对于一个原始上下文窗口大小为 $L_{orig}$ 的语言模型,当处理长度为 $L_{target}$(缩放因子 $s = L_{target}/L_{orig}$)且超过此范围的目标序列时,第一个挑战是位置编码的分布外(OOD)问题,因为 $L_{orig}$ 的位置编码无法覆盖更大的范围。正如LM-Infinite[168]中提到的,位置编码OOD是阻碍长度外推的一个重要因素。从避免分布外位置的角度看,基于位置编码的长度外推策略主要可分为两类:(1)将目标序列映射到模型支持的位置范围内,以及(2)使模型能够支持比上下文窗口更大的位置范围。值得注意的是,第一类中的大多数方法可以在没有额外调整的情况下表现良好,而第二类中的设计通常依赖于训练才能生效。
| 直觉 | 方法 | 免训练 |
|---|---|---|
| 位置重组 | SelfExtend [229] | ✓ |
| DCA [11] | ✓ | |
| ReRoPE [474] | ✓ | |
| String [12] | ✓ | |
| 位置插值 | PI [60] | ✓ |
| NTK [401] | ✓ | |
| ABF [583] | ✓ | |
| YaRN [401] | ✓ | |
| Truncated Basis [389] | ✓ | |
| CLEX [49] | ✗ | |
| Resonance RoPE [537] | ✗ | |
| LongRoPE [102] | ✗ | |
| MsPoE [659] | ✓ | |
| 层级位置 | BiPE [178] | ✗ |
| HiRoPE [642] | ✓ | |
| 位置模拟 | RandomPE [433] | ✗ |
| PoSE [686] | ✗ | |
| SkipAlign [564] | ✗ | |
| Cream [563] | ✗ | |
| LongRecipe [194] | ✗ |
表 4. RoPE长度泛化的变体。
将目标序列映射到模型支持的位置范围可以进一步分为两条路线:
- 位置重组:这种方法重组,特别是重用,在训练中出现过的位置索引来处理超过训练长度的输入。这种重组位置索引的思想在T5模型[423]中已有体现,它支持512个词元的输入,但只包含32种类型的相对位置。对于使用RoPE编码的主流大型语言模型,可以应用类似的方法。在SelfExtend[679]中,对于每个词元,最近的$w$个词元保持正常的相对位置,而远处的词元则被分组。DCA[11]遵循类似的方法。ReRoPE[474]使得超出窗口$w$的相对位置以较小的间隔增加。此外,String[12]发现,即使在模型支持的位置范围内,它在较短的相对位置上表现也更好,因此更广泛地利用了训练良好的位置。
- 位置插值:与重用现有位置不同,位置插值选择单调地缩小所有输入词元的位置索引,以不超过最大训练值。最早提出的插值策略是线性插值,它直接将每个词元的位置索引$m$缩放为$m/s$[60]。在RoPE位置编码下,这等同于统一减小角度$\theta$。根据神经正切核理论[209],这种方法可能会阻止模型学习高频特征。为了解决这个问题,NTK插值[401],也称为ABF[583],减小了高频部分的缩放比例,同时增加了低频部分的缩放比例。在实践中,NTK插值直接将原始的$\theta_j = 10000^{-2j/d}$调整为$\theta’_j = (10000s)^{-2j/d}$,其中$s$通常选择比$\lambda$稍大。YaRN[401]发现使用斜坡函数在不同维度上以不同比例执行NTK插值可以获得更好的结果。在YaRN的基础上,Resonance RoPE[537]使用整数波长进一步优化了RoPE的特征。LongRoPE[102]直接使用进化搜索为每个维度找到最优的频率缩放参数。一些工作探索了为不同的注意力头[659]或层[66]分配不同的缩放因子,以提高模型在长上下文任务上的性能。除了基于RoPE的外推方法,一些研究人员也已将线性和NTK插值技术应用于ALiBi[1, 8]。
另一方面,使模型能够支持大于上下文窗口大小的位置范围主要通过两种方法实现:
- 层级位置嵌入:类似于数字系统,这种方法通过在位置编码中引入层级结构来大大增加可表示的范围。BiPE[178]引入了一个两层的位置编码系统,负责建模段内和段间的位置。HiRoPE[642]专注于代码场景,利用代码的自然层级结构,使用RoPE的较低$d/2$维度和较高$d/2$维度分别处理词元级和函数级的距离。
- 位置模拟:有趣的是,有一条研究路线探索使用短的训练数据来模拟长的训练数据,从而有效地将训练长度与推理长度解耦。RandPos[433]从一个更长的位置序列中随机采样一组位置,按升序排序,并用它们作为较短输入数据的位置索引。使用这种方法训练的编码器展示了优越的长度外推能力。对于LLMs,Zhu等人[686]提出了PoSE,它将原始上下文窗口划分为几个块,确保块内的位置索引是连续的,同时允许块之间有跳跃,从而用一个较短的上下文窗口覆盖更长的相对位置。CREAM[563]、LongRecipe[194]和SkipAlign[564]在PoSE的基础上做了进一步的改进。具体来说,CREAM采用高斯采样等策略来优化文本块的划分,增强了位置索引的连续性和相对性。LongRecipe类似地优化了PoSE的文本块划分,并引入“有影响力的词元分析”来选择每个块内的填充文本内容。SkipAlign根据具体的指令调整需求确定块大小和位置索引跳跃率,在LongBench上实现了与GPT-3.5-Turbo-16k相当的性能。
3.2 注意力机制
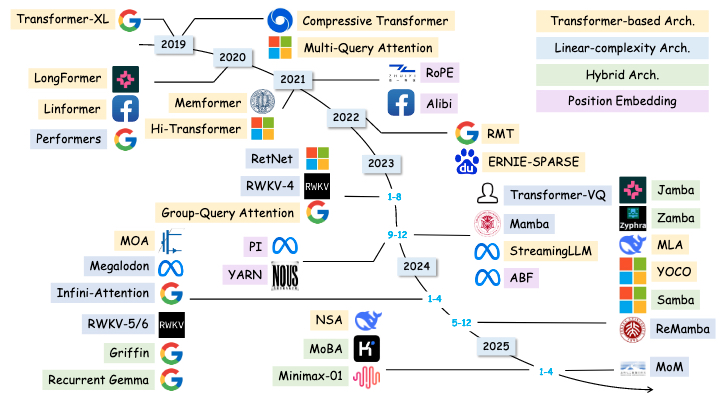
图 5. 不同模型架构的演变图。
3.2.1 基于Transformer的架构
主流的大型语言模型基于Transformer架构[512]。具体来说,这种架构由多个堆叠的Transformer层组成,每个层由多头自注意力(MHSA)、前馈网络(FFNs)和层归一化(LN)组成。每一层接收前一层的输出作为输入,并将其自身的输出传递给下一层。经典的配置包括仅编码器架构,如BERT[100]和GLM[112],用于编码模型;仅解码器结构,如GPT[37]和LLaMA[510],用于生成模型;以及编码器-解码器框架,如T5,用于序列到序列建模。核心的自注意力[512]机制如下: \(\text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V, \quad (4)\) 其中 $Q \in \mathbb{R}^{n \times d_k}, K \in \mathbb{R}^{n \times d_k}, V \in \mathbb{R}^{n \times d_v}$。$QK^T$ 的时间复杂度是 $O(n^2)$。
由于Transformer架构中MHSA组件固有的二次计算复杂性,大多数基于Transformer的模型在处理长文本时都面临长度和效率方面的限制,这对有效训练和推理构成了挑战。因此,出现了各种增强Transformer结构的方法,主要集中在注意力机制的改进和整体架构的修改上。本章的以下部分将描述这些方法,包括稀疏注意力、层级注意力、循环Transformer和效率驱动的修改。
稀疏注意力 为了解决基于Transformer的模型中注意力的二次复杂性问题,以及长上下文场景中极大的KV缓存带来的挑战,许多先前的工作探索了稀疏注意力机制,它减少了计算和内存开销,为真实世界的应用实现了更快的处理和更好的可扩展性。稀疏注意力可以大致分为基于训练和免训练的方法,取决于它是在训练期间还是在推理期间应用。
对于基于训练的方法,稀疏性主要体现在两个方面:头维度(例如,分组查询注意力)和上下文窗口维度(例如,滑动窗口注意力)。头维度稀疏注意力中最常见的功能是分组查询注意力(GQA)[7]。分组查询注意力将查询头组织成 $G$ 个不同的组,每个组利用一个共享的键头和值头。当 $G=1$ 时,GQA只有一个组,一个键和一个值头,这与多查询注意力(MQA)相当。当 $G=H$(组数 $G$ 等于头数 $H$)时,MQA类似于标准的多头注意力(MHA)。加权分组查询注意力[79]为注意力块中的每个键和值头添加了新的可学习参数,以实现这些键和值头之间的聚合。注意力混合(MoA)[126]为不同的头和层自动定制不同的稀疏注意力配置,其中MoA构建并导航了一个包含各种注意力模式及其相对于输入序列长度的缩放规则的搜索空间。
随着上下文长度的增长,上下文窗口维度的稀疏性可以有效地减少由长度增加引起的额外计算,并捕获有效信息[270, 340, 536]。Beltagy等人[25]引入了Longformer,其注意力机制与序列长度成线性比例,可以处理数千词元的文档。Zebra[466]在训练和推理阶段将局部-全局注意力层分组为块。Xiao等人[581]发现保留初始词元的KV将大大恢复窗口注意力的性能,这些初始词元虽然缺乏有意义的语义,但吸引了大量的注意力分数。Gao等人[136]采用一种完全基于学习的方法,在LLMs中自适应地识别注意力稀疏性,并利用学习到的稀疏性进行高效推理。最近,遵循专家混合(MoE)的原则,MoBA[335]被提出来,其中引入了可训练的块稀疏注意力和无参数的门控机制。
然而,大多数先前的方法需要从头开始训练模型,这限制了它们作为现成大型语言模型直接插件的可用性。一些免训练的稀疏注意力方法如下:
- 静态策略。已经提出了多种方法来在推理期间提高效率同时保持性能。窗口注意力[25, 78, 214]在最近的词元的KV状态上维持一个固定大小的滑动窗口,确保了效率,但一旦初始词元被驱逐,性能就会下降。StreamingLLM[581]通过识别“注意力汇点”(attention sinks)来缓解此问题,其中初始词元通常接收到不成比例的高注意力分数,使得在有限注意力窗口上训练的LLMs能够处理无限长度的序列而无需微调。LM-Infinite[168]设计了一个Λ形的注意力掩码和注意力距离的上限,使得LLMs能够在没有任何参数更新的情况下泛化到极端的序列长度。
- 动态策略。与之前依赖静态、固定窗口策略的方法不同,后来的方法采用动态策略来选择和保留最重要的词元。H2O[658]使用累积的注意力分数仅保留KV缓存中的“重度命中者”(Heavy Hitters)词元。类似地,Scissorhands[331]根据“重要性持久性假设”优先考虑重要的词元。CORM[89]是一个KV缓存驱逐策略,可以在没有模型微调的情况下动态保留重要的键值对以进行推理。SnapKV[294]通过利用注意力分数来识别和聚类重要词元来提高效率。FastGen[139]识别了几种基本的注意力模式,并引入了一种自适应的KV缓存驱逐策略。MInference[217]使用带有空间聚合模式的动态稀疏注意力加速预填充阶段,允许无缝集成到现有的LLMs中。Quest[491]是一个查询感知的KV缓存选择算法,它在KV缓存页中跟踪最小和最大的键和值。
- 层级优化。大多数前述方法在所有层上采用相同的策略来减少KV缓存,忽略了不同层信息处理的重要性差异。PyramidKV[40]和PyramidInfer[598]发现LLMs通过一个金字塔形的信息漏斗来聚合信息,并动态地调整不同层的KV缓存大小,为较低层分配更多的KV缓存,为较高层分配较少的KV缓存。LazyLLM[125]在每个生成步骤中应用层级词元剪枝。DynamicKV[684]通过调整每层保留的词元数量来动态优化词元保留,以更好地适应特定任务。Light-Transfer[654]通过选择性地从识别出的懒惰层中移除缓存,来最小化层间KV缓存的冗余。TidalDecode[603]通过位置持久的稀疏注意力加速LLM解码。
- 头级优化。先前的工作没有关注不同头之间注意力模式的差异。RazorAttention[490]和DuoAttention[579]通过将注意力头分为检索头(需要完整的KV缓存)和非检索头(只需要固定大小的KV缓存)来显著提高长上下文效率,这大大减少了内存消耗,并在提高解码和预填充速度的同时保持了准确性。AdaKV[124]自适应地在注意力头之间分配KV缓存预算,以优化缓存驱逐策略。HeadKV[128]结合了检索头的识别,引入了一种新的自适应预算分配策略,为每个注意力头单独全局分配预算。LONGHEADS[339]将序列上下文分成块,每个注意力头关注块的一部分。在生成特定词元时,LONGHEADS根据其查询向量和块表示选择与当前词元最相关的$k$个块。
- 其他方法。尽管取得了这些进展,但许多方法由于激进的词元剪枝而遭受永久性信息丢失。Loki[463]是一种基于PCA的稀疏注意力机制,通过利用注意力块中键向量的低维性,实现了推理加速并保持了效能。
稀疏注意力方法在降低基于Transformer模型的计算成本方面显示出有希望的结果,通过将注意力的范围限制在词元的一个子集上,从而实现了更快的处理和更好的可扩展性。然而,这些技术通常涉及权衡,特别是在维护重要的上下文信息方面。虽然效率至关重要,但保留输入序列的关键元素对于性能至关重要,尤其是在涉及长上下文推理的任务中。为了解决这个问题,未来的研究应该集中在开发自适应机制上,这些机制可以动态地平衡效率需求和关键信息的保留,确保模型在不牺牲理解准确性的情况下,在各种应用中继续表现出色。这种平衡将是进一步提高稀疏注意力方法在现实世界场景中有效性和适用性的关键。
层级注意力 已经提出了各种层级机制,将结构化层级引入自注意力,利用高层全局信息和低层局部信息实现多尺度的上下文感受野。HAN[609]开创了使用两级注意力机制的先河。它首先对词特征应用自注意力以获得句子表示,然后对句子级特征应用自注意力以生成文档级特征。Hi-Transformer[557]以层级方式建模文档,学习句子表示和文档表示。ERNIE-SPARSE[328]利用层级稀疏Transformer来顺序地统一局部和全局信息。
循环Transformer 除了相对较高的计算复杂性外,自注意力机制在每个词元的编码中整合了全局和局部信息,使其不太适合于长文本理解等任务。基于这一见解,一些工作努力将Transformer架构与循环结构相结合,增强了对长期依赖的捕获,并提高了理解长上下文的能力[447, 569, 620]。
在早期的尝试中,Transformer-XL[90]通过采用段级循环和相对位置编码,将上下文窗口扩展到固定长度之外。Memformer[562]利用外部动态内存来编码和检索过去的信息,在处理长序列时实现了线性时间复杂度和恒定的内存空间复杂度。Compressive Transformer[420]将过去的隐藏激活(记忆)映射到一个较小的压缩表示集(压缩记忆),用于长程序列学习。Block-Recurrent Transformer[203]以循环的方式沿序列应用Transformer层。在训练期间,循环单元操作于词元块而不是单个词元,并利用块内的并行计算来有效利用加速器硬件,相对于序列长度表现出线性复杂性。与现有的基于循环的模型使用特殊的全局词元来存储表示并将其置于输入序列的开头不同,RMT[38]通过添加到输入序列的特殊记忆词元来整合记忆机制,使模型能够有效存储和处理局部和全局信息。SRformer[333]将输入序列划分为段来计算分段注意力,并添加循环注意力来聚合跨段的全局信息。Infinite Attention[374]将压缩记忆整合到注意力机制中,并在单个Transformer块内结合了掩码局部注意力和长程线性注意力机制。ARMT[430]基于用于局部上下文的Transformer自注意力和用于存储分布在长上下文中的任务特定信息的段级循环。
效率驱动的修改 通过缓存先前计算的键/值向量,解码器可以在当前生成步骤中重用它们。键值(KV)缓存避免了为每个词元再次编码历史。虽然这可以显著提高推理效率,但随着序列长度的增长,它会带来昂贵的内存开销。为了减轻KV缓存的内存消耗,一些效率驱动的修改被提出来,包括减少KV头,例如分组查询注意力(GQA)、多查询注意力(MQA)和多头潜在注意力(MLA)机制[308]。请注意,GQA和MQA已在稀疏注意力部分讨论过。对于MLA,它不是直接减少KV头(这主要被认为是性能和内存消耗之间的权衡),而是将键和值压缩成一个潜在向量以减少缓存消耗,并在生成时为每个查询头解压缩键和值头。
3.2.2 线性复杂度架构
线性复杂度方法分为两大类,包括基于SSM架构的Mamba方法,以及基于线性注意力的改进方法。
首先,我们关注状态空间模型(SSM)[235]及其变体。随着上下文长度的迅速增加,更高的训练和推理成本成为瓶颈。为了加速推理和捕获长期依赖,SSM模型逐渐进入人们的视野。SSM源于现代控制系统理论,是一种数学模型,它使用一组一阶微分方程(连续时间系统)或差分方程(离散时间系统)来描述动态系统的行为,同时使用另一组方程来描述状态与系统输出之间的关系[515]。
SSM SSM是基于经典的卡尔曼滤波提出的[157, 244]。它描述了序列在每个时间点的状态表示,并根据输入预测其下一个状态。SSM由两个主要部分组成——状态和观察。状态方程表达了未来状态的趋势,而观察方程则根据当前状态和输入预测当前输出。 \(\begin{aligned} \mathbf{x}'(t) &= \mathbf{A}\mathbf{x}(t) + \mathbf{B}\mathbf{u}(t) \\ \mathbf{y}(t) &= \mathbf{C}\mathbf{x}(t) + \mathbf{D}\mathbf{u}(t) \end{aligned} \quad (5)\) $\mathbf{x}(t) \in \mathbb{R}^N$ 表示状态向量,$\mathbf{u}(t) \in \mathbb{R}^{L}$ 表示输入信号,$\mathbf{y}(t) \in \mathbb{R}^{M}$ 表示输出信号。$\mathbf{A} \in \mathbb{R}^{N \times N}, \mathbf{B} \in \mathbb{R}^{N \times L}, \mathbf{C} \in \mathbb{R}^{M \times N}$ 和 $\mathbf{D} \in \mathbb{R}^{M \times L}$ 分别是状态矩阵、输入矩阵、输出矩阵和前馈矩阵,这些参数通过梯度下降学习。因为 $\mathbf{D}\mathbf{u}(t)$ 项可以看作是一个跳跃连接且易于计算,我们可以假设D是一个零矩阵。重写后的公式如下: \(\begin{aligned} \mathbf{x}'(t) &= \mathbf{A}\mathbf{x}(t) + \mathbf{B}\mathbf{u}(t) \\ \mathbf{y}(t) &= \mathbf{C}\mathbf{x}(t) \end{aligned} \quad (6)\)
经典的SSM模型用于处理连续信号,而在NLP领域,离散输入是常见的[158]。线性状态空间层(LSSL)引入连续SSM以获得两种离散化表示,包括循环表示和卷积表示。Mamba[155]利用零阶保持(ZOH)来离散化SSM。离散化的循环表示如下: \(\begin{aligned} \mathbf{x}_k &= \bar{\mathbf{A}}\mathbf{x}_{k-1} + \bar{\mathbf{B}}\mathbf{u}_k \\ \mathbf{y}_k &= \mathbf{C}\mathbf{x}_k \end{aligned} \quad (7)\) $\bar{\mathbf{A}} = \exp(\Delta\mathbf{A}), \bar{\mathbf{B}} = (\Delta\mathbf{A})^{-1}(\exp(\Delta\mathbf{A}) - \mathbf{I}) \cdot \Delta\mathbf{B}$,$\Delta$是表示输入分辨率的步长。如果我们用$x_t$代替$u_k$,用$h_t$代替$y_k$,我们可以看到它与循环神经网络(RNNs)有相似的公式: \(\mathbf{h}_t = \bar{\mathbf{A}}\mathbf{h}_{t-1} + \bar{\mathbf{B}}\mathbf{x}_t \quad \mathbf{y}_t = \mathbf{C}\mathbf{h}_t \quad (8)\) 与RNN类似,循环表示可以用于高效推理,但不能用于并行训练。因此,LSSL提出了用于训练的卷积表示。
最近,基于SSM的结构化状态空间序列模型(S4)[159]被提出来建模长序列,它比以前的方法计算效率更高,同时保留了其理论优势。
Mamba及其变体 先前的工作发现SSM表现不佳,因为它是一个线性时不变(LTI)系统,与循环和卷积有很深的联系。换句话说,方程7中的$(\Delta, \mathbf{A}, \mathbf{B}, \mathbf{C}, \bar{\mathbf{A}}, \bar{\mathbf{B}})$对于所有时间步都是固定的。然而,LTI在建模某些类型的数据时有根本的局限性。它失去了以输入依赖的方式有效选择数据的能力。Gu和Dao[156]提出了Mamba,通过参数化SSM参数来设计一个简单的选择机制。细节如下: \(\begin{aligned} \mathbf{B} \in \mathbb{R}^{N \times d} &\rightarrow \mathbf{B} \in \mathbb{R}^{B \times L \times N} = \text{Linear}_B(x) \\ \mathbf{C} \in \mathbb{R}^{N \times d} &\rightarrow \mathbf{C} \in \mathbb{R}^{B \times L \times N} = \text{Linear}_C(x) \\ \Delta \in \mathbb{R}^{d} &\rightarrow \Delta \in \mathbb{R}^{B \times L \times d} = \tau_{\Delta}(\text{Parameter} + s_{\Delta}(x)) \end{aligned} \quad (9)\) 其中 $s_B, s_C$ 和 $s_\Delta$ 是线性层,$\tau_\Delta = \text{softplus}$。同时,Mamba引入了一种硬件感知的算法,该算法使用并行扫描而不是卷积来循环计算模型。值得注意的是,它避免了在GPU内存层次结构的不同级别之间的IO访问,而无需建模扩展状态。最终,Mamba的吞吐量比Transformer高5倍,并且在序列长度上具有线性扩展性,这对于长上下文能力非常友好。
许多方法被提出来优化Mamba[65, 625]。例如,ReMamba[625]采用选择性压缩和自适应方法来压缩和保留基本信息,最小化数据退化并减少状态空间更新以减轻信息丢失。与ReMamba类似,TAIPAN[379]将Mamba-2与选择性注意力层相结合,以增强性能并确保计算效率,其中选择性注意力层用于过滤掉不相关的信息。DeciMamba[27]为Mamba引入了一种上下文扩展技术,该技术利用一种隐藏的过滤机制,并允许训练好的模型在没有进一步训练的情况下有效地外推。
线性注意力 Transformer在长上下文任务中具有显著优势,当前模型已扩展到128k或更高。但Transformer的时间复杂度和空间复杂度都是 $O(n^2)$。因此,当 $n$ 显著增大时,Transformer模型的计算负担变得具有挑战性。最近,已经做出了相当大的努力来减轻Transformer中自注意力的计算需求[16, 169, 413, 453, 585]。在本节中,我们将讨论线性注意力的主流工作如下:
首先,Katharopoulos等人[240]提出了线性Transformer模型,通过使用自注意力的核化公式[419]和矩阵乘积的结合律来计算自注意力权重,这大大减少了内存使用量,并与上下文长度线性缩放。Choromanski等人[81]引入了Performers,它利用正交随机特征的快速注意力,并实现了超越softmax的可核化注意力机制。
RetNet[483]包括三种计算范式,即并行、循环和块式循环,块式循环范式为序列建模实现了线性复杂度,同时实现了训练并行性、良好性能和低推理成本。Munkhdalai等人[375]提出了Infini-attention,并将压缩记忆引入到vanilla注意力机制中,该机制在Transformer块中使用掩码局部注意力和长程线性注意力模块。还有类似的方法,如Lightning Attention-2[414]采用分块策略在线性注意力计算期间分别管理块内和块间元素,其中MiniMax-01[366]模型使用此注意力模块。它在块内处理时采用标准注意力机制,而在块间操作时实现线性注意力核技术。Transformer-VQ[306]是一个Transformer解码器,它以相对于序列长度的线性时间执行密集的自注意力计算。这种效率是通过集成矢量量化的键、局部化的位置偏置和为高效注意力处理设计的压缩缓存来实现的。
RWKV家族 与先前使用循环Transformer的尝试不同,RWKV[398]引入了一种增强的线性注意力机制,融合了RNNs的计算效率和Transformers的并行性及表达能力。这使得高度并行的训练和高效的推理成为可能,其线性时间复杂度使其特别适合长序列任务。首字母缩写词“RWKV”代表四个关键元素:
- R (Receptance):一个门控向量,用于整合历史信息。
- W (Weight):一个跨位置应用的可训练衰减因子。
- K (Key):功能类似于标准注意力机制中的键向量。
- V (Value):操作类似于传统注意力系统中的值向量。
RWKV-4是第一个公开发布的版本,经过了实验性迭代(RWKV-1、RWKV-2和RWKV-3)。RWKV-4模型由多个残差块组成,每个块都具有时间混合和通道混合组件。在RWKV-4的基础上,RWKV-5(Eagle)和RWKV-6(Finch)[399]引入了进一步的创新。Eagle通过用多头矩阵值状态替换向量值状态并改进学习衰减策略来增强表达能力。它还重新配置了感受野状态并添加了门控机制以提高性能。RWKV-6(Finch)通过将数据驱动的函数(如参数化线性插值)集成到时间混合和词元移位模块中,进一步提升了表达能力和适应性。它还引入了低秩自适应函数,使权重矩阵可训练,并能够对衰减向量进行上下文敏感的优化。这些进步在保持类似RNN的推理效率的同时,显著增强了模型的能力。
