- 前言
- 0.几篇论文的共同点
- 1. NPA: Neural News Recommendation with Personalized Attention
- 2. NAML: Neural News Recommendation with Attentive Multi-View Learning
- 3. LSTUR: Neural News Recommendation with Long- and Short-termUser Representations
- 4. NRMS: Neural News Recommendation with Multi-Head Self-Attention
前言
上上上次组会研一学长汇报了一篇数据集文章:MIND: A Large-scale Dataset for News Recommendation,是微软为新闻推荐而发布的一个数据集。在听汇报时我发现这个数据集非常符合我的需求:
- 首先,新闻推荐需要处理大量的文本信息,正与我未来方向(NLP)有较大关联
- 新闻中包含着大量的实体,有利于探索基于知识(知识图谱)的推荐方法
于是乎,我立马自己去找了这个MIND数据集,数据格式等就暂不介绍,有兴趣的可以自己去官网查看。在其论文中,微软官方实现了几个新闻推荐的算法,如下图:
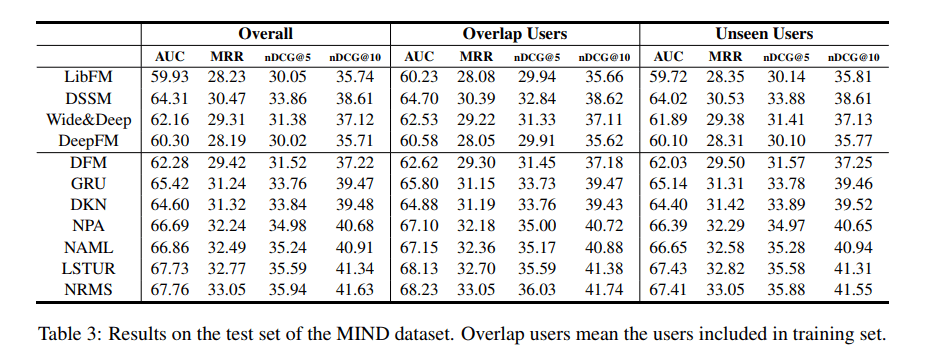
其中,DKN这篇论文我在去年已经读过并研究过代码了,现在效果比它好的有四个,NPA,NAML,LSTUR和NRMS。我去找来并阅读了这四篇论文,发现第1,2,4篇是同一个人(Chuhan Wu,THU)发的…而且他也是第3篇的参与者。
本小菜鸡简单的在我的博客里写一下对这四篇论文的分析和理解~出场顺序大概就按照上图中实验结果从低到高吧^ ^
0.几篇论文的共同点
因为这几篇论文的出处差不多,所以共同点非常多。
- 这四篇论文都是基于三个主要模块:新闻表示模型、用户表示模型和点击预测(包括之前的DKN也是)。其中,新闻表示模型通常都从新闻内容(如新闻标题,新闻类别,新闻内容,新闻内容中包含的实体)中学习,而用户表示通常从用户的浏览历史新闻中学习,点击预测即使用新闻表示和用户表示来计算用户点击这个新闻的概率
- 这四篇论文都大量使用了Attention Mechanism注意力机制(DKN在对用户建模时也使用了)
在总结的时候,对于共同之处,我会一笔带过,重点关注每篇论文真正创新的地方~
1. NPA: Neural News Recommendation with Personalized Attention
1.1 核心思想
不同的用户会有不同的兴趣,同时每个用户往往有多种兴趣。所以,不同的用户可能会因为某个新闻的不同方面而点击这个新闻。
两个直观的感觉:
- 一个新闻标题中的不同单词往往会对用户产生不同的影响
- 并不是一个用户所浏览过的所有新闻都能反映他的偏好
基于这两个直觉,作者分别提出了word-level Attention的news model和news-level Attention的user model~
1.2 模型