3.2.3 混合架构
Waleffe等人[517]和Park等人[395]证明,尽管Mamba和Mamba-2模型在语言建模方面表现良好,但在长上下文任务(如上下文学习和长上下文检索)中,它们与Transformer模型相比仍有差距。[64]和[517]发现,在架构中加回少量标准的Transformer层可以使模型克服这些问题。混合架构的本质是将线性复杂度的注意力与标准注意力模块相结合。这种集成已经发展成三种主要方法:
- 首先,一种层级混合架构,其中全注意力和线性注意力在层级别混合。值得注意的是,包含滑动窗口注意力(SWA)的模型也属于此类别,尽管早期研究人员可能未将其归类为混合架构。
- 其次,一种预填充-解码混合架构,其中预填充和解码阶段使用不同的架构。该方法在预填充阶段专门使用线性复杂度注意力层,而在解码阶段实现一个包含全注意力机制的混合架构。这方面的开创性工作是YOCO[484]。
- 第三,一种头级混合架构,利用注意力机制的多头原理。该方法将特定的注意力头分配给执行全注意力,同时指定其他头执行线性注意力操作。Hymba[105]是这种方法的开创性工作。
以下部分将详细探讨这三种方法。
层级混合架构 大型语言模型中混合架构的演变代表了在平衡性能和效率方面,特别是在处理长上下文方面的重大进步。层级方法,结合了线性复杂度注意力和标准注意力模块,已成为主导策略。Jamba[302]在规模上开创了这种架构,有效地将Transformer和Mamba层与一个MoE模块相结合,发现7:1的比例(Mamba对Transformer层)提供了最佳平衡。Jamba 1.5[501]将这种方法扩展到超过100B参数,保持相同的7:1比例,同时在256K上下文长度下其KV缓存仅需9GB——相比之下,类似大小的Transformer模型需要80-88GB。谷歌的RecurrentGemma[33]采用了Griffin架构,结合了线性循环和局部注意力,在每个层内使用机制的混合,而不是交错不同的层类型。与此同时,微软的Samba[428]将Mamba与SWA而不是全注意力相结合,保持了线性复杂性,同时为局部上下文提供了注意力的好处。全面的实验表明,这种混合方法在标准基准上优于同等大小的纯Mamba和纯注意力模型。Zyphra的Zamba[149]通过整合一个共享注意力机制进行了创新——每隔几个Mamba块出现一个全局共享注意力块,但所有实例共享参数,从而在保持强大性能的同时减少了内存需求。Zamba2[148]在多个尺寸级别上扩展了这些创新,从Mamba切换到Mamba-2,并使用两个交替的、带有非共享低秩适配器的共享注意力块。MiniMax-01[366]成为第一个在综合基准上实现真正最先进性能的混合模型,其配置为一个带有softmax注意力的Transformer块跟在七个带有闪电注意力的Transformer块之后。它在支持高达400万词元上下文长度的同时,达到了领先商业模型的性能。
滑动窗口方法代表了混合注意力的另一种变体。谷歌的Gemma[500]采用了更平衡的1:1比例的全注意力和SWA层,强调了跨任务的平衡性能,而不是最大化上下文长度。Cohere的Command R-7B[86]实现了一种带有SWA的混合方法,能够高效处理更长的上下文,同时保持强大的基-准性能。Character.ai[46]的研究发现,大约6:1(线性复杂度对全注意力)的比例产生了最佳结果——这与其他混合模型的发现一致。这种在多个独立研究工作中对大约6:1或7:1比例的趋同,表明在设计空间中存在一个“甜蜜点”,表明混合架构不仅仅是一种妥协,而可能是下一代语言模型有效处理多样化上下文的最佳方法。
预填充-解码混合架构 预填充-解码混合方法通过根据操作阶段应用不同的注意力机制来优化语言模型操作——在预填充期间使用线性复杂度注意力,在解码期间实现混合架构。YOCO[484]开创了这种范式,采用了一个解码器-解码器结构,极大地减少了内存需求。自解码器使用线性复杂度注意力处理输入上下文,并产生一个单一的全局键值缓存,然后被交叉解码器的所有层重用。这种设计将KV缓存内存需求减少了大约等于模型层数的因子,这使得在预填充期间能够提前退出,并保持与传统Transformers相当的性能。GoldFinch[152]代表了该类别的另一项创新,它在一个增强的Finch(RWKV-6)架构之上堆叠了一个GOLD Transformer。其关键贡献是“TokenCat”机制,它以线性的时间和空间生成一个高度压缩的键缓存。这种方法带来了显著的效率提升,缓存大小比传统Transformer缓存小756-2550倍。两种方法都表明,预填充-解码混合提供了一种强大的替代纯架构的方法,能够在不牺牲模型质量的情况下,为长上下文推理带来显著的效率改进。
头级混合架构 头级混合方法在同一层内并行地结合了线性和基于注意力的机制,允许不同的注意力头使用不同的机制同时处理相同的输入。Hymba[105]开创了这种方法,采用了一种混合头架构,在每层内将Transformer注意力机制与状态空间模型集成。注意力头提供高分辨率的召回能力,而SSM头则实现高效的上下文摘要。这种设计可以被解释为模仿人类认知:注意力头的功能像快照记忆,存储详细的回忆,而SSM头则作为保留核心信息同时忘记细节的记忆。Samba[428]将Mamba块和滑动窗口注意力块与MLP层结合在一起。它结合了局部和全局注意力机制。局部注意力保持对近邻信息的敏感性,而全局注意力则允许模型捕捉长距离依赖。
4. 工作流设计
最近在长上下文建模方面的进展通常侧重于修改模型参数或改变架构来处理长上下文,这通常涉及微调大型语言模型或实现复杂的内部机制。相比之下,本节介绍的方法旨在在不改变其参数的情况下增强LLMs的长上下文处理能力,而是利用外部组件来增强模型处理长上下文的能力。如图6所示,本章讨论的策略如下:(1)提示压缩(第4.1节)在保留基本信息的同时减少输入上下文的大小。(2)基于记忆的方法(第4.2节)利用外部记忆模块来存储长上下文以进行高效检索。(3)基于RAG的方法(第4.3节)从长上下文中提取或召回特定信息以减少上下文。(4)基于Agent的方法(第4.4节)利用LLM Agent的记忆、规划和反思能力来有效处理长上下文。
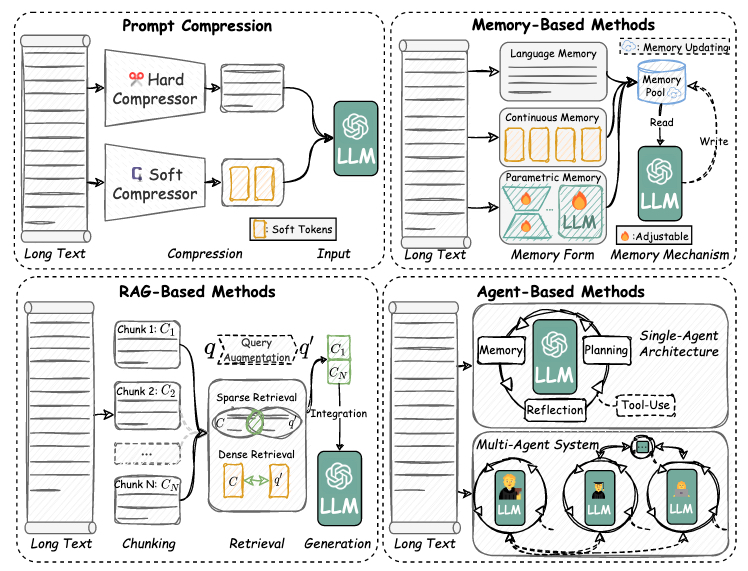
图 6. 基于工作流策略的LCLMs设计。
4.1 提示压缩
随着现实世界任务如思维链(CoT)、上下文学习(ICL)和检索增强生成(RAG)变得越来越复杂,LLMs的提示通常会变得更长,以包含详细的要求、上下文信息和示例[298]。然而,冗长的提示会降低推理速度,增加内存成本或API费用,并降低用户体验。提示压缩旨在通过减少LLMs的输入复杂性来提高其效率。这些技术通常需要一个额外的模块来压缩提示,同时对原始LLMs的参数进行最小或无更改,从而实现即插即用集成。根据压缩后提示的形式,提示压缩方法可以分为两类:1)硬提示压缩保持使用自然语言词或子词(第4.1.1节);2)软提示压缩将自然语言转换为嵌入表示(第4.1.2节)。
4.1.1 硬提示压缩
硬提示是LLM词汇表中由代表特定单词或子词的词元组成的自然语言提示。硬提示压缩旨在简化自然语言提示,通过减少其长度或复杂性,同时保持其引发期望响应的有效性。这个过程通常包括两种方法:(1)选择提示中的相关词元或(2)为了简洁和清晰而重写它。
选择 SelectiveContext[291]通过使用小型语言模型计算词元自信息,将词元分组为词汇单元,并移除冗余内容,来提高LLM推理效率。AdaComp[646]通过同时考虑查询复杂性和检索质量来动态选择相关文档。CPC[307]引入了一种句子级压缩技术,利用上下文感知句子编码器根据句子与查询的嵌入相似度对句子进行排序,并移除不太相关的句子。TCRA-LLM[316]提出了一种具有两种互补方法的词元压缩方案:使用基于T5的模型减少词元大小的摘要压缩,以及消除语义影响较低的词的语义压缩。
此外,强化学习(RL)已被应用于提高提示压缩方法的效率和有效性。DynaICL[679]通过使用强化学习微调一个元控制器来增强上下文学习效率,该元控制器根据输入查询的难度动态调整少样本示例的数量,从而平衡效率和性能。PCRL[234]应用了一种带有强化学习的离散提示压缩方法。TACO-RL[444]利用任务特定的奖励信号,使用在线策略RL来微调一个基于编码器的压缩模型,从而在保持性能的同时实现有效压缩。
此外,LLMLingua系列旨在通过提示压缩为LLMs构建一种专门的语言,从而加速模型推理,降低成本并改善下游性能。LLMLingua[216]利用一个较小的语言模型计算困惑度(PPL)并移除冗余词元,具有预算控制器、迭代提示算法和对齐技术,以在保持语义完整性的同时实现高达20倍的提示压缩。LongLLMLingua[219]提出了一种问题感知的从粗到细的压缩方法、一种文档重排序机制、动态压缩率和子序列恢复策略,以提高LLMs感知和优先处理关键信息的能力。LLMLingua-2[390]引入了一种任务无关的提示压缩方法,通过从GPT-4进行数据蒸馏,用BERT级编码器进行训练,比LLMLingua实现了3x-6x的速度提升,同时保留了关键信息。
重写 一种替代方法是重写提示而不是选择它们。Nano-Capsulator[83]将冗长的提示封装成更短的提示,同时遵守特定的生成长度约束,通过明确的语义保持目标和奖励评分来维持性能。CompAct[618]通过动态保留基本上下文和整合信息,从大量文档中捕获关键信息。FAVI-COMP[233]是一种解码时证据压缩方法,它产生一个对目标模型更熟悉的精炼证据集,在无缝整合参数化知识的同时增强RAG性能。
4.1.2 软提示压缩
软提示[268]通过消除对离散词元的依赖,提出了一种创新的范式。它们直接通过反向传播学习一系列连续的嵌入,这些嵌入可以被输入到Transformer中,而无需映射到任何实际的语言词元。这样的软提示可以作为传统纯文本上下文的有效替代方案,显著减少推理过程中的计算开销。根据原始LLMs的参数是否更新,软提示压缩可以大致分为两类:1)LLM固定方法和2)Gist词元方法。
LLM固定 LLM固定方法专注于在不更新原始LLMs参数的情况下压缩提示,为管理输入上下文长度提供了一种高效的解决方案。它们涉及训练额外的模块,将离散词元转换为连续嵌入,从而促进高效的提示压缩。对比条件化[555]专注于学习紧凑的软提示,通过最小化Kullback-Leibler(KL)散度来模拟原始的自然语言提示。然而,对比条件化会产生大量的计算开销,因为它需要为每个新的输入提示从头开始重新训练,这使其在广泛应用中不切实际。ICAE[140]生成紧凑且信息丰富的记忆槽来代表原始上下文,使LLM能够在相同的上下文长度内编码更多信息。这提高了模型处理长上下文的能力,并减少了推理过程中的计算和内存开销。500xCompressor[299]建立在ICAE之上,但使用KV值代替嵌入来表示压缩词元,实现了显著的压缩率。xRAG[72]使用一个冻结的嵌入模型作为编码器,以及一个编码器和解码器LLM之间的可训练适配器。通过模态融合,它将文档嵌入整合到LLM的表示空间中,消除了对文本表示的需求并实现了高压缩率。UniICL[131]将演示压缩成压缩特征,然后通过一个可学习的投影层转换为压缩的虚拟词元。这些虚拟词元取代了原始的演示以缩短输入长度,并帮助选择潜在的演示。然后,查询和虚拟词元被输入到冻结的LLM中进行响应生成。
总之,LLM固定方法通过优化输入表示同时保留原始LLM的冻结参数,为提示压缩提供了多样化的策略。这些方法显著增强了计算和内存效率,使得LLMs在广泛的任务中得到更有效的利用。
Gist词元 Gist词元方法旨在通过将上下文压缩成一小组称为“gist tokens”[371]的特殊词元来压缩提示。这些词元取代了原始上下文,实现了高效的缓存和重用,同时减少了计算成本。然而,这类方法通常需要修改LLM的参数。Gist[371]引入了一种在标准指令微调之上无需额外成本即可训练模型进行提示压缩的方法,它在提示后插入gist词元,并修改Transformer的注意力掩码,以防止gist词元之后的词元关注到它们之前的词元,从而使模型能够同时学习提示压缩和指令遵循。AutoCompressors[73]通过递归生成gist词元来处理长文档,这些gist词元作为软提示传递给所有后续段,从而产生更紧凑的软提示。Activation Beacon[645]作为一个基于Transformer的LLMs的插件,可以有效、高效、灵活地压缩长上下文,其特点是一个渐进的压缩工作流,将上下文提炼成一小组激活值。
总之,gist词元方法为减少输入长度提供了一个强大的框架,通过将上下文转换为紧凑、可重用的词元。这些方法带来了显著的效率提升,尽管它们通常涉及更新LLM的参数以实现有效的压缩和集成。
4.2 基于记忆的方法
基于记忆的方法旨在利用外部模块(即记忆模块)来存储长上下文。这种方法有效地减少了直接依赖长上下文的计算负担,并减轻了与提示压缩相关的潜在信息减少。通常,记忆模块不仅存储基本的历史信息,还能动态更新,从而实现对长上下文环境的高效管理。
记忆增强一直是一个被积极探索的话题。甚至在ChatGPT出现之前,就已经提出了许多方法。例如,Mem-Prompt[348]和[91]以文本形式存储用户对模型响应的反馈,从而在后续交互中实现更个性化和准确的响应。Socratic Models[631]使LLMs(大型语言模型)、ALMs(音频语言模型)和VLMs(视觉语言模型)能够共享一个统一的记忆单元,该单元存储了在自我中心视频中捕获的大量观察日志。通过从这些日志中提取关键信息,LLMs可以在长上下文环境中有效运作。Token Turing Machine[436]利用一个由连续向量组成的外部记忆单元。通过交叉注意力机制,模型可以从外部环境读取信息进行处理,或将处理后的信息写回记忆模块。这使得模型能够实现长周期的机器人控制。
自ChatGPT出现以来,LLMs已进入了Agentic工作流时代。这个范式为LLMs配备了记忆、检索、规划、反思和工具使用等能力,使它们能够适应和响应复杂的现实世界任务。在本节中,我们关注这些LLMs或Agent如何通过记忆增强来理解长上下文或在长文本生成期间保持一致性。需要注意的是,§4.4中的讨论与此重点不同。后者强调利用Agentic工作流来专门增强LLMs的长文本能力。
用于长文本语言模型的基于记忆的方法可以根据记忆的形式分为三种范式:(1)连续记忆(潜在向量表示),(2)语言记忆(文本内容),和(3)参数记忆(模型权重)。
语言记忆。语言记忆将历史信息存储为人类可读的文本片段,并通常通过检索和提取来减少其长度。例如,Generative Agents[394]使用一个带有三重评分机制的“记忆流”来进行项目检索:(1)新近度,使用指数衰减函数优先考虑最近的交互;(2)重要性,其中LLM根据其语义重要性为每个记忆项目分配1-10分;和(3)相关性,计算为当前查询和记忆项目之间的嵌入相似度。这种机制在一个沙盒环境中有效地管理具有极长交互记录的复杂上下文。Reflexion[458]将来自自我反思的文本反馈存储在记忆库中。当在后续生成中出现类似错误时,模型会检索历史反思记录进行实时校正。MemoryBank[675]结合了艾宾浩斯遗忘曲线,逐渐削弱不常访问的记忆,同时加强常用记忆,模拟了人类长期记忆的形成。AdaPlanner[478]和Voyager[522]通过一个技能库机制来解决长周期任务规划,其中先前交互中成功的文本行动计划被存档为可重用的模板。这些存储的计划可以动态地合成为新任务的复杂策略。这种能力可以看作是将过去的长文本形式的记忆简化为技能项,并根据即时需求检索和合成它们,形成可管理和有效的上下文,用于后续的文本生成任务。RecurrentGPT[680]通过结合相关段落的长期记忆检索和通过迭代情节摘要维护的短期记忆,增强了长文本故事生成的连贯性,模仿了人类在持续叙事一致性方面的认知过程。
连续记忆。连续记忆将长上下文信息编码为潜在向量表示,实现了历史上下文的高效检索,而无需显式存储原始文本。例如,LongMem[540]将长文本分割成固定长度的片段,并将其在Transformer中间层的键值对缓存到外部记忆库中。在推理过程中,它通过查询-键注意力操作检索top-k相关的历史键值对,并通过联合注意力机制将它们与当前的隐藏状态整合。一个新设计的、在LLM主干和可训练的Transformer-based SideNet之间的跨网络残差连接执行了这样的记忆检索和融合操作。MemoryLLM[545]在每个Transformer层内嵌入可训练的记忆词元作为一个固定大小的记忆池,实现了一种自我更新机制,通过每次更新周期仅替换一部分记忆单元,选择性地用新信息覆盖较少访问的记忆信息。
参数记忆。参数记忆将长上下文信息内化到模型的权重中。例如,DSI(可微分搜索索引)[496]将文档检索重新表述为一个生成任务,训练模型直接输出查询的文档ID,从而允许在模型参数中记忆文档-查询映射。这种方法消除了外部存储和检索的需要。此外,DSI++[355]通过引入一个清晰度感知的损失函数来解决DSI在持续学习设置中的灾难性遗忘问题:$\max_{\epsilon_2 \le \rho} L(w + \epsilon)$,其中$w$是模型参数,$\rho$是一个阈值。这个损失函数鼓励模型收敛到更平坦的最小值,这在经验上被证明可以提高记忆保留能力。此外,DSI++采用了一种生成式记忆技术进行记忆重放,其中生成器为先前索引的文档合成伪查询。这些查询与新的文档数据混合,在持续训练期间以减轻遗忘并保持更新。Generative Adapter[62]根据其来自基础LM的隐藏状态([$h_1, h_2, …, h_c$])动态生成先前上下文块([$C_1, C_2, …, C_c$])的轻量级适配器模块($\Delta_\theta$),在测试时进行上下文化。然后,在推理过程中,生成的适配器被集成到基础LM中进行文本生成。
优缺点。基于记忆的方法通过解决基于Transformer的LMs固有的有限上下文窗口限制,为长文本语言模型提供了关键的理论优势,这些限制要么截断长序列,要么因注意力机制产生二次计算成本。通过将长上下文的存储外部化,这些方法绕过了vanilla Transformer的架构瓶颈,同时保留了关键的历史信息。记忆增强的计算完备性进一步由Schuurmans[441]强调,他证明了vanilla Transformer-based LMs在计算上是受限的,这可以通过读写记忆增强来克服。他们的实验表明,一个540B参数的LLM(即Flan-U-PaLM-540B)与联想读写记忆可以模拟一个通用的图灵机。类似的结论也从[98]中得出。然而,基于记忆的方法面临着实际的挑战,包括检索延迟、记忆上下文和实时上下文之间的不一致性,以及记忆更新的复杂性等。
4.3 基于RAG的方法
与用于LLMs长文本能力的基于记忆的方法一致,检索增强生成(RAG)旨在从长文本中提取或召回特定信息以减少上下文。检索源可以是训练语料库、知识库、互联网、提供的长上下文,或前述的外部记忆¹。
具体来说,利用RAG技术增强LLMs的长文本能力涉及一个三阶段的工作流程:(1)分块以将长上下文划分为可管理的单元,(2)检索以提取最相关的信息,以及(3)生成以将检索到的知识与内在的模型理解合成为连贯且上下文丰富的输出。
分块。Vanilla分块单元包括固定的词元长度[272]、句子或段落、像“\n”或“\t”这样的分隔符、像Markdown标题或LaTeX节这样的结构标记,以及语义相似的句子邻居²。然而,这些方法有几个关键问题如下:
- 确定最佳块大小:过大的块可能会超出嵌入模型的输入限制,而过小的块可能会使上下文碎片化,使检索更具挑战性,并可能降低检索信息的质量。
- 保持上下文完整性:确保切分不会破坏语义或忽略关键信息,如指代引用(例如,“它”、“他们”)。
- 平衡效率和有效性:分块必须在计算上高效,同时保留足够的细节以供下游任务使用。
- 适应数据格式:不同的数据格式(例如,文本、代码或表格)可能需要特定的分块策略。
为了缓解这些问题,例如,Late Chunking[167]首先用一个支持长输入的嵌入模型嵌入长文档,然后在嵌入上进行分块。这种方法确保每个块嵌入捕获整个上下文语义。Sliding Window Chunking³将文本划分为固定大小的重叠块,确保跨块边界的上下文依赖性得以保留。Contextual Retrieval[14]利用一个长上下文LLM,在嵌入之前将整个文档作为其上下文来增强目标块。LLM通过整合相关的上下文信息生成目标块的丰富版本。
检索。检索阶段可以根据检索器类型分为两种方法:(1)稀疏检索器,主要使用文本数据的稀疏表示,如TF-IDF[48]、BM25[440]或Jaccard指数[634];(2)密集检索器,使用具有连续值的密集向量,如BERT[101]特征。在这两种方法中,密集检索器由于其捕捉语义相似性而不是依赖词汇匹配的能力而被广泛使用。通过将查询和文档(例如,长上下文)编码到共享的潜在空间中,密集检索器实现了更高的检索准确性,并扩展了其功能,如指令遵循[372]、对话式搜索[368]、复杂推理[231],以及在与特定技术结合时的缩放定律[122]。例如,BGE-M3[55]是一个集成了稀疏和密集检索的多语言检索模型,支持高达8192个词元的扩展上下文窗口。ModernBERT[548]是一个在2万亿词元上训练的基于BERT的模型,具有8192个词元的上下文长度,在自然语言理解(NLU)和长上下文检索任务中表现出色。REAPER[231]通过整合复杂推理来增强检索,将检索查询分解为一系列计划和链式步骤。
此外,几种技术增强了查询以提高检索质量。例如,Query2Doc[529]使用少样本提示生成伪文档,并用这些文档扩展原始查询。HyDE[133]通过一个遵循指令的语言模型产生一个假设文档,用一个对比学习的编码器对其进行编码,并使用得到的嵌入向量从语料库中检索相似的真实文档。Rewrite-Retrieve-Read[344]采用一个可训练的小型语言模型作为重写器,通过来自LLM的反馈进行强化学习优化,在从网络搜索引擎检索上下文并用LLM处理之前对查询进行精炼。
生成。在通过分块和检索减少了长上下文之后,下一步是将减少的信息整合到LLMs中进行生成。通常,在没有建模训练的情况下,减少的信息通过简单的上下文串联[166, 207, 457]或进一步的提示压缩[587]被输入到LLMs中。例如,Fusion-in-Decoder[206]最初将所有检索到的段落连同相应的问题编码成一个软特征序列,然后将其连接并输入到仅解码器的LLM中。检索到的信息也可以用来调整解码过程。例如,kNN-LM[242]将模型的预测分布与其从检索知识中得到的最近邻的预测分布混合,以在输出端调整生成。对于某些专门的模型架构,如Retro[31],使用训练好的交叉注意力模块来整合信息。
¹通常,检索到的记忆被称为长期记忆[680]。 ²https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/tutorials/LevelsOfTextSplitting/5_Levels_Of_Text_Splitting.ipynb ³https://safjan.com/from-fixed-size-to-nlp-chunking-a-deep-dive-into-text-chunking-techniques/
4.4 基于Agent的方法
LLM Agent是一个自主的LLM实体,它拥有一个由几个关键组件组成的认知架构:用于接收和处理输入的感知能力,用于信息存储的记忆系统(短期和长期),用于文本输出和工具操作的行动生成能力,用于自我评估的反思机制,用于目标设定和任务分解的规划能力,以及用于逻辑思维和决策的推理能力[527, 573]。在长上下文LLMs的背景下,LLM Agent利用其记忆、规划和反思能力来有效处理长文本。例如,Generative Agent[394]通过一个全面的架构展示了这些能力,其中Agent可以从其记忆流中提取和检索相关信息,生成周期性的反思以从低级观察中合成高级见解,并创建可以根据新信息或交互动态调整的详细计划。这种认知架构使Agent即使在处理广泛上下文时也能保持连贯的理解并生成适当的响应。
增强LLMs长文本能力的基于Agent的方法可以大致分为两类:单Agent和多Agent方法。这两种范式在它们的架构设计和操作机制上有所不同:(1)单Agent架构,和(2)多Agent系统。单Agent方法专注于在单个LLM Agent实体内开发全面的认知架构。这些方法强调构建强大的记忆管理系统、复杂的规划机制和有效的反思过程。相比之下,多Agent系统将认知负荷分配给多个专门的Agent,每个Agent处理长文本处理任务的特定方面。这种范式强调劳动分工和协作解决问题。Agent可以进行结构化的对话、辩论或协作分析,以更有效地理解或生成长文本。
单Agent架构。对于长文本理解,ReadAgent[263]采用了一个由LLMs驱动的三阶段记忆管理方法。系统首先将相关内容分组为连贯的记忆单元,然后将这些单元提炼成浓缩的摘要以便高效存储。当需要特定信息时,它可以智能地导航回源文本以检索任务完成的精确细节。PEARL[480]采用了一个三阶段的提示框架来增强对长文档的推理:行动挖掘、计划生成和计划执行。当给定一个关于长文档的问题时,PEARL将其分解为具体的行动(如总结、查找事件和识别关系),然后在文档上执行这些行动以得出答案。Self-Notes[260]生成多个与输入上下文和问题交错的QA笔记,以处理长上下文推理问题。MemWalker[51]作为一个交互式阅读系统,将长文档分解为层级结构的摘要。当给定一个查询时,它系统地探索这个结构化信息,穿过不同的摘要级别,直到找到并收集提供准确响应所需的相关细节。GraphReader[286]引入了一种创新的方法,将冗长的文档转换为可导航的图结构。系统部署一个AI Agent智能地遍历这个图表示。当收到一个查询时,Agent首先进行详细分析以制定搜索策略。使用专门的导航工具,它以层级方式系统地移动通过图,检查单个节点及其连接。Agent维护一个动态的发现记录,并持续评估其进展,根据需要调整其方法,直到收集到足够的数据来构建一个全面的响应。RoleAgent[311]采用一个层级记忆系统,将长文本观察提炼成更短的事件、关键点和见解,实现了从粗到细的信息搜索,以满足用户-LLM交互。
至于长文本生成,Re3[602]遵循一个迭代的五阶段过程进行长篇故事生成。过程从一个给定的前提开始,以启动故事。基于这个前提,计划阶段使用LLM生成背景、角色和概要。接下来,草稿阶段通过用计划和先前生成的内容提示模型来编写故事的续篇。然后,过程进入重写和编辑阶段的迭代循环:在重写阶段,生成的故事续篇因其与情节的连贯性和与前提的相关性而被重新排序,而在编辑阶段,选定的续篇被精炼以确保长期的事实一致性。这个起草、重写和编辑的循环一直持续到最终的故事生成,文本自然流畅并与原始前提对齐。RecurrentGPT[680]为长文本生成构建了两个记忆流,其中LLM Agent配备了短期和长期记忆流。在生成长文本期间,Agent维护并更新一个先前生成段落的简短摘要作为上下文的一部分,这也被称为短期记忆。此外,为了整合更详细的历史段落信息,LLM Agent还通过一个检索机制来增强,以召回与当前生成段落作为查询最语义相关的历史段落,这也被称为长期记忆。当新段落生成时,两种记忆都会更新。
多Agent系统。Chain of Agent (CoA)[656]利用一个多Agent框架来处理长上下文任务。它将上下文划分为更小的片段,每个片段由一个工作Agent处理。这些工作Agent与一个中央管理Agent顺序通信,后者将贡献合成为一个连贯的输出。这种方法通过为每个Agent分配一个短上下文并交错阅读和推理,来确保高效的上下文处理。类似地,LongAgent[663]采用一个领导者-Agent模型来处理长文本。领导者理解用户的意图并指导成员Agent从文档中提取信息。一个Agent间的通信机制解决Agent响应之间的冲突,确保领导者收集准确的数据。这种多Agent方法在减轻幻觉问题的同时,实现了对长上下文的高效处理。
5. 基础设施
在本节中,我们研究支持LCLM训练和推理的AI基础设施,重点介绍了与通常用于通用LLM的技术的关键差异。讨论的大多数方法主要是为提高效率而设计的。其他的则代表了工程和算法方法的结合,最初是为了提高长上下文带来的模型性能而提出的。
5.1 LCLMs的训练
随着LLM算法的进步,训练效率的优化也经历了重大的创新。鉴于参数和计算复杂性的规模,分布式训练是LLMs的标准解决方案。自ChatGPT问世以来,主流的NVIDIA GPU计算资源已经通过Volta、Turing、Ampere、Hopper和Blackwell架构演进⁴,导致单GPU计算能力(例如,从V100S的16.4 TFLOPS单精度到B200的2,250 TFLOPS)增加了百倍。在分布式设置中最大化这种计算能力是LLM训练的关键挑战。计算、通信、内存管理和并行化策略的优化已成为标准实践,并产生了显著的性能提升。这些方法被集成到著名的训练框架中,如Megatron[459]、DeepSpeed[424]和FSDP[667],促进了模型的开发和训练。许多综述[34, 113, 329]已经记录了这些基础技术。
然而,长上下文长度带来了进一步的挑战。有限的GPU内存,特别是,使得大多数常见的训练优化无效。减小批次大小可能能够执行,但低效的计算和内存访问瓶颈会严重降低整体训练效率。高性能长上下文训练主要探索并行计算策略和复杂的通信-计算重叠,以最大化硬件利用率和连续性。具体来说,这些方法解决了I/O、GPU资源约束和通信瓶颈,如表5所示。
| 高效策略 | 计算开销 | I/O开销 | GPU HBM内存 | 通信开销 |
|---|---|---|---|---|
| 训练 | ||||
| 基础I/O优化 | – | ✓ | – | – |
| 数据打包 | – | ✓ | – | – |
| 文件系统 | – | ✓ | – | ✓ |
| 混合精度训练 | ✓ | – | ✓ | ✓ |
| 低精度训练 | ✓ | – | ✓ | – |
| 优化内存访问 | ✓ | – | ✓ | – |
| 计算分区 | ✓ | – | ✓ | ✗ |
| 通信-计算重叠 | ✓ | – | – | ✓ |
| 推理 | ||||
| 量化 | ✗ | ✓ | ✓ | – |
| 虚拟内存管理 | – | ✓ | ✓ | ✓ |
| 调度策略 | ✓ | – | – | – |
| 预填充-解码分离 | ✓ | ✓ | – | ✓ |
| GPU-CPU并行推理 | ✓ | ✗ | ✓ | – |
| 推测性解码 | ✗ | ✓ | ✗ | – |
表 5. AI基础设施优化比较。✓表示对此方面的优化,✗表示对此方面的负面影响,而–表示没有影响或不涉及。
5.1.1 I/O优化
I/O的终极基础优化 训练LCLMs固有地需要更大的词元批次大小和显著变化的数据长度。鉴于内存、网络带宽和PCIe带宽的限制,从内存读取和传输这些大量数据到GPU会大大减慢批次构建。因为I/O性能通常落后于现代GPU计算性能,I/O成为训练过程中的一个主要瓶颈。通常采用策略性方法,如增加I/O线程数量和利用固定内存(pinned memory),来缓解此问题。然而,这些策略性I/O优化的最佳超参数需要根据模型大小、上下文窗口长度和硬件配置进行个案调整;否则,CPU核心或内存可能成为新的瓶颈。
复杂的数据打包 数据打包将样本连接成更长的序列。为了最大化批次中数据的有效利用,打包需要适当的组合排列和必要的截断[337, 470]。打包会改变数据读取顺序和实际的训练分布,可能影响训练性能。注意力掩码可以区分打包的样本[253],确保必要时的隔离。然而,构建非因果注意力掩码会引入碎片化的操作,非因果注意力会对训练效率产生负面影响。一些方法[18, 249]采用数据采样来确保样本长度遵循预定义的上限。存在其他动态调整上下文长度的解决方案。例如,Hydraulis[276]避免使用固定的上下文窗口,但使用动态规划来解决数据采样不平衡和数据打包不平衡的问题。Data Decomposition[406]使用多个桶大小将数据整理到不同的窗口。基于这些已建立的数据组织策略,许多最近的预训练模型采用了渐进的长度扩展方法。这种方法在常用的长文本基准上展示了显著的性能改进[58, 135, 596, 665]。
分布式文件系统和预取 在LLM训练过程中,数据从磁盘/网络读取到主机缓存,然后通过PCIe传输到GPU。在分布式训练中,CPU的数据检索和分发受限于PCIe带宽。使用近端数据工作者[662]或缓存[103]进行预取可以有效地重叠I/O和计算,甚至隐藏和消除I/O延迟。在观察到SSD吞吐量和RDMA带宽未被充分利用后,3FS[96]引入了一种分布式的随机访问方法,通过利用可用的资源来增强性能和可用性。
5.1.2 GPU约束和内存访问的优化
混合精度训练 GPU内存在长上下文LLM训练中是一个显著的瓶颈,参数、梯度、优化器状态,尤其是激活值(与序列长度成比例)消耗了大量资源。通过低精度或混合精度计算来降低数值精度[161]是一个自然的解决方案。混合精度训练[359]是一种常见的内存优化技术。通常,浮点运算使用FP32(单精度),分配8个指数位和23个尾数位。在内存受限的场景中,牺牲一些精度可以减少存储需求,例如,FP16需要一半的存储空间。然而,FP16的最大整数值为65,536,可能因数值溢出而导致NaN或Inf异常。BF16是另一种半精度格式(需要Ampere架构或更高版本),增加了指数位,以一些精度为代价减轻了溢出。FP16/BF16现在是LLM训练的标准,FP32[523]保留给精度敏感的操作(RoPE、LayerNorm、Softmax)和通信归约(应避免使用BF16)。
量化和低精度训练 最近的量化训练方法结合了量化微调,使用8位浮点数(FP8)或整数(INT8),并在推理阶段保持准确性。FP8目前可在TransformerEngine和其他衍生加速库[661]中用于Hopper GPU,主要用于Transformer层中不太精度敏感的矩阵乘法。它对前向传播使用E4M3(4位指数,3位尾数),对后向传播使用E5M2,可能提供比BF16高2倍的性能提升。INT8整数适用性更广,构成了大多数当前量化方法的基础。权重-量化是最直观的方法,将值映射到每个张量的统计或预定义范围内的256个离散级别。量化显著减少了内存占用,并且通过适当的硬件和软件支持,反量化开销可以被融合和最小化,从而显著提升性能。然而,降低的精度可能会不可逆地影响模型性能。一些研究观察到,在训练过程的关键位置[198, 402, 623]可以适当地补偿误差。优化器状态对精度更敏感,需要仔细训练,并使用动态范围缩放来使其分布与FP8表示对齐,从而减少内存占用和量化误差[99, 571]。除了权重和优化器状态量化,激活值量化也吸引了大量研究。直观上,量化激活值会导致大量信息丢失。幸运的是,最新的研究发现这种损失主要归因于激活值的离群点,在训练期间抑制这些离群点可以实现可靠的激活值量化[283, 304, 578]。
优化的内存访问和分块计算 Transformer的多头注意力机制的二次时间和内存复杂性带来了显著的计算和内存挑战,特别是在长输入序列的情况下。FlashAttention[93]通过利用GPU共享内存的高带宽但有限容量(例如,19TB/s带宽,20MB限制)来解决这个问题,进行分块处理。它采用log-sum-exp技巧进行优化的softmax计算,并缓存键值和累积和以最小化内存访问。FlashAttention在标准和长上下文训练场景中都展示了显著的性能提升。除了这些对标准注意力的优化,像稀疏FlashAttention[388]这样的变体也获得了关注。FlashAttention-v2[92]改进了其前身的计算顺序,减少了非矩阵乘法,并优化了线程块内的warp调度,以最小化共享内存访问并最大化GPU并行性。此外,利用Hopper GPU架构引入的Transformer Engine,FlashAttention-v3[442]整合了FP8加速和三个关键技术:通过生产者-消费者模型的异步数据加载和计算,重叠的softmax和GEMM计算,以及分块量化。这种分块优化范式促进了进一步的算法和工程协同优化,如NSA的[627]混合方法所示,该方法结合了词元压缩、选择和滑动窗口,以及MoBA的[336]分块注意力机制,使用类似MoE的策略在全注意力和稀疏注意力之间取得了有利的平衡。类似的解决方案已在MLA[278]上得到验证。
计算分区 分布式计算与分片有效地减轻了长上下文窗口带来的内存压力。标准自注意力的计算复杂度为O(n²),其中n是序列长度。环形注意力[309]通过将每个词元的注意力限制在固定数量的周围词元上,将其降低到O(n),显著减少了计算和内存成本,并能够处理更长的序列。结合局部和全局注意力机制的混合方法通过在保持长程依赖建模的同时减少计算开销来进一步提高性能[35, 310]。更直接的方法采用各种并行化策略:序列并行[248]将模型层分布在设备上,减少了单个设备的负载,但需要大量的设备间通信,并且目前仅分片Dropout和LayerNorm激活,为优化留下了空间。上下文并行⁵将上下文窗口划分为并行处理的段,随后聚合它们的表示。这有效地减少了内存需求并提高了训练速度。Ulysses并行[208]集成到DeepSpeed框架中,结合了分片模型层和上下文窗口的优点,并采用交错策略,最小化通信开销,同时最大化并行效率,在极长上下文窗口中展示了显著优势。
5.1.3 通信-计算重叠的优化
分布式LLM训练需要节点间的通信来进行梯度聚合和中间计算结果。计算和通信之间的性能差异导致硬件未充分利用,在长上下文训练中情况更糟。由于在这种情况下CPU被大量用于I/O,将计算卸载到CPU可能不会产生预期的收益,因此通信优化至关重要。重叠技术使得前向计算与参数收集或后向梯度聚合能够并行执行,从而提高了整体效率。先进的双向流水线并行技术有效地减轻了流水线气泡[97]。梯度累积(GA)是改善计算和通信之间重叠的关键方法。在LCLM训练中,高单样本内存使用限制了单个节点上的局部批次大小。GA通过实现小批量来解决这个问题:在较小的批次上执行前向传播,并在多个小批量中累积梯度,然后进行一次统一的参数更新。这允许小批量前向传播与前一个后向传播通信的完全并行化,有效地在内存约束下模拟大批量训练。然而,将GA与DeepSpeed-ZeRO集成需要仔细考虑。虽然ZeRO-1由于其非分区的梯度,在后向传播期间只需要一次通信步骤,但ZeRO-2,它在节点间分区梯度,需要在每个小批量前向传播后进行通信以收集所有梯度分区,可能阻碍完全重叠。训练引擎通常将GA作为一个组件,利用不同的CUDA流来实现定制优化[468]。在LLM训练中,策略性地在内核内利用不同的CUDA流,可以为不同的模型架构和硬件配置量身定制最佳的重叠策略[45, 243],有效地解决了通信和计算速度之间的差异。
5.2 LCLMs的推理
推理可以分为两个不同的阶段:i) 预填充阶段,处理输入提示以生成大型语言模型的KV缓存。ii) 解码阶段,模型利用KV缓存生成后续词元。通常,预填充阶段是计算密集型的,这意味着减少计算开销是加速此步骤的关键。相比之下,解码阶段是带宽密集型的,需要优化内存传输以提高效率。在长上下文推理中,基础设施面临四个主要挑战:首先,在预填充阶段,注意力的计算会产生与序列长度相关的二次时间复杂性。此外,在生成过程中,使用极大的KV缓存会带来显著的内存和I/O压力。在执行多设备或跨设备计算时,还存在通信开销。各种方法解决的挑战在表5中有所描述。
- 计算开销。在预填充阶段,KV缓存的计算会产生与序列长度相关的二次时间复杂性。研究工作旨在加速预填充过程[218, 292],主要减轻计算开销。相比之下,解码阶段主要是带宽受限的。解码的优化,如量化和推测性解码,通常以增加的计算工作量换取减少的内存传输需求。
- I/O开销。在自回归解码中,I/O操作成为速度的主要瓶颈。每个I/O操作都需要将模型参数和KV缓存传输到计算单元以生成下一个词元。对于长输入,压缩KV缓存内存可以显著提高速度。对于长输出,推测性解码和模型参数量化通过减少传输模型参数的内存来加速过程。
- GPU HBM内存。长文本任务也对GPU施加了显著的HBM压力。因此,一些方法将KV缓存卸载到CPU,并使用检索技术来减轻HBM上的内存使用。应用于模型参数或KV缓存的量化也可以帮助减少HBM上的压力。
- 通信开销。在大规模部署中,通常会缓存提示的预计算KV缓存,当接收到相同的提示请求时,KV缓存会通过通信在不同机器之间传输。内存管理和预填充-解码分离方法可以优化这方面。
在以下小节中,我们将介绍几种通过AI基础设施改进来增强推理性能的常用技术。这些技术包括:量化、内存管理、PD分离、GPU-CPU并行推理和推测性解码。
5.2.1 量化
在长上下文LLMs中,处理扩展的输入序列会导致KV(键-值)缓存大小显著增加。此外,生成冗长的输出序列需要重复地将KV缓存和模型参数传输到计算单元,加剧了带宽需求。为了缓解这些挑战并加速解码阶段,量化成为一种关键策略,通过减少传输的数据量。长上下文LLMs的量化可以应用于单独的KV缓存,或者同时应用于模型参数和KV缓存。
一种策略是专注于仅量化KV缓存[104, 187, 237, 332, 649]。然而,由于主流架构普遍缺乏对混合精度操作(例如,FP16 x INT4)的原生硬件支持,高效的融合计算通常需要开发专门的内核。在KV缓存量化中,常见的优化技术包括:用不同的方法量化键和值[187, 332],过滤离群点[187, 668],记录或调整通道的大小[114, 578, 668]。相比之下,将模型权重和激活值量化为统一的低精度[318, 454, 578, 611, 629, 668]允许直接利用现有的硬件支持的低精度操作。
5.2.2 内存管理
虚拟内存管理 在长上下文推理中,KV缓存会变得非常大,导致内存碎片化和使用效率低下。虚拟内存管理技术通过优化KV缓存内存的分配和访问方式来解决这些挑战,减少浪费并提高长序列的性能。PagedAttention[257]利用虚拟内存将不同层和头中的词元的KV缓存放置在同一个内存页中。vTensor[589]引入了一个将计算与碎片整理解耦的虚拟内存抽象。KV-Compress[426]扩展了PagedAttention以支持基于词元的KV压缩。
调度策略 在处理长上下文时,特别是在批处理推理或具有共享前缀的场景(如对话式AI)中,KV缓存和计算的高效调度变得至关重要。调度策略通过组织数据结构以促进去重和共享,从而最大化长输入的内存利用率和计算效率。ChunkAttention[614]和MemServe[190]组织数据结构以实现高效的缓存去重和共享公共前缀,从而提高内存利用率和计算效率。SGLang[673]使用RadixAttention在批次之间共享公共前缀。
5.2.3 预填充-解码分离架构
长上下文LLMs对KV缓存的计算和内存需求都更高,因此固有地遭受更高的延迟、资源消耗和潜在的瓶颈。为了解决这些挑战,预填充-解码分离将计算密集的预填充阶段与带宽敏感的解码阶段解耦,将每个阶段分配给为其独特资源需求而优化的专用服务器池[396, 411]。通过策略性地分配硬件,PD分离提高了推理效率,显著改善了预填充阶段的首次词元时间(TTFT)和解码阶段的每输出词元时间(TPOT)[676]。Distserve[676]为每个阶段定制资源分配、并行策略、部署算法和运行时调度优化。Splitwise[396]研究了如何在集群内分配机器以有效处理预填充和解码阶段。Mooncake[411]特别擅长长上下文场景和高用户负载,开发了一种基于预测的早期拒绝策略。CacheGen[330]通过采用优化的存储格式减少了预计算KV缓存跨机器的传输时间。这些研究共同突显了PD分离在加速LLM推理方面的潜力,为这些强大模型的更可扩展和成本效益的部署铺平了道路。
5.2.4 GPU-CPU并行推理
GPU内存专为计算单元的高带宽访问而设计,其固有的限制性常常不足以容纳日益增大的KV缓存,尤其是在长上下文场景中。一个成本效益高的缓解此限制的策略是将KV缓存卸载到CPU内存,并有可能进一步卸载到硬盘或网络存储[215, 593]。虽然卸载减少了GPU内存压力,但它引入了一个新的瓶颈:慢速的PCIe总线在将KV缓存从CPU传输到GPU进行计算时成为一个限制因素[173, 619]。为了缓解慢速PCIe带宽的问题,GPU-CPU并行推理方法利用PCIe传输期间的并发CPU计算,要么减少需要传输的数据量,要么优化后续的GPU计算,从而提高整体效率。FlexGen[454]和PipeSwitch[22]是试图将当前层的GPU计算与下一层KV缓存的并发加载重叠的技术。FastDecode[173]提出直接在CPU上计算注意力分数,利用其相对于GPU更快的内存访问KV缓存。其他方法采用CPU-GPU异构执行策略,通过策略性地在CPU上执行计算来减轻数据传输开销[393, 593, 619]。
5.2.5 推测性解码
在长输出场景中,解码阶段成为整体推理时间的主导因素。贪婪解码需要为每个新词元计算传输模型参数。另一方面,推测性解码通过在单次传递中生成多个潜在词元并一起处理它们来加速此过程,从而减少从HBM向计算单元传输模型参数的频率。具体来说,推测性解码[269]由一个较小的草稿模型和一个较大的目标模型组成,其核心思想是:(1)草稿模型生成$γ$个候选词元。(2)目标模型同时验证这$γ$个词元。(3)目标模型要么生成第一个被拒绝的词元,要么在所有先前的词元都被接受时添加一个新词元。自推测性解码[115, 186, 641]利用层跳过技术,使用目标模型本身作为草稿模型,从而减少了维护一个独立草稿模型相关的开销。这种方法有时允许草稿模型和最终模型共享KV缓存[115],进一步优化资源使用。MagicDec[52]和TRIFORCE[477]使用一个带有固定KV预算的草稿模型,并使用稀疏注意力。Medusa[39]和Eagle[295]在目标模型之后引入了额外的训练头,以直接预测接下来的几个词元。关于推测性解码的更多细节可以在本综述[575]中看到。
6. 评估
本节介绍长上下文模型的评估。我们通常将长上下文建模的能力分为两个方面:处理长输入和生成长输出,即长上下文理解和长格式生成。
对于长上下文理解,我们将首先介绍其评估范式(第6.1.1节),然后总结最近的基准(第6.1.2节),并讨论如何为长上下文理解设计更好的基准(第6.1.3节)。对于长格式生成,我们将首先回顾其定义并介绍代表性的基准(第6.2.1节)。然后,我们总结数据源(第6.2.2节)并介绍常用的评估方法(第6.2.3节)。之后,我们讨论长格式生成的挑战和趋势(第6.2.4节)。
6.1 评估长上下文理解
6.1.1 评估范式
本节介绍了长上下文理解的评估范式。如图7所示,我们将LCLMs处理长输入的能力分为五个层级:语言建模、检索、聚合、推理和真实世界适应。基础是语言建模,这是理解输入文本最基本的能力。在此基础上,检索、聚合和推理构成长文本建模的核心能力。对于这三种能力中的每一种,我们都提供了一个详细的分类以及专门为评估每个方面而设计的相应合成任务。在最高层次,真实世界适应考察了LCLMs在实际场景中利用其长上下文能力的程度。具体来说,我们详细介绍了最具代表性的长上下文任务,包括问答、摘要、文档检索与重排、检索增强生成、多示例上下文学习、编码等。这些任务上的性能是评估LCLMs长文本理解能力最重要的指标之一。
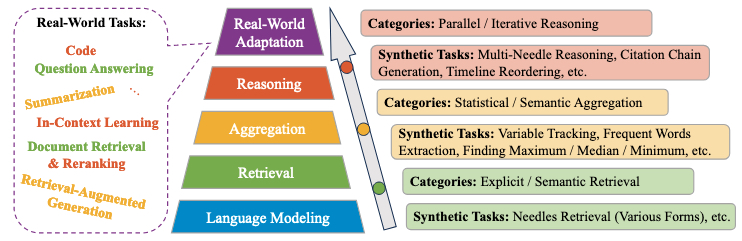
图 7. 长上下文理解的评估范式。
语言建模 语言建模是长上下文理解最基本的能力。通常,低困惑度是模型对给定输入文档有良好理解的指标。在长上下文建模领域,不仅要求LCLMs具有整体较低的困惑度,而且要求随着上下文窗口的增长,这种困惑度会下降,这表明模型可以通过充分利用丰富的上下文信息来更准确地预测目标词元。在实践中,有两种常见的方法可以通过困惑度的视角来检验LCLMs的功效。第一种方法是检查随着长文档中词元位置的增加,累积平均负对数似然(NLL)的变化,如Gemini-1.5[499]所示。这种累积NLL的下降趋势表明,随着上下文窗口的增长,模型可以更好地预测未来的词元。另一种方法是检查在不同窗口大小下通过滑动窗口方法[60, 408, 686]计算的PPLs。具体来说,滑动窗口方法有一个预定义的窗口大小$w$。模型首先预测开始的$w$个词元的概率,然后逐渐向前滑动窗口以处理剩余的词元并计算整体PPL。在这种情况下,随着窗口大小的增加,PPL的下降表明模型可以有效地利用长上下文信息。
检索 检索要求LCLMs从长上下文中的一个或多个位置识别和提取目标信息。这种能力是大多数长上下文任务的基础,因为它们通常需要在后续处理之前隐式地检索相关内容。
- 类别 检索能力根据其复杂性包括两个不同的层次:显式检索和语义检索。显式检索指的是基于给定查询的字符串匹配,模型必须从源文本中定位和提取匹配的内容。语义检索通常更具挑战性,要求模型根据查询的语义含义提取语义相关的内容。
- 合成任务 大海捞针(Needle Retrieval,或Needle-in-a-Haystack, NIAH)是评估检索能力的原型合成任务。该任务将一个或多个“针”插入到一个长序列中,并查询模型以检索相应的针[17, 189, 236, 274, 282, 313, 370, 429, 586, 688]。针和文档的具体实例化形式各不相同。针可以是n位数字、特定句子、UUID、字典、函数、段落等,而文档可以是重复的嘈杂句子、从论文、代码库或其他来源提取的有意义的内容。与能力分类一致,针检索任务包括显式和语义变体。在显式(或字面)针检索中,模型只需执行针的精确匹配,例如在长文本中定位一个部分句子的完成[189, 236, 274, 282, 370]。然而,语义针检索要求模型根据语义对应来识别内容[369],例如根据摘要检索段落[17, 688]或根据其行为描述检索函数[313]。值得注意的是,虽然这些针检索任务主要评估检索能力,但它们可能非常具有挑战性,因此可作为评估长上下文建模能力的关键任务。
聚合 聚合指的是模型从多个位置甚至全局范围内整合信息的能力。在检索能力的基础上,这项能力包括两个关键方面:首先,它要求模型逐段处理文本,跨越多个位置甚至整个上下文;其次,它要求模型识别这些片段之间的有意义的联系,并将它们合成为连贯的更高层次的表示。
- 类别 根据聚合目标的不同,聚合可以进一步分为两种类型:统计聚合和语义聚合。统计聚合要求模型在长上下文中进行定量分析,而语义聚合则侧重于组合和综合来自上下文不同部分的语义信息。
- 合成任务 已经提出了各种合成统计任务来评估统计聚合能力[189, 467, 653]。这些任务包括跟踪变量状态、提取频繁模式、计算描述性统计(例如,最大值、中位数、众数)以及在扩展序列上执行其他数值操作。对于语义聚合,SummHay[258]要求LCLMs处理合成的文档“干草堆”并生成摘要。此外,一些合成任务专门侧重于评估模型在长上下文中的逐段处理能力,例如堆叠新闻标签[416]和堆叠错别字检测[416]。
推理 长上下文推理指的是LCLMs在分布于长上下文中的信息上进行逻辑推断的能力。虽然推理和聚合都涉及识别和处理多条信息,但推理更强调逻辑推导和推断过程,而不仅仅是信息收集和总结。
- 类别 在长上下文理解的领域中,推理可以进一步分为并行推理和迭代推理。并行推理涉及在进行推理过程之前首先收集所有相关信息,而迭代推理则需要一个逐步的方法,其中每个推理步骤都为下一个信息收集目标提供信息,形成一个连续的循环,直到达到最终结论。
- 合成任务 在这方面,多针推理作为一个原型合成任务,强调并行推理和迭代推理能力。它要求模型在分布于长文档中的多个针之间进行推理[254, 282]。这些针通常是从现有推理基准中提取的逻辑相关的-事实。例如,BABILong基准[254]使用bAbI数据集[551]中的样本作为针,而NeedleBench[282]则选择R4C数据集[205]。
真实世界适应 真实世界适应代表了长上下文理解能力层级的最高水平,模型必须有效地整合和应用其基本能力(语言建模)和核心能力(检索、聚合和推理)来应对实际挑战。与在受控环境中评估特定能力的合成任务不同,真实世界任务呈现出复杂的场景,通常需要多种能力协同工作。这些任务不仅测试模型的个体能力,还测试它们根据任务需求适当组合和部署这些能力的能力。下面介绍了最具代表性的涉及长上下文理解的真实世界任务。对于每个任务,我们使用星号来表示任务更倾向于依赖三种核心能力中的哪一种——检索1️⃣、聚合2️⃣和推理3️⃣。
- 问答 [1️⃣/2️⃣/3️⃣] 问答任务要求模型根据真实世界的长上下文和查询提供准确的答案。这些问题和上下文涵盖了不同的领域,包括文学(NarrativeQA[245]、QuALITY[391]、LStQA[416]、NoCha[239])、学术论文(Qasper[94])、百科全书(WikiQA[606]、HotpotQA[608]、2WikiMultihopQA[183]、DuReader[176]、AltQA[389])、对话历史(LCvMem[416])、财务报告(DocFinQA[425])、结构化数据(Table QA[651])、混合场景(MultiFieldQA[17])等。值得注意的是,由于问题和领域的多样性,不同的QA任务可能强调长上下文能力的不同方面——一些主要需要信息检索,另一些侧重于跨多个部分的信息聚合,还有一些则要求在聚合信息上进行复杂的推理。
- 摘要 [2️⃣] 从长文本序列中总结关键信息长期以来一直是NLP中的一个关键研究领域。随着该领域的发展,研究人员已经创建了涵盖几乎所有相关领域的各种摘要数据集,包括小说([653]、LStSum[416]、SQuALITY[518])、政府报告(GovReport[195])、会议脚本(QMSum[674]、VCSUM[559])、新闻文章(MultiNews[117])、专利(BigPatent[450])、剧本(SummScreen[59])、法律文件(MultiLex-Sum[452])等。值得注意的是,长上下文摘要也是长上下文模型的主要应用场景之一。
- 文档检索与重排 [1️⃣/3️⃣] 文档检索与重排是现代信息检索(IR)系统的关键组成部分,负责从候选池中检索相关文档并根据它们与查询的相关性进行重新排序。LCLMs的出现催生了一种新的范式,模型可以直接处理所有候选文档并以生成的方式产生它们的排名[346, 481, 531]。反过来,检索和重排性能可以作为这些模型长上下文能力的指标,前者强调检索相关信息的能力,后者侧重于在长上下文的不同部分之间进行推理[262, 616]。例如,HELMET基准包括一个重排测试,其中候选文档从MSMARCO[380]检索数据集中采样,LCLMs面临着生成按相关性排名的前10个文档ID的挑战。除了基于相关性的重排,该任务还包括更广泛的序列组织形式,如时间线排序[277, 534, 643]和段落顺序重建[107]。
- 检索增强生成 [2️⃣] 检索增强生成通过向生成模型提供从外部来源检索到的事实语料库来提高其准确性和可靠性。在长上下文场景中,输入语料库可以扩展到1M词元[262],相关信息变得更加分散和稀疏,挑战了LCLMs在扩展上下文中聚合信息的能力。现有的评估方法[262, 616]主要采用开放域QA来评估LCLMs在检索增强生成中的性能。这些评估通常处理开放域QA数据集,如Natural Questions[256]、TriviaQA[232]和HotpotQA[608],通过将它们的段落连接成一个大语料库。模型输入由这个语料库和针对特定段落的查询组成,要求LCLMs在扩展语料库中定位相关信息以生成适当的答案。
- 上下文学习 [3️⃣] 随着上下文窗口大小的扩展,上下文学习(ICL)将演示示例的规模从传统ICL框架中的几十个扩展到几百甚至几千个。这种场景挑战了LCLMs基于这个大得多的示例集生成精确预测的能力[28, 262, 288, 591]。最近的实证研究表明,现有的LCLMs在这种设置下表现出一些限制:它们在超过特定上下文长度后表现出显著的性能下降,显示出对示例排序效应的敏感性,通过偏爱与序列末端呈现的标签对齐的预测来显示新近度偏见等[288, 591]。这些发现表明,LCLMs要完全释放ICL的潜力还有很长的路要走。
- 代码相关真实世界任务 [3️⃣] 处理仓库级代码代表了一个特别引人注目的应用场景,需要LCLMs。在各种具体任务中,代码补全因其全面反映了模型处理整个仓库的能力而获得了显著关注[30, 224, 321, 634]。此外,一些任务解决了仓库级代码处理中的其他潜在挑战,包括CI构建修复、提交消息生成、错误定位、模块摘要、执行模拟、代码翻译等[30, 544, 653]。尽管取得了显著进展,但仓库级代码的内在复杂性仍然对当前LCLMs在满足真实世界代码处理需求方面构成重大挑战,正如它们在SWE-Bench[224]上的性能限制所证明的那样。
6.1.2 评估基准
遵循第6.1.1节建立的评估范式,我们对最近的长上下文理解基准进行了全面概述。这些基准可分为两组:合成基准(表6),完全使用启发式规则构建;以及真实世界基准(表7),主要由带有人工标注的真实世界任务组成。对于每个基准,我们都提供了其支持的长度(最大词元数)、特征、评估设置和评估指标。评估设置包括四种主要格式:带选项的多项选择题、自由形式生成、分类和语言建模。评估指标包括自动指标、LLM-as-a-Judge方法和结合两者的混合方法。此外,对于合成基准,我们标注了它们对长上下文理解能力的特定方面的重点,因为这些人工任务通常旨在测试特定的理解技能。对于真实世界基准,我们记录了它们涵盖的场景,包括问答、摘要、文档检索与重排、检索增强生成、上下文学习、代码相关任务和各种合成任务。
根据表6,我们对现有的合成基准做出了一些观察。首先,合成基准的很大一部分由各种NIAH任务变体组成,具有更复杂的形式或不同的领域,本质上是评估模型长上下文检索能力的鲁棒性。其次,大多数合成基准仅依赖于准确率和F1分数等自动指标,只有少数需要LLM或混合评估。
表 6. 长上下文理解合成基准概览。
Support Length是基准中样本的最大词元数(k=2¹⁰, m=2²⁰)。Characteristics描述了基准的独特特征。Target Aspects表示基准旨在评估的核心长上下文能力,包括检索1️⃣、聚合2️⃣和推理3️⃣。Eval Setup表示基准采用的评估格式:M代表多项选择题,G代表自由形式生成,C代表分类。Metrics列出了基准中使用的评估指标,包括自动指标(Auto)、LLM-as-a-Judge方法(LLM)和结合两者的混合风格(Hybrid)。
| 基准 | 支持长度 | 特征 | 目标方面 | 评估设置 | 指标 |
|---|---|---|---|---|---|
| 通用领域合成基准 | |||||
| Ada-LEval [521] | 128k | 适应性长度 | 2️⃣3️⃣ | M G | Auto |
| BABILong [254] | 10m | 长上下文中的BAbI | 3️⃣ | G | Auto |
| DENIAHL [88] | 4k | 不同的NIAHs | 1️⃣ | G | Auto |
| HoloBench [349] | 64k | 数据库聚合与推理 | 2️⃣3️⃣ | G | Auto |
| LIFBENCH [567] | 128k | 指令遵循与稳定性,新指标 | 1️⃣2️⃣3️⃣ | G | Auto |
| LongIns [137] | 16k | 以指令为中心 | 1️⃣2️⃣3️⃣ | G | Auto |
| LongPiBench [508] | 256k | 关注位置偏差 | 1️⃣2️⃣3️⃣ | G | Auto |
| LongRangeArena [495] | 16k | 早期尝试,多模态 | 1️⃣2️⃣3️⃣ | C | Auto |
| LongReason [305] | 128k | 长上下文推理 | 3️⃣ | M | Auto |
| mLongRR [5] | 64k | 多语言检索与推理 | 1️⃣3️⃣ | G | Auto |
| M4LE [255] | 8k | 双语,半现实 | 1️⃣2️⃣3️⃣ | M G | Auto |
| Michelangelo [514] | 128k | 潜在结构查询 | 2️⃣3️⃣ | G | Auto |
| MLNeedle [180] | 32k | 多语言NIAH | 1️⃣ | G | Auto |
| NeedleThreading [429] | 900k | 不同的NIAHs | 1️⃣2️⃣ | G | Auto |
| NoLiMA [369] | 32k | 词汇重叠最小的语义NIAHs | 1️⃣ | G | Auto |
| RULER [189] | 128k | 不同的NIAHs + 其他合成任务 | 1️⃣2️⃣ | G | Auto |
| S3Eval [266] | 80k | 以SQL为中心 | 1️⃣2️⃣3️⃣ | G | Auto |
| SummHay [258] | 100k | 用于摘要的合成任务 | 2️⃣ | G | LLM |
| 特定领域合成基准 | |||||
| LongHealth [4] | 8k | 医学,虚构病人案例 | 1️⃣2️⃣ | M | Auto |
| MathHay [528] | 128k | 数学检索与推理 | 1️⃣3️⃣ | G | Hybrid |
| RepoQA [313] | 16k | 代码风格的NIAH | 1️⃣ | G | Auto |
表 7. 长上下文理解真实世界基准概览。
Support Length是基准中样本的最大词元数。Characteristics描述了基准的独特特征。Scenarios表示每个基准涵盖的真实世界任务类型:问答1️⃣,摘要2️⃣,文档检索与重排3️⃣,检索增强生成4️⃣,上下文学习5️⃣,代码相关任务6️⃣,以及合成任务S。Eval Setup表示基准采用的评估格式:M代表多项选择题,G代表自由形式生成,L代表语言建模。Metrics列出了基准中使用的评估指标,包括自动指标(Auto)、LLM-as-a-Judge方法(LLM)和结合两者的混合风格(Hybrid)。
| 基准 | 支持长度 | 特征 | 场景 | 评估设置 | 指标 |
|---|---|---|---|---|---|
| 通用领域真实世界基准 | |||||
| BAMBOO [107] | 16k | 多任务 | 1️⃣ 6️⃣ S | M G L | Auto |
| CLongEval [416] | 100k | 中文,人工策划(部分) | 1️⃣ 2️⃣ S | G | Auto |
| DetectiveQA [592] | 250k | 双语,人工策划,侦探小说 | 1️⃣ | M | Auto |
| ETHIC [264] | 100k | 要求高信息覆盖 | 1️⃣ 2️⃣ S | G | Hybrid |
| InfinityBench [653] | 100k | 双语,长平均长度 | 1️⃣ 2️⃣ 6️⃣ S | G | Auto |
| HELMET [616] | ∼128k | 应用为中心,鲁棒评估 | 1️⃣ 2️⃣ 3️⃣ 4️⃣ 5️⃣ S | M G | Auto |
| L-CiteEval [494] | ∼48k | 带引用的回答(忠实性) | 1️⃣ 2️⃣ S | G | Auto |
| L-Eval [10] | 200k | 多样化数据,改进指标 | 1️⃣ 2️⃣ | G | Hybrid |
| LIBRA [84] | 128k | 俄罗斯语长基准 | 1️⃣ S | G | Auto |
| LOFT [262] | 1m | 极长真实任务 | 3️⃣ 4️⃣ 5️⃣ S | M G | Auto |
| Long2RAG [410] | 32k | 长检索与输出 + 新指标 | 4️⃣ | G | Auto |
| LongBench [17] | 16k | 双语,应用为中心 | 1️⃣ 2️⃣ 5️⃣ 6️⃣ S | G | Auto |
| LongBench-v2 [20] | ∼2m | 挑战性任务,专家策划 | 1️⃣ 5️⃣ 6️⃣ | M | Auto |
| LongBench-Cite [637] | 70k | 带引用的QA(可信度) | 1️⃣ 2️⃣ 6️⃣ | G | Auto |
| LongICLBench [288] | 50k | 极端标签分类 | 5️⃣ | M G | Auto |
| LongMemEval [558] | 1.5m | 长期聊天记忆 | 1️⃣ | G | Hybrid |
| Loong [534] | 250k | 双语,半现实,人工策划 | 1️⃣ 3️⃣ S | G | LLM |
| LooGLE [277] | ∼24k | 人工策划,长依赖 | 1️⃣ 2️⃣ S | G | Hybrid |
| LV-Eval [628] | 256k | 适应性长度,减少知识泄露 | 1️⃣ | G | Auto |
| ManyICLBench [693] | 128k | 广泛的ICL测试,新指标 | 5️⃣ | M G | Auto |
| Marathon [643] | ∼80k | 人工策划,多项选择QA | 1️⃣ 3️⃣ S | M | Auto |
| NoCha [239] | 336k | 跨整部小说的全局推理 | 1️⃣ | G | Auto |
| TCELongBench [660] | ∼12k | 时间复杂事件 | 1️⃣ 3️⃣ | M G | Auto |
| ZeroSCROLLS [443] | 8k | 早期尝试 | 1️⃣ 2️⃣ S | G | Auto |
| 特定领域真实世界基准 | |||||
| DocFinQA [425] | ∼200k | 金融,长上下文中的FinQA | 1️⃣ | G | Auto |
| FinTextQA [53] | 30k | 金融 | 1️⃣ 4️⃣ | G | Hybrid |
| LongCodeArena [30] | 2m+ | 以代码为中心 | 6️⃣ | G | Auto |
| MedOdyssey [119] | 200k | 医学,多样任务,新指标 | 1️⃣ S | G | Auto |
| NEPAQuAD1.0 [404] | 600k | 环境声明与法案 | 1️⃣ | G | Hybrid |
对表7的分析揭示了真实世界基准中的几个模式。首先,问答成为最普遍的场景,这与QA任务固有的多样性相符,其次是摘要任务。其次,一些真实世界基准采用多项选择QA格式来引导模型生成,这可能是由于真实世界任务输出的多样性,无约束的生成可能会使评估复杂化。第三,有趣的是,并非所有真实世界基准都完全依赖于人工标注;许多基准也包含了合成任务,这可能是为了确保全面的评估覆盖。
此外,综合考察合成和真实世界基准共同揭示了,医学、金融和代码相关领域尤其需要强大的长上下文处理能力。
6.1.3 讨论
什么构成了好的长上下文理解基准? 从高层次来看,一个有效的长上下文理解基准应满足三个关键要求:覆盖与模型上下文窗口相匹配的样本长度,评估基本的长上下文建模能力,以及评估下游任务性能。鉴于当前LCLMs的上下文窗口通常超过128k词元,主要关注32k词元以下文档的基准可能无法充分评估主流LCLMs的能力。对于基本能力,包括如第6.1.1节所讨论的检索、聚合和推理,主要挑战在于关键信息的分散性和提取的难度[151],其中更分散和语义导向(而非字面)的信息构成了更大的挑战[369]。尽管合成任务特别适合评估这些方面,但研究表明,仅在合成任务上表现出色并不能保证下游任务的能力。因此,全面的基准必须包含特定的下游长上下文任务,特别是问答、摘要、RAG和上下文学习,这些任务可以作为真实世界应用的相对完整的代理。评估方法论中一个最后值得注意的趋势是,越来越多地将任务制定为多项选择问答,从而可以通过准确率测量直接进行性能评估。
6.2 评估长格式生成
除了长上下文理解(输入长),长上下文建模的另一个常见范式是长格式生成(输出长)。长格式生成是NLP领域的经典任务[32, 80, 556]。在LLMs领域,对文档级文本生成[341, 513, 624]和仓库级代码补全[315, 520]的实际需求日益增长,这引起了对长格式生成的广泛关注,导致了几个评估基准和改进方法的出现[21, 418]。在本小节中,我们首先回顾长格式生成的定义并介绍代表性的基准。然后,我们总结数据源并介绍常用的评估方法。之后,我们讨论长格式生成的挑战和趋势。长格式生成的概览如图8所示。
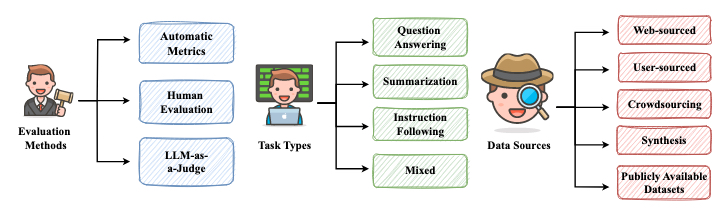
图 8. 评估长格式生成的概览。
6.2.1 评估基准
长格式生成通常被定义为针对给定输入或指令生成长篇、连贯且与上下文相关的文本。为了更好地理解长格式生成的范围,我们提供以下澄清:
首先,指令必须明确或隐式地指示需要一个长响应。明确要求指的是指令清晰地指明了对长响应的期望,无论是通过指定的字数还是直接的声明。相比之下,隐式要求不指定期望的长度,而是源于那些本身就需要详细响应的任务。例如,开放式问题通常需要全面的例子或深入的讨论来有效地传达一个观点,自然导致比封闭式问题更长的响应。
其次,“长”响应的定义因任务性质而异。在写作任务的背景下,如果一个响应超过1000个词,通常被认为是长的,而在问答任务中,如果一个响应超过500个词,就可能被认为是长的。因此,长格式生成可以被定义为需要响应大大超过与特定任务类型相关的平均长度的任务。
表8列出了长格式生成的代表性基准。我们将长格式生成的任务类型分为四类:问答(QA)、摘要(Summ)、指令遵循(IF)和混合型。
问答(QA) 在长格式生成中,QA主要指的是长格式QA。ELI5[118]是第一个大规模的长格式QA基准,其任务是针对源自Reddit的开放式问题生成多句解释。类似地,MS-NLG是MS MARCO[380]的一个子集,专注于自然语言生成。除了通用的长格式QA,ASQA[472]和QASA[265]分别关注模糊问题和科学问题。在LLMs领域,ExpertQA[351]和ProxyQA[486]是高质量的长格式QA基准,其问题由各领域专家精心设计,并附有专家验证的黄金答案。检索增强生成(RAG)是LLMs的一个重要应用,CLAPNQ[431]和Long2RAG[410]是为评估基于LLM的RAG系统而设计的基准。此外,生成长格式且有充分支持的响应在高风险领域尤其重要,如医学[188, 212]。尽管LLMs在许多任务中表现出色,但它们在生成长响应时常常包含事实错误[549]。Min等人[365]提出了一个新颖的事实性评估框架,包括三个步骤:将响应分解为原子事实,将每个事实标注为支持、不支持或不相关,以及计算支持事实的比例。除了与事实性相关的问题,长格式响应也容易受到偏见的影响。为了评估长格式生成中的公平性,Jeung等人[213]提出了一个评估框架,涵盖14个主题和10个人口统计轴。
摘要(Summ) 摘要是长上下文建模中的一个经典任务。随着输入文档数量越来越多、越来越长,摘要的长度也显著增加。与早期摘要基准中摘要长度约为50个词[377]相比,最近的摘要基准具有更长的摘要。因此,摘要不仅评估模型理解和浓缩长输入文档的能力,还测试其生成长格式摘要的能力。Multi-News[117]是第一个大规模的多文档新闻摘要基准,从newser.com收集。AQUAMUSE[251]提出了一种可扩展的方法,从Natural Questions[256]和Common Crawl中自动挖掘摘要。LCFO[87]是一个人工标注的基准,用于评估长上下文摘要和摘要扩展,由来自不同领域的252个长文档组成。
指令遵循(IF) 除了使用问题作为LLMs的输入,指令和其他形式的提示也可以作为输入。这类任务优先评估模型遵循指令的能力,涵盖了直接的指令遵守和更复杂的、受约束的指令遵循。为了评估LLMs在结构化问题解决中的能力,DoLoMiTes[352]由519个领域特定的长格式方法性任务组成,包含从25个领域的专家那里收集的1857个例子。类似地,LongGenBench-NUS⁶[568]和LongProc[615]旨在评估LLMs在遵守复杂指令的同时生成高质量长格式文本的能力。此外,LongLaMP[252]是一个用于个性化生成的基准,涵盖四个任务:个性化邮件补全、摘要生成、评论写作和主题写作。最近,人们越来越关注将LLMs与长格式输出指令对齐,如创意写作和故事生成。为了增强长格式生成的指令微调,LongForm-C[247]通过在C4和英文维基百科上进行反向指令来收集指令遵循的例子。Bai等人[21]提出了一个长的指令遵循数据集LongWriter-6K,旨在将现有模型的输出长度扩展到超过10,000个词。类似地,Suri[403]是一个由20,000个长格式人类书写文本组成的基准,每个文本都配有带有多个约束的反向翻译指令。Quan等人[417]提出了Self-Lengthen,这是一个利用LLMs内在知识而无需依赖辅助数据的迭代训练框架。为了评估其有效性,他们引入了LongGen,一个用于在中文和英文中跨多种任务评估LLMs长格式生成能力的基准,带有长度约束的用户指令和相应的响应。
混合型 一些基准包括多种任务类型以实现更全面的评估。Facts Grounding[210]评估LLMs基于给定上下文和用户请求生成事实准确的长格式文本的能力,涵盖QA、摘要和文档重写任务。HelloBench[418]是一个用于评估LLM长格式生成能力的综合基准,由来自真实世界场景和公开可用数据集的38个子类别和5个任务(QA、摘要、聊天、补全、生成)的647个样本组成。
⁶事实上,有两个名为LongGenBench的基准[324, 568]。为了区分它们,我们加上了各自主要机构的后缀。
| 基准 | 大小 | 任务 | 目标方面 | 来源 | 评估方法 |
|---|---|---|---|---|---|
| ELI5 [118] | 272K | QA | 通用 | Web | Auto, Human |
| MS-NLG [380] | 183K | QA | 通用 | User | Auto |
| ExpertQA [351] | 2K | QA | 通用 | CrowdSrc | Auto |
| ProxyQA [486] | 100 | QA | 通用 | CrowdSrc | LLM |
| LongGenBench-HUST [324] | 16K | QA | 通用 | PADs | Auto |
| ASQA [472] | 6K | QA | 模糊 | PADs | Auto, Human |
| QASA [265] | 2K | QA | 科学 | CrowdSrc | Auto |
| CLAPNQ [431] | 5K | QA | RAG | PADs | Auto, Human |
| Long2RAG [410] | 280 | QA | RAG | PADs | Auto |
| LFMedQA [188] | 1K | QA | 医学 | User | LLM |
| MedLFQA [212] | 5K | QA | 医学 | PADs | Auto |
| FActScore [365] | 183 | QA | 事实性 | Web | LLM |
| LongFact [549] | 1K | QA | 事实性 | Synthesis | LLM |
| LTF-TEST [213] | 12K | QA | 公平性 | Synthesis | LLM |
| AQUAMUSE [251] | 6K | Summ | 通用 | Web, PADs | Auto, Human |
| Multi-News [117] | 56K | Summ | 通用 | Web | Auto, Human |
| LCFO [87] | 252 | Summ | 通用 | PADs | Auto, LLM, Human |
| LongForm-C [247] | 28K | IF | 通用 | PADs | Auto |
| Suri [403] | 20K | IF | 通用 | PADs | Auto, Human |
| LongBench-Write [21] | 120 | IF | 写作 | User | Auto, LLM |
| LonGen [417] | 240 | IF | 写作 | User | Auto, LLM |
| LOT-OutGen [160] | 2K | IF | 写作 | Web | Auto, Human |
| LongLaMP [252] | 63K | IF | 个性化 | PADs | Auto |
| DoLoMiTes [352] | 2K | IF | 结构化 | Web | LLM |
| LongGenBench-NUS [568] | 400 | IF | 结构化 | Synthesis | Auto |
| LongProc [615] | 2K | IF | 结构化 | PADs | Auto |
| HelloBench [418] | 647 | Mixed | 通用 | Web, PADs | LLM, Human |
| FACTS Grounding [210] | 2K | Mixed | 事实性 | CrowdSrc | LLM |
表 8. 长格式生成的代表性基准。 Web指网络来源数据,User指真实用户数据,CrowdSrc指众包数据,PADs指公开可用数据集,Synthesis指合成数据。Auto指自动评估指标,Human指人工评估,LLM指基于LLM的评估(LLM-as-a-Judge)。
6.2.2 数据源
基准的数据来源决定了其数据质量。一个合理、高质量且易于获取的数据源可以显著提高基准的整体质量。长格式生成基准的数据来源可分为五类:
- 网络来源数据(Web-Sourced Data):网络包含丰富和大量的文本内容。网络来源数据的优势在于其丰富性和多样性。然而,并非所有网络内容都符合高质量标准,通常需要数据清洗和去重等过程。在长格式生成基准中,ELI5[118]从Reddit收集QA对,FActScore[365]从维基百科收集人物传记,LOT-OutGen[160]通过爬取网页收集人类书写的故事。
- 用户来源数据(User-Sourced Data):用户来源数据的主要特点是其实用性,因为它反映了用户面临的真实世界场景。例如,MS-NLG[380]从Bing的用户搜索日志中收集数据。LongBench-Write[21]、LonGen[417]和LFMedQA[188]分别从其各自的平台GLM、Qwen和Lavita Medical AI Assist收集用户数据。
- 合成数据(Synthetic Data):合成数据也是构建基准的常用方法。这种方法指的是预定义一个模板,然后用不同的内容填充它,以实现结构和多样性。内容可以是预定义的,也可以是AI生成的。像LongFact[549]、LTF-TEST[213]和LongGenBench-NUS[568]这样的基准都是用这种方法构建的。
- 众包(CrowdSrc):数据收集过程通常不是自动化的,需要人工参与以确保数据质量。ExpertQA[351]、ProxyQA[486]和QASA[265]从专家那里收集问题。具体来说,ExpertQA通过Prolific招募专家在其专业领域内编写问题。ProxyQA手动创建元问题,并借助五位经验丰富的研究人员。QASA涉及AI/ML研究人员来标记数据。同时,FACTS Grounding[210]指导第三方人工评分员设计需要处理长格式输入和生成长格式输出的提示。
- 公开可用数据集(PADs):“站在巨人的肩膀上”也是一种有效的数据收集策略。一方面,以前数据集的数据质量通常是可靠的,另一方面,以前的数据集通常表现出一致性,使其更易于处理和适应。许多长格式生成基准从公开可用数据集中获取数据。例如,LongGenBench-HUST[324]从MMLU[179]、GSM8K[85]和CommonSenseQA[485]收集数据。ASQA[472]从AMBIGQA[364]获取数据。Long2RAG[410]从ELI5获取数据。
6.2.3 评估范式
评估方法对于基准至关重要,因为一个合适的评估方法可以为评估不同模型的性能提供一个统一的标准,突出它们的优缺点,并指导模型迭代。评估长格式生成的性能提出了重大挑战。在这里,我们总结了现有长格式生成基准中使用的评估方法,并将它们分为三类,为未来评估方法的发展提供见解。
自动指标 自动指标是评估模型生成响应而无需额外人工参与或使用LLMs的评估方法。大多数传统指标被归类为自动指标。在长格式生成领域的现有自动指标可分为四类:
- 语义方面:这类指标评估响应的语义方面。像ROUGE[303]和BLEU[392]这样的指标是最常用的,最初是为摘要任务和机器翻译任务开发的。ROUGE和BLEU通过测量响应和参考答案之间的语义相似性,提供了LLMs生成质量的指示。它们在28个基准中的13个中被用作评估指标。类似地,METEOR[23]也用于测量语义相似性,并在LongForm-C[247]和LongLamp[252]中应用。此外,BERTScore[648]是一个使用微调的BERT模型[212]评估两个文本语义相似性的指标。
- 重复性方面:这些指标评估响应的重复性或流畅性。例如,困惑度(PPL)[301]计算响应的整体概率。较低的困惑度表示较高的流畅性,并表明句子更可能由LLM生成。像Repetition[448]和Distinct[279]这样的指标用于测量重复性。Repetition-n计算文本中至少出现两次的n-grams的百分比,而Distinct-n通过计算输出中唯一的n-grams的数量来量化文本多样性。这些指标在LOT-OutGen[160]和LCFO[87]中使用。
- 基于准确率:准确率在多项选择QA等短格式生成场景中更常用。在长格式生成中,LongGenBench-HUST[324]将多个问题组合成一个单一输入,要求模型为所有问题生成响应。每个响应都与一个相应的标准答案(一个特定选项或一个数字)配对,使其非常适合基于准确率的评估。Wu等人[568]提出了CR和STIC指标,两者都旨在测量特定方面响应的准确性。此外,QASA[265]使用标准准确率作为评估指标。
- 任务特定:由于不同基准的重点不同,通常会使用任务特定的指标。例如,ExpertQA[351]使用QAFactEval[116]来评估响应的事实一致性,而ASQA[472]使用Disambiguation Metrics来评估响应是否解决了歧义。在CLAPNQ和Long2RAG中,使用像nDCG[431]和KPR[410]这样的检索导向指标来评估基于LLM的RAG系统的有效性。
人工评估 尽管自动指标很方便,但最近的研究表明,自动指标和人工评估之间的相关性相当低[250, 588]。为了实现更准确的评估,最好的方法是建立标准化的评估标准,并让人类评估员评估LLMs的响应[432]。ELI5[118]、ASQA[472]、Long2RAG[410]、AQUAMUSE[251]、Multi-News[117]、LongForm-C[247]、LongBench-Write[21]、LOT-OutGen[160]和HelloBench[418]都进行了涉及人工评估的实验或提供了人工评估标准。
LLM-as-a-Judge 人工评估的主要缺点在于其耗时、劳动密集和低效。最近,使用表现强劲的LLMs来替代人类进行细粒度评估的趋势越来越明显[672]。这种策略也被称为LLM-as-a-Judge。在ProxyQA[486]中,LLMs被用来评估对代理问题的响应是否正确。在LFMedQA[212]中,GPT-4o和Claude-3.5被用于成对比较。在HelloBench[418]中,为每个子任务设置了预定义的检查表,LLM确定每个检查表是否被满足。总分是使用与人类相关的权重计算的。
6.2.4 讨论
哪种数据源更好? 数据源为基准的质量奠定了基础。在第6.2.2节中,我们将长格式生成的数据来源分为五类:网络来源数据、用户来源数据、合成数据、PADs和众包。网络来源数据在规模和可访问性方面具有优势,但通常质量较低。同样,虽然用户来源数据直接从用户那里获得,但其质量也可能差异很大。合成数据具有使评估更容易的优势,因为它允许使用具有高评估准确性的自动指标。然而,这类数据通常与真实世界场景不符。以前可用的数据集存在数据泄露等风险。虽然众包提供高质量的数据,但它可能仍然偏离实际用例。很明显,每个数据来源都有其局限性。那么,哪种数据可以被认为是好的长格式生成数据呢?我们认为,结合了详细后处理的用户来源数据是未来研究的一个有希望的方向。具体来说,LLMs的优化目标是服务用户,这使得理解用户遇到的真实问题至关重要。因此,直接从用户那里获得第一手交互数据是理想的。然而,用户来源数据通常包含低质量的样本,使得数据过滤成为首要任务。我们相信,在数据后处理阶段的人工参与对于取得更好的结果至关重要。只要数据质量得到保证,评估样本稍少一些不太可能引入显著的评估偏差。
7. 分析
如图9所示,我们提供了性能分析和模型结构分析,以从外部和内部理解神经网络模型。本节详细回顾了这些工作。
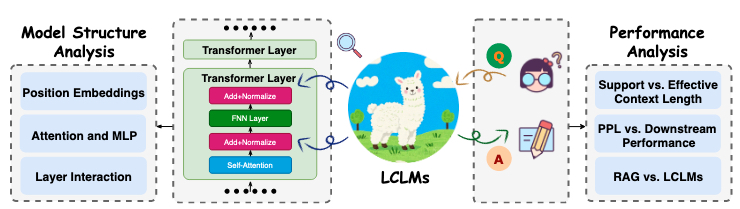
图 9. LCLMs分析示意图。
7.1 性能分析
首先,将LCLMs作为黑箱进行分析,以检验其行为特征。在本小节中,我们将首先深入探讨“支持上下文长度”的虚假承诺,这与众所周知的“中间丢失”现象有关。然后,我们探讨长上下文困惑度和真实世界性能之间的关系。我们还讨论了检索增强生成(RAG)和长上下文建模之间正在进行的辩论。
7.1.1 “支持上下文长度”的虚假承诺
近年来,模型上下文长度取得了显著增长,从4K词元[510]扩展到128K词元[154],甚至10M词元[499]。尽管上下文扩展取得了令人印象深刻的进展,但在模型声称支持的上下文长度和它们能有效处理的实际上下文长度之间存在显著差距[189, 317]。这方面一个特别值得注意的现象是“中间丢失”效应。Liu等人[317]证明,许多LCLMs表现出独特的U形性能曲线:当信息位于输入的开头或结尾时,性能保持稳健,但当关键信息位于中间时,性能会显著恶化。An等人[13]和He等人[174]也观察到,随着相对距离的增加,模型会逐渐失去对目标信息的追踪。为了系统地评估支持和有效上下文长度之间差距的普遍性,RULER[189]对十多个模型进行了全面的评估,包括开源和专有模型,如表9所示。研究结果揭示了一个一致的模式:对于两类中的大多数模型,有效上下文长度很少超过声称长度的一半。这种差异强调,在追求更大的上下文窗口尺寸的同时,提高模型在已支持的上下文长度内的性能同样重要。
| 模型 | 开源 | 声称长度 | 有效长度 | 有效率 |
|---|---|---|---|---|
| Llama2 (7B) | ✓ | 4K | - | - |
| Gemini-1.5-Pro | ✗ | 1M | >128K | >12.8% |
| GPT-4 | ✗ | 128K | 64K | 50% |
| Llama3.1 (70B) | ✓ | 128K | 64K | 50% |
| Qwen2 (72B) | ✓ | 128K | 32K | 25% |
| Command-R-plus (104B) | ✓ | 128K | 32K | 25% |
| GLM4 (9B) | ✓ | 1M | 64K | 6.4% |
| Llama3.1 (8B) | ✓ | 128K | 32K | 25% |
| GradientAI/Llama3 (70B) | ✓ | 1M | 16K | 1.6% |
| Mixtral-8x22B (39B/141B) | ✓ | 64K | 32K | 50% |
| Yi (34B) | ✓ | 200K | 32K | 16% |
| Phi3-medium (14B) | ✓ | 128K | 32K | 25% |
| Mistral-v0.2 (7B) | ✓ | 32K | 16K | 50% |
| LWM (7B) | ✓ | 1M | < 4K | < 4% |
| DBRX (36B/132B) | ✓ | 32K | 8K | 25% |
| Together (7B) | ✓ | 32K | < 4K | < 12.5% |
| LongChat (7B) | ✓ | 32K | < 4K | < 12.5% |
| LongAlpaca (13B) | ✓ | 32K | < 4K | < 12.5% |
表 9. 不同模型声称长度与有效长度的比较[189]。
7.1.2 长上下文困惑度与真实世界性能的关联
除了测量语言建模能力,实证证据表明,语言模型在短文本上的困惑度与其在短文本下游任务上的性能有很强的相关性[200]。具体来说,在短文本的留出集上较低的困惑度分数一致地预测了在下游短文本任务上的优越性能。然而,这种相关性在长上下文场景中变得显著减弱。Hu等人[193]、An等人[10]和Sun等人[479]都观察到,不同模型在长上下文上的困惑度分数与其长上下文理解能力不相关。
最近的工作重新确立了困惑度在评估模型长上下文建模能力中的作用。通过全面的实验,Lu等人[338]证明,当使用各种上下文扩展方法——包括PI[60]、YaRN[401]、NTK[400]、LongLora[68]、Landmark Attention[370]和CLEX[50]——微调单个基础模型(LLaMA2-7B)时,所得模型在GovReport[195]数据集上的困惑度分数与其在长上下文下游任务(包括大海捞针、LongBench和RULER)上的性能表现出显著的相关性。同时,Fang等人[121]引入了LongPPL,这是一种改进的指标,通过仅在上下文敏感的词元分布上计算困惑度来消除与上下文无关的词元的干扰。在这种改进的指标下,模型的长上下文困惑度分数与其长上下文下游性能显示出稳健的相关性。这些研究共同重新确立了困惑度作为长上下文建模能力的有效指标,为未来可靠评估LCLMs提供了有价值的参考。
7.1.3 RAG与长上下文LLMs的相遇
自LCLMs出现以来,它们经常在性能上与检索增强生成(RAG)进行比较。给定一个查询,RAG流程首先从语料库中检索关键信息,然后使用LLM基于这些信息生成答案,而LCLMs则将整个语料库作为输入,在产生答案之前隐式地识别相关信息。Lee等人[262]、Li等人[296]揭示,当有充足的计算资源时,尽管没有为这些任务进行专门训练,LCLMs的平均性能优于RAG。
然而,与RAG相比,直接使用LCLMs基于整个语料库生成响应存在显著的效率限制。因此,当前的研究已从比较RAG与LCLMs转向将这些方法结合起来以取长补短。Li等人[296]提出了Self-Route方法,该方法根据模型的自我评估动态地将查询引导到RAG或LCLMs,从而优化了性能和计算成本之间的平衡。Jiang等人[223]利用LCLMs为RAG获得更大、语义更连贯的检索单元。Jin等人[225]发现“难负例”显著影响基于LCLM的RAG,因此设计了免训练和基于训练的方法来缓解这一挑战。
7.2 模型结构分析
第7.1节将LCLMs作为黑箱进行考察,讨论了支持上下文长度的虚假承诺、长上下文困惑度与真实世界性能之间的相关性,以及LCLMs与RAG之间正在进行的辩论。本节更进一步,从白箱的角度来研究LCLMs,在单个模型组件(例如,位置嵌入、注意力和MLP模块、Transformer层)的粒度上提供更深入的见解,从而阐明驱动长上下文能力的内部工作机制。
7.2.1 位置嵌入
在长上下文建模中,模型的上下文长度越大,下游应用的可能性就越多。然而,模型通常在预训练期间在小型且固定的上下文长度上进行训练。长度外推研究了使模型能够消化比训练分布更长的文本的问题。在本节中,我们回顾了位置嵌入(特别是RoPE[476])如何被扩展以进行长度外推。
RoPE基础 RoPE[476]将词元之间的相对位置明确地编码到注意力中。回想一下,对于一个具有偶数隐藏大小 $d$ 的模型,绝对位置 $n$ 的RoPE嵌入[473]将是: \(\left( \cos\left(\frac{n}{\beta^{\frac{0}{d}}}\right), \sin\left(\frac{n}{\beta^{\frac{0}{d}}}\right), \cos\left(\frac{n}{\beta^{\frac{2}{d}}}\right), \sin\left(\frac{n}{\beta^{\frac{2}{d}}}\right), \dots, \cos\left(\frac{n}{\beta^{\frac{d-2}{d}}}\right), \sin\left(\frac{n}{\beta^{\frac{d-2}{d}}}\right) \right) \quad (10)\) 方程10中的 $\beta$ 是旋转基。三角函数可以与假设的“波长” $\lambda_{2i} = \left( 2\pi\beta^{\frac{2i}{d}} \right){i=0}^{\frac{d}{2}-1}$ 相关联,这指示了模型的上下文容量。对于给定的 $\beta$,波长范围从 $2\pi$ 到 $2\pi\beta$ [401]。$\beta$ 的典型选择是10000[476],产生的最大波长约为63K。与波长相关的假设“频率”是 $f{2i} = \frac{1}{\lambda_{2i}}$。因此,基越大,波长越长,频率越低。
位置插值(PI) 位置插值[60]线性地缩放位置以扩大上下文长度。假设模型在上下文长度 $L$ 上进行预训练,我们希望将其扩展到 $L’ > L$。令 $s = \frac{L’}{L}$ 表示缩放因子。PI将原始位置 $n$ 映射到一个假设位置 $n’ = \frac{n}{s}$。最大位置 $L’$ 将被映射到 $L$。因此,所有映射后的位置仍然落在训练范围内。从波长的角度来看,新的波长将是 $\lambda’{2i} = \left( 2\pi s \beta^{\frac{2i}{d}} \right){i=0}^{\frac{d}{2}-1}$。PI能够以最少的微调步骤(约1000步)实现长度外推。
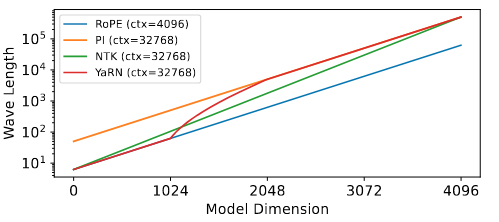
图 10. RoPE、PI、NTK和YaRN的相关波长。图取自Peng等人[401]。y轴使用对数刻度。为了便于说明,YaRN的$\alpha$和$\beta$参数设置为$\frac{1024}{2}$和$\frac{2048}{2}$。在实践中,它们设置为$\frac{2}{2}$和$\frac{64}{2}$。
频率特定缩放 本段中引用的工作建立在一个重要的见解之上:注入高频嵌入可以提高性能和收敛速度[488]。相反,PI放大了波长,将高频嵌入转换为低频嵌入。一个名为“NTK感知缩放”[29]的初始解决方案从非缩放的高频嵌入开始,然后逐渐过渡到缩放的低频嵌入。具体来说,$\lambda^{NTK}{2i} = \left( 2\pi \left( s^{\frac{d}{d-2i}} \beta \right)^{\frac{2i}{d}} \right){i=0}^{\frac{d}{2}-1}$。YaRN比NTK更保守地保留非缩放的高频嵌入,并更快地过渡到缩放的低频嵌入。图10说明了RoPE、PI、NTK和YaRN的波长。
关键旋转基 Liu等人[325]研究了放大和缩小旋转基的影响。他们的设置与PI相似,并计算了关键的缩放因子。假设模型在上下文长度 $L$ 上进行预训练。将 $L$ 表示为 $L_{train}$ 以将其与三角函数联系起来。关键旋转基具有小于 $L_{train}$ 的最大波长。令 $I_c$ 表示关键维度索引,则 $I_c = 2 \lfloor \frac{d}{2} \log_{\beta} \frac{L_{train}}{2\pi} \rfloor$。与 $I_c$ 相关的是关键旋转基 $\beta_c$ 和关键波长 $\lambda_c$。
当将旋转基从 $\beta$ 缩小到 $\beta_{down}$ 时,当最大波长 $2\pi\beta_{down}$ 等于 $\lambda_c$ 时,会发生相变。缩小旋转基的增益在达到 $\beta_c$ 之前是显著的。当将旋转基从 $\beta$ 放大到 $\beta_{up}$ 时,$\lambda_c$ 将对应于 ${\lambda_{I_c}}{up}$,这指示了相变点:模型的困惑度将在长于 ${\lambda{I_c}}_{up}$ 的文本上爆炸。
Men等人[356]进一步审视了缩放旋转基。他们指出,缩小旋转基只能实现肤浅的长上下文能力。作者们更进一步,为期望的模型上下文长度推导了旋转基的下界。该推导基于以下理论见解:模型关注相似词元的能力随着距离的增加而衰减,但对于较大的基,衰减率较慢。经验上,有效上下文长度和旋转基之间存在多项式关系。
7.2.2 注意力和MLP分析
注意力头 注意力头通常服务于专门的目的。例如,先前的研究在LLMs中发现了归纳头、名称移动头和算术头[383, 526, 650]。在识别长上下文建模的关键组件方面已经取得了进展。Wu等人[565]识别出“检索头”,负责从长上下文中提取信息。消融这些头会导致跨模型家族和模型大小的显著性能下降。Razor Attention[489]将检索头细化为两个子集:回声头和归纳头。回声头关注当前位置的相同词元,而归纳头则关注相同词元之后的词元。Fu等人[129]进一步指出了检索-推理(R2)头,它结合了检索能力和推理能力。
Softmax函数和注意力模式 softmax函数对长上下文建模构成了严重的限制。随着序列变长,注意力分数变得越来越均匀,因此模型无法有效聚焦[168]。为了在长度外推期间缓解这个问题,通常采用缩放系数[401]。另一个突出的现象是注意力汇聚效应[580],即注意力头将重分赋予第一个词元。从KV缓存中移除这些词元会严重损害模型性能。已经提出了两种解决方案来解决这个问题:1. 引入一个专门的可训练“汇聚词元”来承载过多的注意力分数。2. 实现替代的注意力机制来替代softmax,如SoftMax-One[363]。
MLP层 Voita等人[516]发现某些MLP神经元的激活与当前词元的位置高度相关。它还揭示了神经元可以充当n-gram检测器,捕获局部模式。虽然作者们只检查了绝对位置嵌入,但可以预期也存在对某些相对位置强烈激活的神经元。
7.2.3 层间交互
现代LLMs由一堆Transformer层组成,每层都包含注意力和MLP模块。有趣的是,研究人员发现,在全注意力和线性复杂度机制(如窗口注意力[597]或闪电注意力[366])之间交替使用可以产生优越的外推性能。关于位置嵌入,Yang等人[597]进一步发现,交替使用NoPE[241]和RoPE可以取长补短,因为NoPE在信息检索方面具有优势,而RoPE由于其内置的新近度偏见,能更好地建模局部信息。
8. 应用
强大的多任务能力使LLMs能够适应广泛的应用。在现实世界场景中,任务经常需要处理广泛的上下文信息。因此,长上下文LLMs显著增强了LLMs在各种领域的实用性,包括GUI助手和基于RAG的系统,如图11所示。在本节中,我们简要讨论长上下文LLMs的应用及其相关技术。
图 11. 长上下文语言模型和技术在各种任务中的应用概览。
8.1 在Agent中的应用
基于LLM的Agent通过与环境的迭代交互来完成任务,根据先前的交互历史预测下一步[572, 610, 682]。由于环境观察和交互轨迹都可能非常长,长上下文能力对于开发有效的Agent至关重要。
长上下文理解能力使LLM Agent能够处理具有扩展观察的复杂Agent任务。一个例子是GUI Agent任务[192],其中Agent需要理解丰富的布局和文本信息[314, 582, 678]。另一个例子是软件工程Agent[224]。Agent被要求与仓库交互以解决现实世界的编码任务[543, 574, 601, 655]。一些Agent任务固有地需要长周期的推理和规划能力。例如,游戏Agent必须跟踪游戏状态并在一个扩展的周期内规划行动以取得进展或获胜[487]。像规划多日旅行路线[47]或解决复杂机器学习问题[43, 196]这样的任务也需要长周期规划。自动Agent优化[683, 691]也需要良好的长上下文理解和生成能力,以便基于LLM的Agent优化器能够有效地对长周期的Agentic工作流和中间结果进行推理,并生成优化的提示、工具和Agentic工作流。
大型语言模型的长上下文能力促进了各种Agent应用的发展。开源LLM Agent开发平台,如Dify[498]和Coze[497],使用户能够轻松地编排从简单Agent到复杂AI工作流的LLM应用。通用Agent,如OpenAI的Computer-Using Agent[505]和Manus[504],作为全面的AI助手,通过在虚拟PC环境中执行网页浏览和编码等操作来处理现实世界的任务。
8.2 在RAG中的应用
将长上下文技术集成到检索增强生成(RAG)系统中,通过支持处理更大的文本块、检索更相关的信息以及支持开发复杂系统以解决复杂查询,显著提高了性能[225, 622]。例如,LongRAG[222],它结合了“长检索器”和“长阅读器”,在文档问答方面表现出显著的改进。类似地,研究[225, 455]表明,能够检索更长文本片段的模型显著增强了答案的相关性和完整性。此外,Li等人引入了“带归因的推理”,它利用长上下文模型通过为复杂提示提供更大的上下文窗口来改进多跳推理基准。这些进步突显了长上下文模型如何减少传统RAG系统对外部工具的依赖,提供了一种强大的端到端建模方法,增强了系统性能和鲁棒性。
由于上述好处,长上下文技术的快速发展刺激了RAG系统的增长,导致了像Perplexity[259]和Genspark[144]这样专注于检索的流行应用的出现。其他系统,如ChatGPT[481]和Deepseek[95],也集成了检索能力。值得注意的是,由xAI开发的Deepsearch[435]通过先进的上下文理解和意图识别增强了信息导航。这些创新凸显了长上下文技术在现代检索系统中的关键作用。
8.3 在聊天机器人中的应用
最近在长上下文处理方面的进步通过实现扩展的记忆保留和上下文连贯性,显著增强了对话系统。长上下文窗口允许聊天机器人处理广泛的对话历史,从而提高交互流畅性并支持长期记忆能力。这种技术飞跃对于需要持续用户参与的应用至关重要,正如探索基于提示的记忆[261]、记忆增强架构[675]和上下文扩展技术[540, 542]的框架所证明的那样。
由于上述好处,长上下文处理技术催生了各种各样的AI对话系统,展示了其在实际应用中的广泛价值。像ChatGPT[385]和Pi[204]这样的主要平台利用持久记忆来维持用户偏好和对话历史,从而实现个性化交互。像Character AI[46]和Talkie[6]这样的专门系统进一步例证了长上下文窗口如何支持风格一致的对话和上下文连续性。这些能力在纵向应用中尤其有价值,包括教育辅导、医疗监控和治疗咨询,在这些应用中,保持跨多次对话的上下文至关重要[230]。
8.4 在代码中的应用
长上下文技术的进步显著增强了仓库级代码任务和软件开发Agent任务[220]。这类任务通常需要处理复杂和广泛的上下文信息,这在以前限制了模型整合全面上下文的能力。例如,RepoCoder[634]采用一种基于相似性的检索机制来丰富上下文并提高代码补全质量。类似地,RLPG框架[461]将仓库结构与相关文件上下文集成,以生成仓库级提示。这些复杂的系统设计是由于早期上下文窗口的限制所必需的。然而,长上下文技术的突破有效地缓解了这些限制,使得能够开发更复杂的系统,从而提高任务执行的精度和效率[460]。
最近包含长上下文技术的模型,如StarCoder2[334]、Qwen2.5-Coder[202]和Granite Code Models[367],在长上下文代码任务中表现出优越的性能。与早期依赖复杂架构来管理扩展上下文的方法不同,这些模型利用强大的长上下文理解能力,为软件开发提供了可扩展和实用的解决方案。这一进展简化了代码补全、上下文理解和仓库级代码生成等任务。
由于这些进步,长上下文技术刺激了先进的AI驱动代码应用的发展,如GitHub Copilot[146]和Anysphere Cursor[15]。这些工具利用长上下文模型来增强代码补全,提供上下文文档,并实现预测性调试。通过保持对大型代码库的连贯理解,它们提高了开发人员的生产力,减少了手动工作,并支持更直观的工作流。这种集成突显了长上下文技术对现代软件开发的变革性影响。
8.5 在传统NLP任务中的应用
长上下文技术的引入通过解决传统方法的局限性(这些方法受限于受限的上下文窗口),在许多传统NLP任务中带来了变革性的突破。这一技术进步显著增强了各种NLP应用的性能和实际适用性。在本节中,我们简要讨论三个从长上下文技术中特别受益的代表性任务。
文档摘要 传统文档摘要方法常常遇到不一致和上下文理解有限等挑战[639, 652]。长上下文模型的开发使得能够一次性处理整个文档,促进了对原始内容的更全面理解和对冗余信息的更好识别[150, 539, 630]。像Longformer[25]和LongT5[165]这样的模型在文档摘要任务中表现出色,从而推动了诸如摘要新闻文章和学术论文[227]等应用的实际实施。
信息检索 传统上,大多数向量模型受限于窗口大小,这在执行长上下文语义建模时需要将数据分割成块,常常导致连贯语义信息的丢失[530, 690]。然而,随着长上下文技术的进步,语义向量模型现在可以容纳更长的文本输入,例如text-embedding-3-large[384]、jina-embeddings-v2[163]和BGE-M3[55]。这使得能够处理更长的文本,如章节和文档,从而显著提高了语义向量模型在现实世界应用中的实际可用性[437, 687]。
机器翻译 文档翻译是机器翻译中的一个关键研究领域。早期的方法侧重于修改Transformer架构以编码更多的上下文信息[24, 361, 532, 636]。然而,长上下文模型可以通过处理扩展的上下文窗口直接翻译冗长、复杂的文档,这改善了多义词的翻译[181, 533]。这一进步显著提高了长文档的翻译质量,并使得大型语言模型翻译整部小说和书籍变得越来越可行[342]。
8.6 在多模态任务中的应用
理解广泛的视频、大量的图像集、音频流和冗长的文本输入在现实世界场景中通常是必不可少的。因此,多模态长上下文建模已成为长文本应用中的一个关键研究领域。本节概述了长上下文多模态大型语言模型(MLLMs)的相关数据和训练策略、模型和框架,以及基准。
数据和训练策略 为了扩展MLLMs的上下文窗口,许多研究设计了数据整理流程来过滤和合成长上下文多模态训练数据。通常,这些数据集与文本长上下文训练数据不同,是通过增加上下文中多模态部分的长度来构建的,例如多图像[617]、长视频[111, 289]。利用这一点,一些方法[171, 273, 541, 594, 644, 666]通过逐渐增加这些长上下文多模态训练数据的长度来激发MLLMs处理长文本的能力。之后,一些工作[284]利用偏好优化的变体来改进MLLMs的长上下文建模。另外,一些工作利用长上下文LLMs作为MLLMs的基-础模型进行训练[211],以继承LLMs的长上下文建模能力。
模型结构和框架 为了增强MLLMs理解多模态长上下文输入的能力并减少模型训练和推理中的计算成本,一些工作侧重于修改位置嵌入和在MLLMs中引入新兴模块,以提高推理效率和性能。接下来,我们将详细介绍这些技术的细节。与纯文本长上下文建模不同,为了有效地建模多模态长上下文输入中视觉词元的位置信息,一些研究[138, 475, 535]提出扩展许多MLLMs采用的ROPE的维度。维度扩展使ROPE能够改善多模态词元中的序列建模、图像中的空间建模以及视频帧之间的时间建模,从而改善了在多模态长上下文输入中区分视觉词元的位置信息。除了增强多模态模型捕获位置信息的能力,一些研究还引入了专门的模块,通过MLP[535]、像素洗牌[70]、类Q-former模块[9, 280, 612, 689]、LoRA[343]来进一步减少视觉词元占用的上下文窗口长度,这些模块将有效的重要视觉信息整合到LLMs中,消除了视觉表示中的冗余信息。然而,上述减少视觉词元长度的方法需要从头开始训练MLLMs以进行适应。为了在不训练的情况下压缩视觉词元的数量以降低训练良好的MLLMs的推理成本,一些方法[170, 322, 511, 604]以免训练的方式通过评估它们与输入文本的相关性来保留重要的视觉词元。通常,对于多模态长上下文输入,由于包含大量帧,视频占用了上下文窗口的最大部分。因此,一些工作利用树结构[547]、奖励模型[607]、基于CLIP[300]的相似性分数、训练好的视频帧选择器[171, 621]和聚合方法[123]来选择关键帧并减少上下文中的视频长度。
基准 在介绍了社区中长上下文MLLMs的基本和高级发展之后,在本部分中,我们将回顾用于评估多模态长上下文建模能力的现有评估基准。多模态长上下文基准主要可分为两类:使用多个图像的基准和使用长视频作为上下文的基准。这些基准然后要求模型根据上下文信息回答问题,以评估MLLMs的多模态长上下文建模能力。对于使用多图像上下文的基准,一些工作[77, 347, 407]使用大量的多模态案例作为上下文来评估模型的多次上下文学习能力。其他工作则采用大海捞针[524]、时间性和语义性多图像任务[465]作为主要的评估方法。此外,一些研究[221, 434, 449]不仅评估对长多模态上下文的理解,还评估多文档理解能力。与多图像长上下文数据相比,理解长视频更具挑战性,因为它们的上下文长度更大,并且包含更多冗余和嘈杂的信息。一些工作[44, 143, 677, 692]利用多样化的长视频和多个具有挑战性的任务来评估MLLMs的多模态长上下文建模。其他工作[111, 376, 560]通过自动和手动方法收集具有丰富事件的视频,并提出问题。
8.7 在特定领域的应用
长上下文技术通过实现对复杂和冗长信息更高效的处理,在各个领域展示了巨大的潜力[150]。在新闻领域,它通过从多个来源聚合数据来改善连贯摘要的生成[134]。在法律领域,它简化了大量文件的解释,帮助专业人士快速提取关键见解[238]。在医疗保健领域,长上下文模型增强了病历和医学文献的综合,从而支持知情决策[119]。金融应用利用这些模型分析广泛的报告并得出市场趋势的见解[353, 381, 425]。在生物学领域,长上下文技术有助于理解分子结构和基因组序列,促进了药物发现和个性化医疗的进步[182, 446]。总的来说,长上下文模型显著提高了这些领域信息处理的有效性和准确性,使数据综合和信息提取更加高效。
9. 未来方向
9.1 面向o1-like长推理的长上下文建模
最近,o1-like长推理模型因其在复杂推理任务上的卓越性能而引起了广泛关注[56, 164, 201, 373, 412, 502, 657, 669]。这种测试时扩展范式首先生成扩展的CoT推理,然后产生答案,本质上赋予了模型在上下文窗口内进行试错、回溯、修正和迭代自回归的能力,从而解锁了显著的性能提升[275, 293, 525]。尽管前景广阔,但当前利用LongCoT的实践远未令人满意,主要有两个关键缺点:生成的CoT质量粗糙,严重影响推理效率,包含大量冗余和不相关信息[63, 191, 345, 576, 640];以及扩展CoT长度的困难严重限制了进一步性能提升的潜力,因为许多研究已经观察到在特别长的推理链中性能下降[570, 605, 632]。
应对这些挑战需要长上下文语言模型的进步,这对于两个关键方面至关重要:对长推理过程的可靠评估(目前对现有的过程奖励模型[177]来说是一个重大挑战),以及开发强大的长格式生成能力以产生更长、更可靠的推理链。此外,将为通用长上下文场景开发的效率导向技术(如KV缓存压缩和提示压缩)针对长推理模型的特定需求进行调整,为未来的研究提出了一个有希望的方向。
9.2 进一步扩展上下文窗口并提升建模能力
上下文长度是语言模型最基本的属性之一。它的演变紧密跟踪了日益复杂的建模能力的发展——从仅限于几个上下文词元的基本n-gram模型[36],到处理数百词元进行段落级理解的BERT式架构[101],再到管理2k-4k词元进行通用对话的ChatGPT早期迭代,以及现在达到前所未有的100k到1M词元的规模,这使得复杂的能力成为可能,包括长思维链推理[164]、长上下文学习[499]、长视频处理[507]和支持具有广泛交互历史的复杂Agent系统[506]。这一进展表明,扩展上下文长度一直为语言建模开启新的前沿,实现了日益复杂的应用和用例。因此,将上下文窗口扩展到更大的规模,有望释放更先进的能力和变革性的应用。另一方面,现有的研究已经证明了模型的声称支持上下文长度和其实际有效上下文长度之间存在显著差距[12, 189]。因此,增强模型在其支持的上下文长度内的长上下文建模能力仍然至关重要。关于上下文窗口的扩展和在支持的上下文窗口内提高长上下文建模能力,我们确定了几个有希望的方向:
长上下文强化学习 尽管其潜力巨大,但强化学习在长上下文场景中仍未得到充分探索。虽然将LongCoT与RL相结合在具有明确答案的任务中显示出显著的改进,但许多长上下文应用仍然面临根本性的挑战,因为它们需要参考冗长的输入。一个例子是对齐场景,其中长上下文RLHF实践——无论是使用长上下文模型作为奖励模型(例如,GLM-Long[147])还是利用长上下文偏好数据(例如,LLaMA-3.1[154])——尚未产生实质性的好处。长上下文RL的核心挑战在于开发能够有效评估广泛输入的奖励模型,例如冗长的推理链、叙述和对话。为了实现这一目标,收集长上下文偏好数据,无论是通过人工标注还是精心设计的合成协议,都值得进一步研究。
收集、过滤和合成高质量训练数据的配方 长上下文建模能力的进步根本上是由数据驱动的。训练长上下文模型的配方为未来的探索提供了几个有希望的方向:(1)开发超越启发式的细粒度过滤策略,以识别具有长程依赖性的训练数据;(2)合成需要整合分散在整个文本中的关键信息的具有挑战性的查询及其正确答案;(3)探索特别适合长上下文RL训练的任务类型,这些类型最能泛化到其他长上下文任务;(4)优化领域和序列长度的分布,以在计算成本和模型性能之间实现帕累托效率。应对这些挑战对于开发更高效、更有效的未来LCLMs的数据配方至关重要。
长上下文蒸馏 模型蒸馏是通过利用更大、更强大的模型来增强较小模型能力的常用策略。事实上的方法包括为一个查询集从强模型生成响应,然后用这些问答对微调较小的模型。这种方法在各个方面都证明了其有效性,包括提高模型响应的人类偏好评级和增强模型的思维链推理能力。在长上下文领域,一个有趣的研究问题出现了:我们如何利用具有强大长上下文建模能力的大型模型来改进具有较弱长上下文能力的模型?除了生成高质量的响应[19],一个有趣的观察是,强大的LCLMs可以有效地识别和过滤表现出强长程依赖性的训练数据,能力更强的模型表现出优越的过滤效果[561]。鉴于LCLM训练是一个跨越预训练和后训练阶段的复杂过程,我们相信具有强大长上下文建模能力的模型可以在LCLM训练过程中发挥更重要的作用,提高训练效率和最终的模型性能。
性能导向的架构设计 架构设计在长上下文建模中仍然是一个持续的研究课题。除了提高训练和部署效率,架构修改(如增强的位置编码和混合注意力机制)可以带来更好的外推能力和在支持的上下文长度内改进的建模,如第3节所讨论。我们预计在这一方向上会继续取得进展,以进一步增强LCLMs的建模能力。
优化长格式生成 当前对LCLMs的研究主要集中在处理长输入,例如从大量文档中进行信息检索或生成简明的摘要。相比之下,长格式生成仍然相对未被探索,尽管其在长格式叙事创作、仓库级代码生成和长CoT等领域具有广阔的应用前景。推进长格式生成能力提出了两个重大挑战:首先,除了上下文理解,高质量长格式内容的自动生成需要复杂的输出规划,要求更高水平的语言建模能力。其次,评估生成的长格式内容构成了巨大的困难——像ROUGE这样的自动指标对于冗长的文本表现出有限的可靠性,而手动评估则证明成本高得令人望而却步。因此,长格式生成的未来进步可能需要与长格式内容的自动评估方法学的改进同步发展。
领域特定增强 如上所述,上下文窗口的扩展为语言模型解锁了多样化的应用领域,从法律和医学等文本密集型领域到视觉语言模型处理广泛视觉内容的多模态场景,再到维持丰富交互历史的智能系统。虽然保持强大的通用长上下文建模能力至关重要,但为这些领域特定的挑战研究有针对性的优化,提出了一个有希望的研究方向。
9.3 LCLMs的高效架构设计、训练和部署
模型架构 Transformer模型的固有局限性在长上下文场景中变得突出,主要是由于巨大的KV缓存内存开销。内存显著超过了当代GPU的高带宽内存(HBM)容量。因此,探索内存高效的KV缓存架构,例如研究线性注意力机制,成为长上下文语言模型架构进步的关键方向。
训练和推理框架 为了减轻训练的复杂性,精细的分区策略[409]和局部重计算技术[248]的实施至关重要。这些平衡了带宽开销与计算时间的方法对于有效解决日益复杂的模型架构和不断发展的GPU能力之间日益扩大的差距至关重要。对于推理框架,策略性地部署算子融合和重新排列计算序列以减少大量中间矩阵的生成,仍然是一个值得研究的途径[92, 93, 442]。尽管普遍的精度标准固定在16位,但最先进的硬件架构已经支持在降低的精度下进行高吞吐量计算,低至8位[382]。将8位量化应用于模型内有选择的模块,适用于训练和推理范式,已经显示出相当大的前景[308]。专注于探索更低精度量化水平的前瞻性研究工作,以及在更广泛的模型模块中扩展量化应用,预计将产生显著的性能提升。最近,长上下文强化学习(RL)训练[164]的出现给现有框架带来了新的挑战,需要有针对性的优化来增强训练效率和稳定性。
定制硬件设计 硬件计算速度的快速提升已经超过了带宽的相应增长,从而加剧了带宽瓶颈,特别是在解码阶段[145]。虽然现有的预填充-解码分离架构促进了预填充和解码阶段的独立优化,但在为解码设计的专门硬件方面仍然存在显著的空白。解码过程的固有特点是对具有更多HBM容量和更高带宽的GPU有大量需求,而计算强度相对较低。因此,开发专门为解码设计的专用硬件,以增强的HBM容量和带宽为特点,构成了该领域未来硬件演进的一个关键方向。
9.4 更可靠的长上下文语言建模评估框架
如第6节所述,长上下文语言建模的能力可以分为两个主要方面:长上下文理解和长格式生成。因此,未来的研究方向自然地与这两个基本轨道对齐。
走向真实世界和场景特定的长上下文理解 关于长上下文理解,鉴于已经出现了许多合成和真实世界的基准来评估该能力的各个方面,未来的研究可以 направлена на более специфические реальные приложения.这包括挖掘用户日志以理解真实的长上下文使用模式,评估LCLM在专业领域(如法律、医学和金融部门)的性能,以及评估其在不同学科(从社会科学到自然科学)中的有效性等。值得注意的是,广泛的输入长度对获得高质量的人工标注构成了重大挑战。因此,开发专门为长上下文场景设计的有效标注框架,提出了另一个有价值的研究方向。
长格式生成的粗到细评估 在长格式生成领域,人工评估被频繁使用,主要是因为自动指标难以有效地评估长响应,并且不太适合开放式生成任务。人工评估和自动指标是两个极端:自动指标高效但缺乏精确性,而人工评估提供高准确性但资源密集。我们如何结合两者的优势?通过观察长格式生成的评估方法的趋势,我们可以注意到从自动指标和人工评估的组合向采用LLM-as-a-Judge的转变。尽管如此,对长响应的完全端到端评估对于当前的LLMs仍然是一个挑战。为了解决这个问题,可以设计一个评估工作流程,将整个评估分解为粒度方面,遵循一个系统的从粗到细的适应。对于较简单的评估方面,LLMs结合提示工程可以作为人工评估员的替代。对于LLMs难以评估的组件,可以探索进一步分解评估工作流程或采用基于代理的方法。这种系统的分解使我们能够在提高效率的同时保持高评估准确性,最终揭开与长格式生成评估相关的挑战。目前,ProxyQA[486]、HelloBench[418]和LongFact[549]反映了这一趋势,但我们相信在进一步优化这些系统以实现更高准确性方面仍有潜力。
9.5 走向长上下文建模的机理可解释性
机理可解释性(MI)[378]旨在在模块级别上对模型进行逆向工程。在MI文献中[357, 526, 650],研究人员通常确定一组稀疏的注意力头和MLP,它们负责某些下游任务。长上下文建模的MI的一个范例是识别与长程依赖性相关的检索头[565]。MI对于长上下文建模是两个世界的一个令人兴奋的交叉点。我们指出几个有希望的研究问题来回答。
位置嵌入的机理理解 LLMs如何利用位置嵌入?Voita等人[516]展示了某些神经元的激活权重与当前词元的位置高度相关,但他们只分析了绝对位置嵌入。未来的工作可以揭示相对位置嵌入是否也如此,以及在处理位置信息时MLP和注意力模块之间的相互作用。
识别长上下文问题的原因 我们主张对长上下文建模采用问题驱动的MI方法。例如,Liu等人[317]指出模型在处理信息时存在位置偏差,偏爱开头或结尾的词元。我们更进一步,问:模型的哪个模块导致了这种偏差?基于可能的发现,我们能否设计一种方法从机理上缓解它?
可解释性驱动的增强 与此密切相关的是长度外推问题。Zhou等人[685]证明,LLMs在对长于训练分布中的数字进行加法运算时,无法对齐数字。同样,我们问:模型的哪个模块对此失败负责?我们能否在这些发现的基础上改进长度外推?在较高层面上,MI提供了有用的工具链来理解LLMs的内部工作原理并查明有问题的组件。另一方面,长上下文建模是一个具有其独特兴趣和巨大应用空间的具有挑战性的领域。MI对于长上下文建模在有效识别和解决问题方面具有巨大潜力。
10. 结论
在本文中,我们对大型语言模型的长上下文建模的最新进展进行了一次全面的综述。具体来说,我们首先讨论了长上下文数据策略,包括用于预训练和后训练阶段的数据过滤、数据混合和数据构建策略。然后,我们对模型的最新进展进行了全面的讨论,包括基于Transformer的LLM架构和位置嵌入,旨在增强LLMs的长上下文能力。之后,我们提供了基于工作流的LCLM方法,如提示压缩和基于Agent的方法,以增强长上下文能力。此外,我们讨论了长上下文评估基准,包括理解和生成能力。此外,我们提供了AI基础设施方法,包括为长上下文建模优化的训练和推理策略。此外,我们还为LCLMs的更好可解释性提供了详细的分析。最后,我们总结了长上下文建模的现有应用(例如,Agent、RAG、Code),并讨论了未来方向的剩余问题或挑战。最后,我们希望我们的综述能够指导开发人员更好地理解LCLMs的相关技术,并促进基础模型的成长。
11. 贡献与致谢
项目负责人
- Jiaheng Liu, 南京大学,中国科学院自动化研究所,M-A-P,组织整个项目
- Dawei Zhu, 北京大学,组织整个项目
核心贡献者(按字母顺序)
- Zhiqi Bai, 阿里巴巴集团,架构
- Yancheng He, 阿里巴巴集团,应用
- Huanxuan Liao, 中国科学院自动化研究所,数据
- Haoran Que, M-A-P,评估
- Zekun Wang, 快手科技,工作流设计
- Chenchen Zhang, 腾讯,分析
- Ge Zhang, 字节跳动,M-A-P,架构与评估
- Jiebin Zhang, 北京大学,基础设施
- Yuanxing Zhang, 快手科技,基础设施
贡献者(按字母顺序)
- Zhuo Chen, 阿里巴巴集团,架构
- Hangyu Guo, M-A-P,应用
- Shilong Li, 阿里巴巴集团,应用
- Ziqiang Liu, 中国科学院深圳先进技术研究院,工作流设计
- Yong Shan, 字节跳动,架构
- Yifan Song, 北京大学,应用
- Jiayi Tian, 阿里巴巴集团,数据
- Wenhao Wu, 北京大学,未来方向
- Zhejian Zhou, 南加州大学,分析
- Ruijie Zhu, 加州大学圣克鲁兹分校,架构
赞助委员会(按字母顺序)
- Junlan Feng, 中国移动研究院
- Yang Gao, 南京大学
- Shizhu He, 中国科学院自动化研究所
- Zhoujun Li, AiStrong
- Tianyu Liu, M-A-P
- Fanyu Meng, 中国移动研究院
- Wenbo Su, 阿里巴巴集团
- Yingshui Tan, 阿里巴巴集团
- Zili Wang, 独立研究员
- Jian Yang, 阿里巴巴集团
- Wei Ye, 北京大学
- Bo Zheng, 阿里巴巴集团
- Wangchunshu Zhou, OPPO, M-A-P
通讯作者
- Jiaheng Liu, 南京大学,中国科学院自动化研究所,M-A-P
- Dawei Zhu, 北京大学
- Wenhao Huang, 字节跳动,M-A-P
- Sujian Li, 北京大学
- Zhaoxiang Zhang, 中国科学院自动化研究所
重点内容提炼
这篇综述系统性地梳理了长上下文语言模型(LCLMs)领域的最新进展,其核心贡献可以概括为对以下三个关键问题的全面回答:
- 如何构建有效且高效的LCLMs? (What)
- 数据策略:论文强调了高质量数据的重要性,包括在预训练和后训练阶段,通过精细化过滤(如LongAttn)、数据混合(如Data Mixing Laws)和合成(如Quest)来构建长程依赖数据。
- 架构设计:这是长上下文研究的核心。
- 位置编码:重点讨论了旋转位置嵌入 (RoPE) 及其外推方法,如位置插值 (PI) 和 NTK-aware Scaling (YaRN),它们是实现上下文窗口扩展的关键。
- 注意力机制:介绍了从标准的二次复杂度注意力到高效变体的演进,包括稀疏注意力(如Longformer)、线性复杂度架构(如Mamba和RetNet)以及结合两者的混合架构(如Jamba),这些是平衡性能与效率的关键。
- 工作流设计:介绍了不修改模型本身,而是通过外部模块增强长上下文能力的方法,主要包括提示压缩(如LLMLingua)、基于记忆的方法(如MemoryBank)、检索增强生成 (RAG) 和基于Agent的方法(如ReadAgent)。
- 如何高效地训练、部署和分析LCLMs? (How)
- 训练与推理基础设施:
- 训练优化:讨论了针对长上下文训练的系统级优化,如I/O优化、GPU内存优化(特别是FlashAttention,它通过分块计算和优化的内存访问显著提升了效率)和通信-计算重叠策略。
- 推理优化:涵盖了多种加速技术,包括量化(尤其是KV缓存量化)、高效内存管理(如PagedAttention)、预填充-解码分离架构和推测性解码,这些对于降低长上下文推理的延迟和成本至关重要。
- 评估与分析:
- 评估范式:将长上下文能力分为理解和生成两大类。理解能力被进一步分解为检索、聚合、推理等核心能力,并提出了大海捞针 (NIAH) 等合成任务进行评估。同时,论文也强调了真实世界基准(如LongBench, RULER)的重要性。
- 核心发现分析:论文深入分析了“中间丢失 (Lost in the Middle)”现象,即模型在处理长文本时,对中间部分信息的利用能力较弱。同时,探讨了困惑度(PPL) 与模型真实性能之间的关系,并对RAG与LCLMs的优劣及结合前景进行了讨论。
- 训练与推理基础设施:
- LCLMs的应用与未来方向是什么? (Why & Where)
- 核心应用:长上下文能力极大地扩展了LLMs的应用边界,尤其是在需要处理大量信息的领域,如Agent(长交互历史)、RAG(大规模知识库)、代码(仓库级理解)、多模态(长视频分析)以及金融、法律、医疗等专业领域。
- 未来方向:
- 能力提升:追求o1-like长推理,进一步扩展上下文窗口,并研究长上下文强化学习 (RLHF)。
- 技术优化:设计更高效的架构、数据配方和软硬件协同的训练/推理框架。
- 评估与可解释性:构建更可靠的评估框架,并利用机理可解释性 (MI) 来理解和解决长上下文中的问题,如位置偏差。
总而言之,这篇综述为研究者和开发者提供了一张关于长上下文语言模型领域的“全景地图”,不仅详细描绘了从数据到应用的全链路技术,还指明了当前面临的挑战和未来充满希望的探索路径。
- Ntk-alibi, “Ntk-alibi: Long text extrapolation of alibi position encoding through interpolation”
- Long-data-collections, “Long-data-collections”
- Amro Abbas, “Semdedup: Data-efficient learning at web-scale through semantic deduplication”
- Lisa Adams, “Longhealth: A question answering benchmark with long clinical documents”
- Ameeta Agrawal, “Evaluating multilingual long-context models for retrieval and reasoning”
-
Talkie Ai, “Talkie ai-native character community” - Joshua Ainslie, “GQA: training generalized multi-query transformer models from multi-head checkpoints”
- Faisal Al-Khateeb, “Position interpolation improves alibi extrapolation”
- Jean-Baptiste Alayrac, “Flamingo: a visual language model for few-shot learning”
- Chenxin An, “L-eval: Instituting standardized evaluation for long context language models”
- Chenxin An, “Training-free long-context scaling of large language models”
- Chenxin An, “Why does the effective context length of llms fall short?”
- Shengnan An, “Make your LLM fully utilize the context”
- Anthropic, “Introducing contextual retrieval”
- Anysphere, “Cursor - the ai code editor”
- Simran Arora, “Simple linear attention language models balance the recall-throughput tradeoff”
- Yushi Bai, “Longbench: A bilingual, multitask benchmark for long context understanding”
- Yushi Bai, “Longalign: A recipe for long context alignment of large language models”
- Yushi Bai, “LongAlign: A recipe for long context alignment of large language models”
- Yushi Bai, “Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks”
- Yushi Bai, “Longwriter: Unleashing 10,000+ word generation from long context llms”
- Zhihao Bai, “{PipeSwitch}: Fast pipelined context switching for deep learning applications”
- Satanjeev Banerjee, “Meteor: An automatic metric for mt evaluation with improved correlation with human judgments”
- Guangsheng Bao, “G-transformer for document-level machine translation”
- Iz Beltagy, “Longformer: The long-document transformer”
- Iz Beltagy, “Longformer: The long-document transformer”
- Assaf Ben-Kish, “Decimamba: Exploring the length extrapolation potential of mamba”
- Amanda Bertsch, “In-context learning with long-context models: An in-depth exploration”
- bloc97, “NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation”
- Egor Bogomolov, “Long code arena: a set of benchmarks for long-context code models”
- Sebastian Borgeaud, “Improving language models by retrieving from trillions of tokens”
- Antoine Bosselut, “Discourse-aware neural rewards for coherent text generation”
- Aleksandar Botev, “Recurrentgemma: Moving past transformers for efficient open language models”
- Felix Brakel, “Model parallelism on distributed infrastructure: A literature review from theory to llm case-studies”
- William Brandon, “Striped attention: Faster ring attention for causal transformers”
- Thorsten Brants, “Large language models in machine translation”
- Tom B. Brown, “Language models are few-shot learners”
- Aydar Bulatov, “Scaling transformer to 1m tokens and beyond with RMT”
- Tianle Cai, “Medusa: Simple llm inference acceleration framework with multiple decoding heads”
- Zefan Cai, “Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling”
- Yihan Cao, “Instruction mining: Instruction data selection for tuning large language models”
- Linzheng Chai, “Mceval: Massively multilingual code evaluation”
- Jun Shern Chan, “Mle-bench: Evaluating machine learning agents on machine learning engineering”
- Keshigeyan Chandrasegaran, “Hourvideo: 1-hour video-language understanding”
- Li-Wen Chang, “Flux: fast software-based communication overlap on gpus through kernel fusion”
- Character AI, “Character ai”
- Aili Chen, “Travelagent: An AI assistant for personalized travel planning”
- Danqi Chen, “Reading Wikipedia to answer open-domain questions”
- Guanzheng Chen, “Clex: Continuous length extrapolation for large language models”
- Guanzheng Chen, “Clex: Continuous length extrapolation for large language models”
- Howard Chen, “Walking down the memory maze: Beyond context limit through interactive reading”
- Jian Chen, “Magicdec: Breaking the latency-throughput tradeoff for long context generation with speculative decoding”
- Jian Chen, “Fintextqa: A dataset for long-form financial question answering”
- Jianghao Chen, “Ladm: Long-context training data selection with attention-based dependency measurement for llms”
- Jianlv Chen, “BGE m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation”
- Liang Chen, “R1-v: Reinforcing super generalization ability in vision-language models with less than $3”
- Lichang Chen, “Alpagasus: Training a better alpaca with fewer data”
- Longze Chen, “Long context is not long at all: A prospector of long-dependency data for large language models”
- Mingda Chen, “Summscreen: A dataset for abstractive screenplay summarization”
- Shouyuan Chen, “Extending context window of large language models via positional interpolation”
- Stanley F Chen, “An empirical study of smoothing techniques for language modeling”
- Tong Chen, “Generative adapter: Contextualizing language models in parameters with a single forward pass”
- Xingyu Chen, “Do not think that much for 2+ 3=? on the overthinking of o1-like llms”
- Yingfa Chen, “Stuffed mamba: State collapse and state capacity of rnn-based long-context modeling”
- Yingfa Chen, “Stuffed mamba: State collapse and state capacity of rnn-based long-context modeling”
- Yuhan Chen, “Fortify the shortest stave in attention: Enhancing context awareness of large language models for effective tool use”
- Yuhan Chen, “Hope: A novel positional encoding without long-term decay for enhanced context awareness and extrapolation”
- Yukang Chen, “Longlora: Efficient fine-tuning of long-context large language models”
- Yukang Chen, “Longlora: Efficient fine-tuning of long-context large language models”
- Zhe Chen, “How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites”
- Zhi Chen, “What are the essential factors in crafting effective long context multi-hop instruction datasets? insights and best practices”
- Xin Cheng, “xRAG: Extreme context compression for retrieval-augmented generation with one token”
- Alexis Chevalier, “Adapting language models to compress contexts”
- Ta-Chung Chi, “Kerple: Kernelized relative positional embedding for length extrapolation”
- Ta-Chung Chi, “Dissecting transformer length extrapolation via the lens of receptive field analysis”
- Ta-Chung Chi, “Latent positional information is in the self-attention variance of transformer language models without positional embeddings”
- Yew Ken Chia, “M-longdoc: A benchmark for multimodal super-long document understanding and A retrieval-aware tuning framework”
- Rewon Child, “Generating long sequences with sparse transformers”
- Sai Sena Chinnakonduru, “Weighted grouped query attention in transformers”
- Woon Sang Cho, “Towards coherent and cohesive long-form text generation”
- Krzysztof Marcin Choromanski, “Rethinking attention with performers”
- Aakanksha Chowdhery, “Palm: scaling language modeling with pathways”
- Yu-Neng Chuang, “Learning to compress prompt in natural language formats”
- Igor Churin, “Long input benchmark for russian analysis”
- Karl Cobbe, “Training verifiers to solve math word problems”
- Cohere and Cohere For AI, “C4ai command r7b: A 7 billion parameter multilingual model”
- Marta R Costa-jussà, “Lcfo: Long context and long form output dataset and benchmarking”
- Hui Dai, “Deniahl: In-context features influence llm needle-in-a-haystack abilities”
- Jincheng Dai, “Corm: Cache optimization with recent message for large language model inference”
- Zihang Dai, “Transformer-xl: Attentive language models beyond a fixed-length context”
- Bhavana Dalvi Mishra, “Towards teachable reasoning systems: Using a dynamic memory of user feedback for continual system improvement”
- Tri Dao, “Flashattention-2: Faster attention with better parallelism and work partitioning”
- Tri Dao, “Flashattention: Fast and memory-efficient exact attention with io-awareness”
- Pradeep Dasigi, “A dataset of information-seeking questions and answers anchored in research papers”
- DeepSeek, “Deepseek official website”
- DeepSeek, “3fs: Fire-flyer file system”
- DeepSeek-AI, “Deepseek-v3 technical report”
- Mostafa Dehghani, “Universal transformers”
- Tim Dettmers, “Qlora: Efficient finetuning of quantized llms”
- Jacob Devlin, “Bert: Pre-training of deep bidirectional transformers for language understanding”
- Jacob Devlin, “BERT: Pre-training of deep bidirectional transformers for language understanding”
- Yiran Ding, “Longrope: Extending llm context window beyond 2 million tokens”
- Jianbo Dong, “Eflops: Algorithm and system co-design for a high performance distributed training platform”
- Shichen Dong, “Qaq: Quality adaptive quantization for llm kv cache”
- Xin Dong, “Hymba: A hybrid-head architecture for small language models”
- Zican Dong, “A survey on long text modeling with transformers”
- Zican Dong, “Bamboo: A comprehensive benchmark for evaluating long text modeling capacities of large language models”
- Longxu Dou, “Sailor2: Sailing in south-east asia with inclusive multilingual llm”
- Nan Du, “Glam: Efficient scaling of language models with mixture-of-experts”
- Nan Du, “Glam: Efficient scaling of language models with mixture-of-experts”
- Yifan Du, “Towards event-oriented long video understanding”
- Zhengxiao Du, “GLM: General language model pretraining with autoregressive blank infilling”
- Jiangfei Duan, “Efficient training of large language models on distributed infrastructures: a survey”
- Haojie Duanmu, “Skvq: Sliding-window key and value cache quantization for large language models”
- Mostafa Elhoushi, “LayerSkip: Enabling early exit inference and self-speculative decoding”
- Alexander R Fabbri, “Qafacteval: Improved qa-based factual consistency evaluation for summarization”
- Alexander Richard Fabbri, “Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model”
- Angela Fan, “Eli5: Long form question answering”
- Yongqi Fan, “Medodyssey: A medical domain benchmark for long context evaluation up to 200k tokens”
- Yongqi Fan, “Medodyssey: A medical domain benchmark for long context evaluation up to 200k tokens”
- Lizhe Fang, “What is wrong with perplexity for long-context language modeling?”
- Yan Fang, “Scaling laws for dense retrieval”
- Gueter Josmy Faure, “Hermes: temporal-coherent long-form understanding with episodes and semantics”
- Yuan Feng, “Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference”
- Qichen Fu, “Lazyllm: Dynamic token pruning for efficient long context llm inference”
- Tianyu Fu, “Moa: Mixture of sparse attention for automatic large language model compression”
- Yao Fu, “Data engineering for scaling language models to 128k context”
- Yu Fu, “Not all heads matter: A head-level kv cache compression method with integrated retrieval and reasoning”
- Yu Fu, “Not all heads matter: A head-level KV cache compression method with integrated retrieval and reasoning”
- Chaochen Gao, “Quest: Query-centric data synthesis approach for long-context scaling of large language model”
- Jun Gao, “Unifying demonstration selection and compression for in-context learning”
- Leo Gao, “The pile: An 800gb dataset of diverse text for language modeling”
- Luyu Gao, “Precise zero-shot dense retrieval without relevance labels”
- Shen Gao, “Abstractive text summarization by incorporating reader comments”
- Tianyu Gao, “How to train long-context language models (effectively)”
- Yizhao Gao, “Seerattention: Learning intrinsic sparse attention in your llms”
- Shawn Gavin, “Longins: A challenging long-context instruction-based exam for llms”
- Junqi Ge, “V2pe: Improving multimodal long-context capability of vision-language models with variable visual position encoding”
- Suyu Ge, “Model tells you what to discard: Adaptive KV cache compression for LLMs”
- Tao Ge, “In-context autoencoder for context compression in a large language model”
- Yuan Ge, “Clustering and ranking: Diversity-preserved instruction selection through expert-aligned quality estimation”
- Jonas Gehring, “Convolutional sequence to sequence learning”
- Tiantian Geng, “Longvale: Vision-audio-language-event benchmark towards time-aware omni-modal perception of long videos”
- genspark, “genspark.ai”
- Amir Gholami, “Ai and memory wall”
- GitHub, “Github copilot”
- Team GLM, “Chatglm: A family of large language models from glm-130b to glm-4 all tools”
- Paolo Glorioso, “The zamba2 suite: Technical report”
- Paolo Glorioso, “Zamba: A compact 7b ssm hybrid model”
- Aditi S. Godbole, “Leveraging long-context large language models for multi-document understanding and summarization in enterprise applications”
- Omer Goldman, “Is it really long context if all you need is retrieval? towards genuinely difficult long context nlp”
- Daniel Goldstein, “Goldfinch: High performance rwkv/transformer hybrid with linear pre-fill and extreme kv-cache compression”
- Olga Golovneva, “Contextual position encoding: Learning to count what’s important”
- Aaron Grattafiori, “The llama 3 herd of models”
- Albert Gu, “Mamba: Linear-time sequence modeling with selective state spaces”
- Albert Gu, “Mamba: Linear-time sequence modeling with selective state spaces”
- Albert Gu, “Hippo: Recurrent memory with optimal polynomial projections”
- Albert Gu, “Combining recurrent, convolutional, and continuous-time models with linear state space layers”
- Albert Gu, “Efficiently modeling long sequences with structured state spaces”
- Jian Guan, “Lot: A story-centric benchmark for evaluating chinese long text understanding and generation”
- Ziyi Guan, “Aptq: Attention-aware post-training mixed-precision quantization for large language models”
- Suriya Gunasekar, “Textbooks are all you need”
- Michael Günther, “Jina embeddings 2: 8192-token general-purpose text embeddings for long documents”
- Daya Guo, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning”
- Mandy Guo, “Longt5: Efficient text-to-text transformer for long sequences”
- Kelvin Guu, “Realm: retrieval-augmented language model pre-training”
- Michael Günther, “Late chunking: Contextual chunk embeddings using long-context embedding models”
- Chi Han, “LM-infinite: Zero-shot extreme length generalization for large language models”
- Dongchen Han, “Flatten transformer: Vision transformer using focused linear attention”
- Yuhang Han, “Rethinking token reduction in mllms: Towards a unified paradigm for training-free acceleration”
- Tanveer Hannan, “Revisionllm: Recursive vision-language model for temporal grounding in hour-long videos”
- Conghui He, “Wanjuan: A comprehensive multimodal dataset for advancing english and chinese large models”
- Jiaao He, “Fastdecode: High-throughput gpu-efficient llm serving using heterogeneous pipelines”
- Junqing He, “Never lost in the middle: Mastering long-context question answering with position-agnostic decompositional training”
- Junqing He, “Never lost in the middle: Mastering long-context question answering with position-agnostic decompositional training”
- Wei He, “Dureader: a chinese machine reading comprehension dataset from real-world applications”
- Yancheng He, “Can large language models detect errors in long chain-of-thought reasoning?”
- Zhenyu He, “Two stones hit one bird: Bilevel positional encoding for better length extrapolation”
- Dan Hendrycks, “Measuring massive multitask language understanding”
- Amey Hengle, “Multilingual needle in a haystack: Investigating long-context behavior of multilingual large language models”
- Christian Herold, “Improving long context document-level machine translation”
- Lukas Hilgert, “Evaluating and training long-context large language models for question answering on scientific papers”
- Xanh Ho, “Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps”
- Jordan Hoffmann, “An empirical analysis of compute-optimal large language model training”
- Jiwoo Hong, “ORPO: Monolithic preference optimization without reference model”
- Coleman Hooper, “Speed: Speculative pipelined execution for efficient decoding”
- Coleman Hooper, “Kvquant: Towards 10 million context length llm inference with kv cache quantization”
- Pedram Hosseini, “A benchmark for long-form medical question answering”
- Cheng-Ping Hsieh, “Ruler: What’s the real context size of your long-context language models?”
- Cunchen Hu, “Memserve: Context caching for disaggregated llm serving with elastic memory pool”
- Junhao Hu, “Efficient long-decoding inference with reasoning-aware attention sparsity”
- Xueyu Hu, “Os agents: A survey on mllm-based agents for general computing devices use”
- Yutong Hu, “Can perplexity reflect large language model’s ability in long text understanding?”
- Zhiyuan Hu, “Longrecipe: Recipe for efficient long context generalization in large language models”
- Luyang Huang, “Efficient attentions for long document summarization”
- Qian Huang, “Benchmarking large language models as AI research agents”
- Siming Huang, “Opencoder: The open cookbook for top-tier code large language models”
- Wei Huang, “Slim-llm: Salience-driven mixed-precision quantization for large language models”
- Yunpeng Huang, “Advancing transformer architecture in long-context large language models: A comprehensive survey”
- Yuzhen Huang, “Compression represents intelligence linearly”
- Zhen Huang, “O1 replication journey–part 2: Surpassing o1-preview through simple distillation, big progress or bitter lesson?”
- Binyuan Hui, “Qwen2.5-coder technical report”
- DeLesley Hutchins, “Block-recurrent transformers”
- Inflection, “I’m pi, your personal ai”
- Naoya Inoue, “R4c: A benchmark for evaluating rc systems to get the right answer for the right reason”
- Gautier Izacard, “Leveraging passage retrieval with generative models for open domain question answering”
- Gautier Izacard, “Atlas: Few-shot learning with retrieval augmented language models”
- Sam Ade Jacobs, “Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models”
- Arthur Jacot, “Neural tangent kernel: Convergence and generalization in neural networks”
- Alon Jacovi, “The facts grounding leaderboard: Benchmarking llms’ ability to ground responses to long-form input”
- Young Kyun Jang, “MATE: meet at the embedding - connecting images with long texts”
- Minbyul Jeong, “Olaph: Improving factuality in biomedical long-form question answering”
- Wonje Jeung, “Large language models still exhibit bias in long text”
- Albert Q. Jiang, “Mistral 7b”
- Chaoyi Jiang, “Efficient llm inference with i/o-aware partial kv cache recomputation”
- Huiqiang Jiang, “LLMLingua: Compressing prompts for accelerated inference of large language models”
- Huiqiang Jiang, “Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention”
- Huiqiang Jiang, “Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention”
- Huiqiang Jiang, “LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression”
- Juyong Jiang, “A survey on large language models for code generation”
- Yixing Jiang, “Many-shot in-context learning in multimodal foundation models”
- Ziyan Jiang, “Longrag: Enhancing retrieval-augmented generation with long-context llms”
- Ziyan Jiang, “Longrag: Enhancing retrieval-augmented generation with long-context llms”
- Carlos E. Jimenez, “Swe-bench: Can language models resolve real-world github issues?”
- Bowen Jin, “Long-context llms meet RAG: overcoming challenges for long inputs in RAG”
- Bowen Jin, “Long-context llms meet rag: Overcoming challenges for long inputs in rag”
- Hanlei Jin, “A comprehensive survey on process-oriented automatic text summarization with exploration of llm-based methods”
- Hongye Jin, “Growlength: Accelerating llms pretraining by progressively growing training length”
- Hongye Jin, “Llm maybe longlm: Self-extend llm context window without tuning”
- Eunkyung Jo, “Understanding the impact of long-term memory on self-disclosure with large language model-driven chatbots for public health intervention”
- Ashutosh Joshi, “Reaper: Reasoning based retrieval planning for complex rag systems”
- Mandar Joshi, “Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension”
- Dongwon Jung, “Familiarity-aware evidence compression for retrieval-augmented generation”
- Hoyoun Jung, “Discrete prompt compression with reinforcement learning”
- Rudolph Emil Kalman, “A new approach to linear filtering and prediction problems”
- Greg Kamradt, “Needle in a haystack - pressure testing llms”
- Hao Kang, “Gear: An efficient kv cache compression recipe for near-lossless generative inference of llm”
- Sayash Kapoor, “Promises and pitfalls of artificial intelligence for legal applications”
- Marzena Karpinska, “One thousand and one pairs: A “novel” challenge for long-context language models”
- Angelos Katharopoulos, “Transformers are rnns: Fast autoregressive transformers with linear attention”
- Amirhossein Kazemnejad, “The impact of positional encoding on length generalization in transformers”
- Urvashi Khandelwal, “Generalization through memorization: Nearest neighbor language models”
- Heehoon Kim, “Tccl: Discovering better communication paths for pcie gpu clusters”
- Youngjoo Kim, “Introduction to kalman filter and its applications”
- Tomáš Kočisky, “The narrativeqa reading comprehension challenge”
- Tomáš Kočiský, “The NarrativeQA reading comprehension challenge”
- Abdullatif Köksal, “Longform: Effective instruction tuning with reverse instructions”
- Vijay Anand Korthikanti, “Reducing activation recomputation in large transformer models”
- Mario Michael Krell, “Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance”
- Kalpesh Krishna, “Hurdles to progress in long-form question answering”
- Sayali Kulkarni, “Aquamuse: Automatically generating datasets for query-based multi-document summarization”
- Ishita Kumar, “Longlamp: A benchmark for personalized long-form text generation”
- Achintya Kundu, “Enhancing training efficiency using packing with flash attention”
- Yuri Kuratov, “Babilong: Testing the limits of llms with long context reasoning-in-a-haystack”
- Wai-Chung Kwan, “M4le: A multi-ability multi-range multi-task multi-domain long-context evaluation benchmark for large language models”
- Tom Kwiatkowski, “Natural questions: A benchmark for question answering research”
- Woosuk Kwon, “Efficient memory management for large language model serving with pagedattention”
- Philippe Laban, “Summary of a haystack: A challenge to long-context llms and rag systems”
- Perplexity Labs, “perplexity”
- Jack Lanchantin, “Learning to reason and memorize with self-notes”
- Gibbeum Lee, “Prompted llms as chatbot modules for long open-domain conversation”
- Jinhyuk Lee, “Can long-context language models subsume retrieval, rag, sql, and more?”
- Kuang-Huei Lee, “A human-inspired reading agent with gist memory of very long contexts”
- Taewhoo Lee, “Ethic: Evaluating large language models on long-context tasks with high information coverage”
- Yoonjoo Lee, “Qasa: advanced question answering on scientific articles”
- Fangyu Lei, “S3eval: A synthetic, scalable, systematic evaluation suite for large language model”
- Jure Leskovec, “Mining of massive data sets”
- Brian Lester, “The power of scale for parameter-efficient prompt tuning”
- Yaniv Leviathan, “Fast inference from transformers via speculative decoding”
- Yaniv Leviathan, “Selective attention improves transformer”
- Yoav Levine, “The inductive bias of in-context learning: Rethinking pretraining example design”
- Patrick Lewis, “Retrieval-augmented generation for knowledge-intensive nlp tasks”
- Bo Li, “Llava-onevision: Easy visual task transfer”
- Dacheng Li, “How long can context length of open-source llms truly promise?”
- Dacheng Li, “Llms can easily learn to reason from demonstrations structure, not content, is what matters!”
- Haoyang Li, “Demystifying workload imbalances in large transformer model training over variable-length sequences”
- Jiaqi Li, “Loogle: Can long-context language models understand long contexts?”
- Jiashi Li, “Flashmla: Efficient mla decoding kernels”
- Jiwei Li, “A diversity-promoting objective function for neural conversation models”
- Junnan Li, “BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models”
- Ming Li, “From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning”
- Mo Li, “Needlebench: Can llms do retrieval and reasoning in 1 million context window?”
- Qingyuan Li, “Fptq: Fine-grained post-training quantization for large language models”
- Rui Li, “Temporal preference optimization for long-form video understanding”
- Shanda Li, “Functional interpolation for relative positions improves long context transformers”
- Shilong Li, “Graphreader: Building graph-based agent to enhance long-context abilities of large language models”
- Shilong Li, “2d-dpo: Scaling direct preference optimization with 2-dimensional supervision”
- Tianle Li, “Long-context llms struggle with long in-context learning”
- Xinhao Li, “Videochat-flash: Hierarchical compression for long-context video modeling”
- Yanyang Li, “Making long-context language models better multi-hop reasoners”
- Yucheng Li, “Compressing context to enhance inference efficiency of large language models”
- Yucheng Li, “Scbench: A kv cache-centric analysis of long-context methods”
- Yuetai Li, “Small models struggle to learn from strong reasoners”
- Yuhong Li, “Snapkv: LLM knows what you are looking for before generation”
- Yuhui Li, “Eagle: speculative sampling requires rethinking feature uncertainty”
- Zhuowan Li, “Retrieval augmented generation or long-context llms? a comprehensive study and hybrid approach”
- Zongqian Li, “Prompt compression for large language models: A survey”
- Zongqian Li, “Prompt compression for large language models: A survey”
- Zongqian Li, “500xcompressor: Generalized prompt compression for large language models”
- Hao Liang, “Keyvideollm: Towards large-scale video keyframe selection”
- Xiaobo Liang, “Open-ended long text generation via masked language modeling”
- Opher Lieber, “Jamba: A hybrid transformer-mamba language model”
- Chin-Yew Lin, “Rouge: A package for automatic evaluation of summaries”
- Ji Lin, “Awq: Activation-aware weight quantization for on-device llm compression and acceleration”
- Zhan Ling, “Longreason: A synthetic long-context reasoning benchmark via context expansion”
- Lucas D. Lingle, “Transformer-vq: Linear-time transformers via vector quantization”
- Barys Liskavets, “Prompt compression with context-aware sentence encoding for fast and improved llm inference”
- Aixin Liu, “Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model”
- Hao Liu, “Ring attention with blockwise transformers for near-infinite context”
- Hao Liu, “World model on million-length video and language with ringattention”
- Jiaheng Liu, “Roleagent: Building, interacting, and benchmarking high-quality role-playing agents from scripts”
- Jiaheng Liu, “E2-LLM: Efficient and extreme length extension of large language models”
- Jiawei Liu, “Repoqa: Evaluating long context code understanding”
- Junpeng Liu, “Visualwebbench: How far have multimodal llms evolved in web page understanding and grounding?”
- Junwei Liu, “Stall+: Boosting llm-based repository-level code completion with static analysis”
- Junyi Liu, “TCRA-LLM: Token compression retrieval augmented large language model for inference cost reduction”
- Nelson F Liu, “Lost in the middle: How language models use long contexts”
- Peiyu Liu, “Unlocking data-free low-bit quantization with matrix decomposition for kv cache compression”
- Qian Liu, “Regmix: Data mixture as regression for language model pre-training”
- Shukai Liu, “Mdeval: Massively multilingual code debugging”
- Tianyang Liu, “Repobench: Benchmarking repository-level code auto-completion systems”
- Ting Liu, “Multi-stage vision token dropping: Towards efficient multimodal large language model”
- Wei Liu, “What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning”
- Xiang Liu, “Longgenbench: Long-context generation benchmark”
- Xiaoran Liu, “Scaling laws of rope-based extrapolation”
- Xiaoran Liu, “LongWanjuan: Towards systematic measurement for long text quality”
- Xiaoran Liu, “Thus spake long-context large language model”
- Yang Liu, “ERNIE-SPARSE: learning hierarchical efficient transformer through regularized self-attention”
- Yiheng Liu, “Understanding llms: A comprehensive overview from training to inference”
- Yuhan Liu, “Cachegen: Kv cache compression and streaming for fast large language model serving”
- Zichang Liu, “Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time”
- Zirui Liu, “KIVI: A tuning-free asymmetric 2bit quantization for KV cache”
- Yinghan Long, “Segmented recurrent transformer: An efficient sequence-to-sequence model”
- Anton Lozhkov, “Starcoder 2 and the stack v2: The next generation”
- Enzhe Lu, “Moba: Mixture of block attention for long-context llms”
- Enzhe Lu, “Moba: Mixture of block attention for long-context llms”
- Keer Lu, “Datasculpt: Crafting data landscapes for long-context llms through multi-objective partitioning”
- Yi Lu, “A controlled study on long context extension and generalization in llms”
- Yi Lu, “Longheads: Multi-head attention is secretly a long context processor”
- Evan Lucas, “Extra global attention designation using keyword detection in sparse transformer architectures”
- Qinyu Luo, “Repoagent: An llm-powered open-source framework for repository-level code documentation generation”
- Chenyang Lyu, “A paradigm shift: The future of machine translation lies with large language models”
- Feipeng Ma, “Visual perception by large language model’s weights”
- Xinbei Ma, “Query rewriting in retrieval-augmented large language models”
- Xinyin Ma, “Cot-valve: Length-compressible chain-of-thought tuning”
- Xueguang Ma, “Fine-tuning llama for multi-stage text retrieval”
- Yubo Ma, “Mmlongbench-doc: Benchmarking long-context document understanding with visualizations”
- Aman Madaan, “Memory-assisted prompt editing to improve gpt-3 after deployment”
- Seiji Maekawa, “Holistic reasoning with long-context lms: A benchmark for database operations on massive textual data”
- Adyasha Maharana, “D2 pruning: Message passing for balancing diversity and difficulty in data pruning”
- Chaitanya Malaviya, “Expertqa: Expert-curated questions and attributed answers”
- Chaitanya Malaviya, “Dolomites: Domain-specific long-form methodical tasks”
- Ahmed Masry, “Longfin: A multimodal document understanding model for long financial domain documents”
- Ahmed Masry, “Longfin: A multimodal document understanding model for long financial domain documents”
- Sanket Vaibhav Mehta, “Dsi++: Updating transformer memory with new documents”
- Xin Men, “Base of rope bounds context length”
- Kevin Meng, “Locating and editing factual associations in gpt”
- Yu Meng, “Simpo: Simple preference optimization with a reference-free reward”
- Paulius Micikevicius, “Mixed precision training”
- Microsoft, “Microsoft copilot”
- Lesly Miculicich, “Document-level neural machine translation with hierarchical attention networks”
- Tomas Mikolov, “Recurrent neural network based language model”
- Evan Miller, “Attention is off by one”
- Sewon Min, “Ambigqa: Answering ambiguous open-domain questions”
- Sewon Min, “Factscore: Fine-grained atomic evaluation of factual precision in long form text generation”
- MiniMax, “Minimax-01: Scaling foundation models with lightning attention”
- Mayank Mishra, “Granite code models: A family of open foundation models for code intelligence”
- Fengran Mo, “A survey of conversational search”
- Ali Modarressi, “Nolima: Long-context evaluation beyond literal matching”
- Amirkeivan Mohtashami, “Landmark attention: Random-access infinite context length for transformers”
- Jesse Mu, “Learning to compress prompts with gist tokens”
- Niklas Muennighoff, “Generative representational instruction tuning”
- Niklas Muennighoff, “s1: Simple test-time scaling”
- Tsendsuren Munkhdalai, “Leave no context behind: Efficient infinite context transformers with infini-attention”
- Tsendsuren Munkhdalai, “Leave no context behind: Efficient infinite context transformers with infini-attention”
- Arsha Nagrani, “Neptune: The long orbit to benchmarking long video understanding”
- Ramesh Nallapati, “Abstractive text summarization using sequence-to-sequence rnns and beyond”
- Neel Nanda, “Mechanistic interpretability quickstart guide”
- Chien Van Nguyen, “Taipan: Efficient and expressive state space language models with selective attention”
- Tri Nguyen, “Ms marco: A human-generated machine reading comprehension dataset”
- Yuqi Nie, “A survey of large language models for financial applications: Progress, prospects and challenges”
- NVIDIA Corporation, “Nvidia h200”
- Catherine Olsson, “In-context learning and induction heads”
- OpenAI, “New embedding models and api updates”
- OpenAI, “Memory and new controls for chatgpt”
- OpenAI, “Learning to reason with large language models”
- Long Ouyang, “Training language models to follow instructions with human feedback”
- Matteo Pagliardini, “Fast attention over long sequences with dynamic sparse flash attention”
- Arka Pal, “Giraffe: Adventures in expanding context lengths in llms”
- Zhuoshi Pan, “LLMLingua-2: Data distillation for efficient and faithful task-agnostic prompt compression”
- Richard Yuanzhe Pang, “Quality: Question answering with long input texts, yes!”
- Kishore Papineni, “Bleu: a method for automatic evaluation of machine translation”
- Daon Park, “Improving throughput-oriented llm inference with cpu computations”
- J. Park, “Generative agents: Interactive simulacra of human behavior”
- Jongho Park, “Can mamba learn how to learn? A comparative study on in-context learning tasks”
- Pratyush Patel, “Splitwise: Efficient generative llm inference using phase splitting”
- Saurav Pawar, “The what, why, and how of context length extension techniques in large language models - A detailed survey”
- Bo Peng, “RWKV: reinventing rnns for the transformer era”
- Bo Peng, “Eagle and finch: Rwkv with matrix-valued states and dynamic recurrence”
- Bowen Peng, “Ntk-aware scaled rope allows llama models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation”
- Bowen Peng, “Yarn: Efficient context window extension of large language models”
- Houwen Peng, “Fp8-lm: Training fp8 large language models”
- Chau Minh Pham, “Suri: Multi-constraint instruction following for long-form text generation”
- Hung Phan, “Examining long-context large language models for environmental review document comprehension”
- Bowen Ping, “Longdpo: Unlock better long-form generation abilities for llms via critique-augmented stepwise information”
- Hadi Pouransari, “Dataset decomposition: Faster llm training with variable sequence length curriculum”
- Shraman Pramanick, “SPIQA: A dataset for multimodal question answering on scientific papers”
- Ofir Press, “Train short, test long: Attention with linear biases enables input length extrapolation”
- Penghui Qi, “Zero bubble pipeline parallelism”
- Zehan Qi, “Long2rag: Evaluating long-context & long-form retrieval-augmented generation with key point recall”
- Ruoyu Qin, “Mooncake: A kvcache-centric disaggregated architecture for llm serving”
- Yiwei Qin, “O1 replication journey: A strategic progress report–part 1”
- Zhen Qin, “cosformer: Rethinking softmax in attention”
- Zhen Qin, “Lightning attention-2: A free lunch for handling unlimited sequence lengths in large language models”
- Zhen Qin, “Various lengths, constant speed: Efficient language modeling with lightning attention”
- Zexuan Qiu, “Clongeval: A chinese benchmark for evaluating long-context large language models”
- Shanghaoran Quan, “Language models can self-lengthen to generate long texts”
- Haoran Que, “Hellobench: Evaluating long text generation capabilities of large language models”
- Alec Radford, “Improving language understanding by generative pre-training”
- Jack W. Rae, “Compressive transformers for long-range sequence modelling”
- Jack W. Rae, “Scaling language models: Methods, analysis & insights from training gopher”
- Rafael Rafailov, “Direct preference optimization: Your language model is secretly a reward model”
- Colin Raffel, “Exploring the limits of transfer learning with a unified text-to-text transformer”
- Jeff Rasley, “Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters”
- Varshini Reddy, “Docfinqa: A long-context financial reasoning dataset”
- Isaac Rehg, “Kv-compress: Paged kv-cache compression with variable compression rates per attention head”
- Liliang Ren, “Samba: Simple hybrid state space models for efficient unlimited context language modeling”
- Liliang Ren, “Samba: Simple hybrid state space models for efficient unlimited context language modeling”
- Jonathan Roberts, “Needle threading: Can llms follow threads through near-million-scale haystacks?”
- Ivan Rodkin, “Associative recurrent memory transformer”
- Sara Rosenthal, “Clapnq: Cohesive long-form answers from passages in natural questions for rag systems”
- Jie Ruan, “Defining and detecting vulnerability in human evaluation guidelines: A preliminary study towards reliable nlg evaluation”
- Anian Ruoss, “Randomized positional encodings boost length generalization of transformers”
- Anian Ruoss, “Lmact: A benchmark for in-context imitation learning with long multimodal demonstrations”
- Shiwangi Shah Rupesh Bansal, “Deepsearch: Semantic search on multimedia sources like audio, video and images”
- Michael S. Ryoo, “Token turing machines”
- Jon Saad-Falcon, “Benchmarking and building long-context retrieval models with loco and M2-BERT”
- Amir Saeidi, “Triple preference optimization: Achieving better alignment with less data in a single step optimization”
- Teven Le Scao, “Bloom: A 176b-parameter open-access multilingual language model”
- Timo Schick, “Toolformer: Language models can teach themselves to use tools”
- Dale Schuurmans, “Memory augmented large language models are computationally universal”
- Jay Shah, “Flashattention-3: Fast and accurate attention with asynchrony and low-precision”
- Uri Shaham, “Zeroscrolls: A zero-shot benchmark for long text understanding”
- Shivam Shandilya, “Taco-rl: Task aware prompt compression optimization with reinforcement learning”
- Claude Elwood Shannon, “A mathematical theory of communication”
- Bin Shao, “A long-context language model for deciphering and generating bacteriophage genomes”
- Ninglu Shao, “Extensible embedding: A flexible multipler for llm’s context length”
- Zhihong Shao, “Long and diverse text generation with planning-based hierarchical variational model”
- Aditya Sharma, “Losing visual needles in image haystacks: Vision language models are easily distracted in short and long contexts”
- Eva Sharma, “Bigpatent: A large-scale dataset for abstractive and coherent summarization”
- Peter Shaw, “Self-attention with relative position representations”
- Zejiang Shen, “Multi-lexsum: Real-world summaries of civil rights lawsuits at multiple granularities”
- Zhuoran Shen, “Efficient attention: Attention with linear complexities”
- Ying Sheng, “Flexgen: High-throughput generative inference of large language models with a single gpu”
- Kaize Shi, “Compressing long context for enhancing RAG with amr-based concept distillation”
- Weijia Shi, “In-context pretraining: Language modeling beyond document boundaries”
- Weijia Shi, “REPLUG: Retrieval-augmented black-box language models”
- Noah Shinn, “Reflexion: Language agents with verbal reinforcement learning”
- Mohammad Shoeybi, “Megatron-lm: Training multi-billion parameter language models using model parallelism”
- Disha Shrivastava, “Repofusion: Training code models to understand your repository”
- Disha Shrivastava, “Repository-level prompt generation for large language models of code”
- Shuzheng Si, “Gateau: Selecting influential sample for long context alignment”
- Prajwal Singhania, “Loki: Low-rank keys for efficient sparse attention”
- Daria Soboleva, “SlimPajama: A 627B token cleaned and deduplicated version of RedPajama”
- Dingjie Song, “Milebench: Benchmarking mllms in long context”
- Kaiqiang Song, “Zebra: Extending context window with layerwise grouped local-global attention”
- Mingyang Song, “Counting-stars: A multi-evidence, position-aware, and scalable benchmark for evaluating long-context large language models”
- Mohammed Sourouri, “Effective multi-gpu communication using multiple cuda streams and threads”
- spicychat.ai, “Spicychat”
- Konrad Staniszewski, “Structured packing in llm training improves long context utilization”
- Konrad Staniszewski, “Structured packing in llm training improves long context utilization”
- Ivan Stelmakh, “Asqa: Factoid questions meet long-form answers”
- Jianlin Su, “Transformer 10”
- Jianlin Su, “Transformer 12”
- Jianlin Su, “Transformer 17. Online Resource”
- Jianlin Su, “Roformer: Enhanced transformer with rotary position embedding”
- Hanshi Sun, “Triforce: Lossless acceleration of long sequence generation with hierarchical speculative decoding”
- Haotian Sun, “Adaplanner: Adaptive planning from feedback with language models”
- Simeng Sun, “Do long-range language models actually use long-range context?”
- Simeng Sun, “Pearl: Prompting large language models to plan and execute actions over long documents”
- Weiwei Sun, “Is chatgpt good at search? investigating large language models as re-ranking agents”
- Yutao Sun, “A length-extrapolatable transformer”
- Yutao Sun, “Retentive network: A successor to transformer for large language models”
- Yutao Sun, “You only cache once: Decoder-decoder architectures for language models”
- Alon Talmor, “Commonsenseqa: A question answering challenge targeting commonsense knowledge”
- Haochen Tan, “Proxyqa: An alternative framework for evaluating long-form text generation with large language models”
- Weihao Tan, “Towards general computer control: A multimodal agent for red dead redemption II as a case study”
- Matthew Tancik, “Fourier features let networks learn high frequency functions in low dimensional domains”
- Hanlin Tang, “Razorattention: Efficient kv cache compression through retrieval heads”
- Hanlin Tang, “Razorattention: Efficient KV cache compression through retrieval heads”
- Jiaming Tang, “QUEST: Query-aware sparsity for efficient long-context LLM inference”
- Zecheng Tang, “Logo - long context alignment via efficient preference optimization”
- Zecheng Tang, “Logo–long context alignment via efficient preference optimization”
- Zecheng Tang, “L-citeeval: Do long-context models truly leverage context for responding?”
- Yi Tay, “Long range arena: A benchmark for efficient transformers”
- Yi Tay, “Transformer memory as a differentiable search index”
- Coze Team, “Coze”
- Dify Team, “The innovation engine for genai applications”
- Gemini Team, “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context”
- Gemma Team, “Gemma 2: Improving open language models at a practical size”
- Jamba Team, “Jamba-1.5: Hybrid transformer-mamba models at scale”
- Kimi Team, “Kimi k1. 5: Scaling reinforcement learning with llms”
- M-A-P Team, “Supergpqa: Scaling llm evaluation across 285 graduate disciplines”
- Manus Team, “Leave it to manus”
- OpenAI Team, “Computer-using agent”
- OpenAI Team, “Introducing deep research”
- Qwen Team, “Qwen2.5-vl”
- Runchu Tian, “Distance between relevant information pieces causes bias in long-context llms”
- Kushal Tirumala, “D4: improving LLM pretraining via document de-duplication and diversification”
- Hugo Touvron, “Llama: Open and efficient foundation language models”
- Pavan Kumar Anasosalu Vasu, “Fastvlm: Efficient vision encoding for vision language models”
- Ashish Vaswani, “Attention is all you need”
- Saranya Venkatraman, “Collabstory: Multi-llm collaborative story generation and authorship analysis”
- Kiran Vodrahalli, “Michelangelo: Long context evaluations beyond haystacks via latent structure queries”
- Aaron R. Voelker, “Improving spiking dynamical networks: Accurate delays, higher-order synapses, and time cells”
- Elena Voita, “Neurons in large language models: Dead, n-gram, positional”
- Roger Waleffe, “An empirical study of mamba-based language models”
- Alex Wang, “Squality: Building a long-document summarization dataset the hard way”
- Benyou Wang, “Encoding word order in complex embeddings”
- Chong Wang, “Teaching code llms to use autocompletion tools in repository-level code generation”
- Chonghua Wang, “Ada-leval: Evaluating long-context llms with length-adaptable benchmarks”
- Guanzhi Wang, “Voyager: An open-ended embodied agent with large language models”
- Haonan Wang, “When precision meets position: Bfloat16 breaks down rope in long-context training”
- Hengyi Wang, “Multimodal needle in a haystack: Benchmarking long-context capability of multimodal large language models”
- Jiaan Wang, “Drt-o1: Optimized deep reasoning translation via long chain-of-thought”
- Kevin Ro Wang, “Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small”
- Lei Wang, “A survey on large language model based autonomous agents”
- Lei Wang, “Mathhay: An automated benchmark for long-context mathematical reasoning in llms”
- Liang Wang, “Query2doc: Query expansion with large language models”
- Liang Wang, “Improving text embeddings with large language models”
- Liang Wang, “Large search model: Redefining search stack in the era of llms”
- Longyue Wang, “Document-level machine translation with large language models”
- Longyue Wang, “Benchmarking and improving long-text translation with large language models”
- Minzheng Wang, “Leave no document behind: Benchmarking long-context llms with extended multi-doc qa”
- Peng Wang, “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution”
- Sinong Wang, “Linformer: Self-attention with linear complexity”
- Suyuchen Wang, “Resonance rope: Improving context length generalization of large language models”
- Tiannan Wang, “Weaver: Foundation models for creative writing”
- Ting Wang, “A study of extractive summarization of long documents incorporating local topic and hierarchical information”
- Weizhi Wang, “Augmenting language models with long-term memory”
- Xidong Wang, “Longllava: Scaling multi-modal llms to 1000 images efficiently via hybrid architecture”
- Xindi Wang, “Beyond the limits: A survey of techniques to extend the context length in large language models”
- Xingyao Wang, “Openhands: An open platform for ai software developers as generalist agents”
- Yanli Wang, “Repotransbench: A real-world benchmark for repository-level code translation”
- Yu Wang, “MEMORYLLM: towards self-updatable large language models”
- Zekun Moore Wang, “Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models”
- Ziyang Wang, “Videotree: Adaptive tree-based video representation for LLM reasoning on long videos”
- Benjamin Warner, “Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference”
- Jerry Wei, “Long-form factuality in large language models”
- Yuetian Weng, “Longvlm: Efficient long video understanding via large language models”
- Jason Weston, “Towards ai-complete question answering: A set of prerequisite toy tasks”
- wiki, “Printing press”
- wiki, “Library of Alexandria”
- wiki, “Chinese astronomy”
- David Wingate, “Prompt compression and contrastive conditioning for controllability and toxicity reduction in language models”
- Sam Wiseman, “Challenges in data-to-document generation”
- Chuhan Wu, “Hi-transformer: Hierarchical interactive transformer for efficient and effective long document modeling”
- Di Wu, “Longmemeval: Benchmarking chat assistants on long-term interactive memory”
- Han Wu, “Vcsum: A versatile chinese meeting summarization dataset”
- Haoning Wu, “Longvideobench: A benchmark for long-context interleaved video-language understanding”
- Longyun Wu, “Longattn: Selecting long-context training data via token-level attention”
- Qingyang Wu, “Memformer: The memory-augmented transformer”
- Tong Wu, “An efficient recipe for long context extension via middle-focused positional encoding”
- Wenhao Wu, “Long context alignment with short instructions and synthesized positions”
- Wenhao Wu, “Retrieval head mechanistically explains long-context factuality”
- Xianjie Wu, “Tablebench: A comprehensive and complex benchmark for table question answering”
- Xiaodong Wu, “Lifbench: Evaluating the instruction following performance and stability of large language models in long-context scenarios”
- Yuhao Wu, “Longgenbench: Benchmarking long-form generation in long context llms”
- Yuhuai Wu, “Memorizing transformers”
- Yuyang Wu, “When more is less: Understanding chain-of-thought length in llms”
- Haocheng Xi, “Coat: Compressing optimizer states and activation for memory-efficient fp8 training”
- Zhiheng Xi, “The rise and potential of large language model based agents: A survey”
- Zhiheng Xi, “The rise and potential of large language model based agents: A survey”
- Chunqiu Steven Xia, “Agentless: Demystifying llm-based software engineering agents”
- Heming Xia, “Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding”
- Heming Xia, “Tokenskip: Controllable chain-of-thought compression in llms”
- Mengzhou Xia, “LESS: Selecting influential data for targeted instruction tuning”
- Guangxuan Xiao, “Smoothquant: Accurate and efficient post-training quantization for large language models”
- Guangxuan Xiao, “Duoattention: Efficient long-context llm inference with retrieval and streaming heads”
- Guangxuan Xiao, “Efficient streaming language models with attention sinks”
- Guangxuan Xiao, “Efficient streaming language models with attention sinks”
- Tianbao Xie, “Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments”
- Wenhan Xiong, “Effective long-context scaling of foundation models”
- Wenhan Xiong, “Effective long-context scaling of foundation models”
- Yunyang Xiong, “Nyströmformer: A nyström-based algorithm for approximating self-attention”
- Zheyang Xiong, “From artificial needles to real haystacks: Improving retrieval capabilities in llms by finetuning on synthetic data”
- Fangyuan Xu, “Recomp: Improving retrieval-augmented lms with compression and selective augmentation”
- Fangyuan Xu, “A critical evaluation of evaluations for long-form question answering”
- Jiale Xu, “vtensor: Flexible virtual tensor management for efficient llm serving”
- Peng Xu, “Chatqa 2: Bridging the gap to proprietary llms in long context and rag capabilities”
- Xiaoyue Xu, “Stress-testing long-context language models with lifelong icl and task haystack”
- Zhe Xu, “Detectiveqa: Evaluating long-context reasoning on detective novels”
- ZHAO XUANLEI, “Hetegen: Efficient heterogeneous parallel inference for large language models on resource-constrained devices”
- Fuzhao Xue, “Longvila: Scaling long-context visual language models for long videos”
- Ai Ming Yang, “Baichuan 2: Open large-scale language models”
- An Yang, “Qwen2. 5-1m technical report”
- Bowen Yang, “Rope to nope and back again: A new hybrid attention strategy”
- Dongjie Yang, “PyramidInfer: Pyramid KV cache compression for high-throughput LLM inference”
- Jian Yang, “Evaluating and aligning codellms on human preference”
- Jian Yang, “Execrepobench: Multi-level executable code completion evaluation”
- John Yang, “Swe-agent: Agent-computer interfaces enable automated software engineering”
- Kevin Yang, “Re3: Generating longer stories with recursive reprompting and revision”
- Lijie Yang, “Tidaldecode: Fast and accurate llm decoding with position persistent sparse attention”
- Senqiao Yang, “Visionzip: Longer is better but not necessary in vision language models”
- Wenkai Yang, “Towards thinking-optimal scaling of test-time compute for llm reasoning”
- Yi Yang, “Wikiqa: A challenge dataset for open-domain question answering”
- Zeyuan Yang, “Vca: Video curious agent for long video understanding”
- Zhilin Yang, “Hotpotqa: A dataset for diverse, explainable multi-hop question answering”
- Zichao Yang, “Hierarchical attention networks for document classification”
- Shunyu Yao, “React: Synergizing reasoning and acting in language models”
- Zhewei Yao, “Zeroquant: Efficient and affordable post-training quantization for large-scale transformers”
- Jiabo Ye, “mplug-owl3: Towards long image-sequence understanding in multi-modal large language models”
- Jiasheng Ye, “Data mixing laws: Optimizing data mixtures by predicting language modeling performance”
- Lu Ye, “Chunkattention: Efficient self-attention with prefix-aware kv cache and two-phase partition”
- Xi Ye, “Longproc: Benchmarking long-context language models on long procedural generation”
- Howard Yen, “Helmet: How to evaluate long-context language models effectively and thoroughly”
- Shukang Yin, “T2vid: Translating long text into multi-image is the catalyst for video-llms”
- Chanwoong Yoon, “CompAct: Compressing retrieved documents actively for question answering”
- Chengye Yu, “Twinpilots: A new computing paradigm for gpu-cpu parallel llm inference”
- Haofei Yu, “TRAMS: training-free memory selection for long-range language modeling”
- Sicheng Yu, “Framevoyager: Learning to query frames for video large language models”
- Tan Yu, “In defense of RAG in the era of long-context language models”
- Tao Yu, “Collage: Light-weight low-precision strategy for llm training”
- Ann Yuan, “Wordcraft: story writing with large language models”
- Danlong Yuan, “Remamba: Equip mamba with effective long-sequence modeling”
- Jingyang Yuan, “Native sparse attention: Hardware-aligned and natively trainable sparse attention”
- Jingyang Yuan, “Native sparse attention: Hardware-aligned and natively trainable sparse attention”
- Tao Yuan, “Lv-eval: A balanced long-context benchmark with 5 length levels up to 256k”
- Yuxuan Yue, “Wkvquant: Quantizing weight and key/value cache for large language models gains more”
- Manzil Zaheer, “Big bird: Transformers for longer sequences”
- Andy Zeng, “Socratic models: Composing zero-shot multimodal reasoning with language”
- Zhiyuan Zeng, “Revisiting the test-time scaling of o1-like models: Do they truly possess test-time scaling capabilities?”
- Alexander Zhang, “Codecriticbench: A holistic code critique benchmark for large language models”
- Fengji Zhang, “Repocoder: Repository-level code completion through iterative retrieval and generation”
- Ge Zhang, “Map-neo: Highly capable and transparent bilingual large language model series”
- Jiacheng Zhang, “Improving the transformer translation model with document-level context”
- Jiajie Zhang, “Longcite: Enabling llms to generate fine-grained citations in long-context qa”
- Jiajie Zhang, “Longreward: Improving long-context large language models with ai feedback”
- Jingqing Zhang, “PEGASUS: pre-training with extracted gap-sentences for abstractive summarization”
- Jintian Zhang, “Lightthinker: Thinking step-by-step compression”
- Jun Zhang, “Draft& verify: Lossless large language model acceleration via self-speculative decoding”
- Kechi Zhang, “Hirope: Length extrapolation for code models using hierarchical position”
- Lei Zhang, “Marathon: A race through the realm of long context with large language models”
- Pan Zhang, “Internlm-xcomposer-2.5: A versatile large vision language model supporting long-contextual input and output”
- Peitian Zhang, “Long context compression with activation beacon”
- Qianchi Zhang, “Adacomp: Extractive context compression with adaptive predictor for retrieval-augmented large language models”
- Susan Zhang, “Opt: Open pre-trained transformer language models”
- Tianyi Zhang, “Bertscore: Evaluating text generation with bert”
- Tianyi Zhang, “Kv cache is 1 bit per channel: Efficient large language model inference with coupled quantization”
- Wei Zhang, “Interpreting and improving large language models in arithmetic calculation”
- Xiaokang Zhang, “Tablellm: Enabling tabular data manipulation by llms in real office usage scenarios”
- Xingxing Zhang, “HIBERT: document level pre-training of hierarchical bidirectional transformers for document summarization”
- Xinrong Zhang, “Extending long context evaluation beyond 100k tokens”
- Xuan Zhang, “Lighttransfer: Your long-context LLM is secretly a hybrid model with effortless adaptation”
- Yuntong Zhang, “Autocoderover: Autonomous program improvement”
- Yusen Zhang, “Chain of agents: Large language models collaborating on long-context tasks”
- Yuxiang Zhang, “o1-coder: an o1 replication for coding”
- Zhenyu Zhang, “H2o: Heavy-hitter oracle for efficient generative inference of large language models”
- Zhenyu Zhang, “Found in the middle: How language models use long contexts better via plug-and-play positional encoding”
- Zhihan Zhang, “Analyzing temporal complex events with large language models? a benchmark towards temporal, long context understanding”
- Chenggang Zhao, “Deepgemm: clean and efficient fp8 gemm kernels with fine-grained scaling”
- Hanyu Zhao, “Goldminer: Elastic scaling of training data pre-processing pipelines for deep learning”
- Jun Zhao, “Longagent: Scaling language models to 128k context through multi-agent collaboration”
- Liang Zhao, “Length extrapolation of transformers: A survey from the perspective of positional encoding”
- Liang Zhao, “Longskywork: A training recipe for efficiently extending context length in large language models”
- Tiancheng Zhao, “Omchat: A recipe to train multimodal language models with strong long context and video understanding”
- Yanli Zhao, “Pytorch fsdp: experiences on scaling fully sharded data parallel”
- Yilong Zhao, “Atom: Low-bit quantization for efficient and accurate llm serving”
- Yu Zhao, “Marco-o1: Towards open reasoning models for open-ended solutions”
- Chuanyang Zheng, “Dape v2: Process attention score as feature map for length extrapolation”
- Chuanyang Zheng, “Dape: Data-adaptive positional encoding for length extrapolation”
- Lianmin Zheng, “Judging llm-as-a-judge with mt-bench and chatbot arena”
- Lianmin Zheng, “Efficiently programming large language models using sglang”
- Ming Zhong, “Qmsum: A new benchmark for query-based multi-domain meeting summarization”
- Wanjun Zhong, “Memorybank: Enhancing large language models with long-term memory”
- Yinmin Zhong, “{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving”
- Junjie Zhou, “MLVU: A comprehensive benchmark for multi-task long video understanding”
- Shuyan Zhou, “Webarena: A realistic web environment for building autonomous agents”
- Wangchunshu Zhou, “Efficient prompting via dynamic in-context learning”
- Wangchunshu Zhou, “Recurrentgpt: Interactive generation of (arbitrarily) long text”
- Wangchunshu Zhou, “Agents: An open-source framework for autonomous language agents”
- Wangchunshu Zhou, “Agents: An open-source framework for autonomous language agents”
- Wangchunshu Zhou, “Symbolic learning enables self-evolving agents”
- Xiabin Zhou, “Dynamickv: Task-aware adaptive kv cache compression for long context llms”
- Zhejian Zhou, “Scaling behavior for large language models regarding numeral systems: An example using pythia”
- Dawei Zhu, “Pose: Efficient context window extension of llms via positional skip-wise training”
- Dawei Zhu, “Longembed: Extending embedding models for long context retrieval”
- Dawei Zhu, “LongEmbed: Extending embedding models for long context retrieval”
- Yuke Zhu, “Focusllava: A coarse-to-fine approach for efficient and effective visual token compression”
- Yutao Zhu, “Large language models for information retrieval: A survey”
- Mingchen Zhuge, “Gptswarm: Language agents as optimizable graphs”
- Heqing Zou, “Hlv-1k: A large-scale hour-long video benchmark for time-specific long video understanding”
- Kaijian Zou, “Retrieval or global context understanding? on many-shot in-context learning for long-context evaluation”