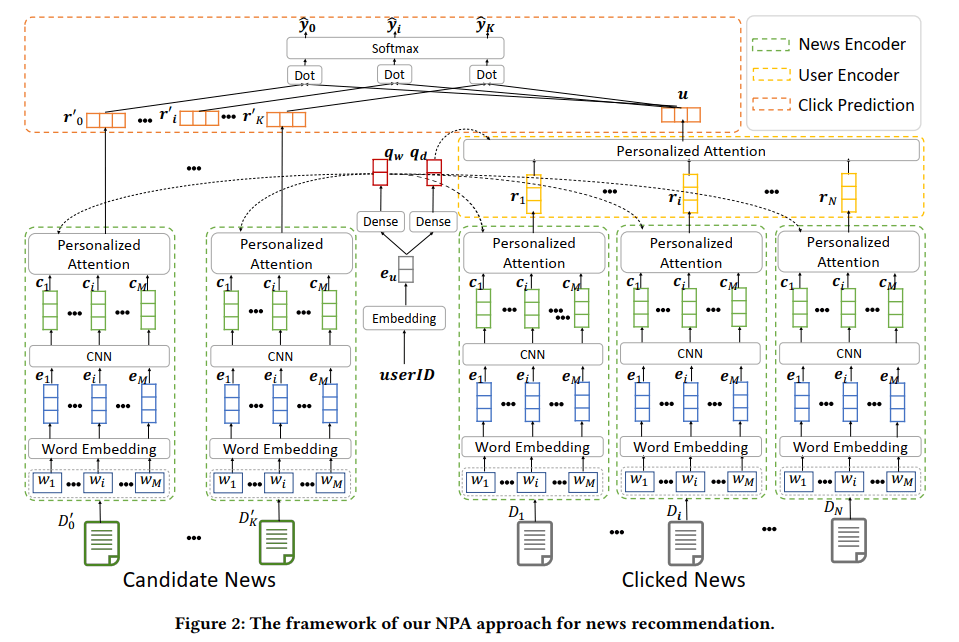
1.2.1 新闻表示模型
新闻表示模型在总模型图中用绿色虚线圈着。
对于每一个输入的新闻(就是其标题文本,一个单词序列),使用新闻表示模型得到最终的表示向量。过程大概如下:
- 词嵌入。即使用词向量(word2vec/glove)技术,将标题中每个单词映射成其对应的向量表示,这样,新闻标题就变成了一个词向量序列$E=(\bm{e_1},…,\bm{e_M})$
- 卷积神经网络。使用卷积神经网络的目的是想学习每个单词的局部上下文信息,也就是使用一个单词和其前后$k$个单词的表示,通过卷积操作来共同学习这个单词的表示。这样,得到一个新的单词表示序列$C=(\bm{c_1},…,\bm{c_M})$
- 单词级别的注意力机制,是本篇论文的核心之一。其目的是:为标题中的每个单词,通过注意力机制得到一个权重。这些权重就可以体现用户对每个单词的关注度,再将所有单词加权平均,得到新闻标题,也就是新闻的最终表示
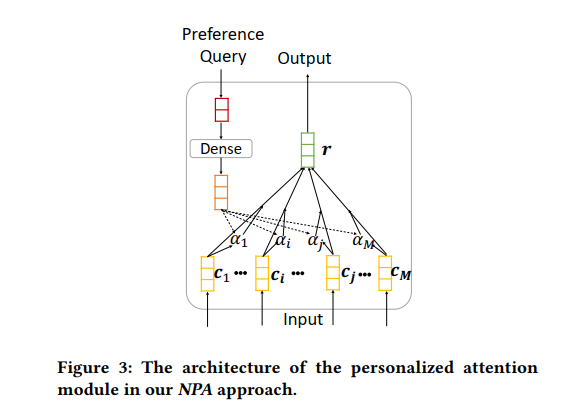
\[\begin{aligned} &a_i=\bm{c_i}^\mathrm{T}tanh(\bm{W_p}\times\bm{q_w}+\bm{b_p})\\ &\alpha_i=\frac{exp(a_i)}{\sum_{j=1}^Mexp(a_j)} \end{aligned}\]
首先需要将每个用户的ID映射成一个向量$\bm{e_u}$(具体方法文中没有讲,可能是随机初始化最后学习得到的,需要去看代码了解)
再将$\bm{e_u}$经过一个非线性映射,得到一个查询向量$\bm{q_w}=ReLU(\bm{V_w}\times\bm{e_u}+\bm{v_w})$,其中$\bm{V_w}$和$\bm{v_m}$都是模型参数(就是会不断被更新的辣种),下面同理!
最后使用查询向量$\bm{q_w}$先经过非线性映射,再与每个单词做点乘,最后使用$\mathrm{softmax}$函数归一化,得到每个单词的注意力。
- 一个新闻最终的表示,就是所有单词的加权平均啦:$\bm{r_i}=\sum_{j=1}^M\alpha_j\bm{c_j}$
当我写完新闻表示模型后,就大松了一口气,为啥呢!因为这个模型(尤其是attention的思想)在后面被用到了数次…包括马上要说到的用户表示模型!
1.2.2 用户表示模型
用户表示模型在总模型图中用黄色虚线圈着。
上文说过,新闻推荐中大家一般都会使用一个用户浏览过的数条历史新闻来表示这个用户。如果有$N$个历史新闻,那么就需要使用$N$次新闻表示模型,来得到它们的表示$(\bm{r_1,…,r_N})$
接下来就是似曾相识的模型了,我们知道,在新闻表示模型中,作者用的是单词级别的注意力机制,而在用户表示模型中,就要使用新闻级别的注意力机制了,由于新闻的表示和单词的表示都是向量,所以两部分全部相同。唯一需要注意的是,在计算用户对每条新闻的注意力$\alpha’_j$时,需要生成一个新的查询向量$\bm{q_d}$,而不能继续使用单词attention时的查询向量$\bm{q_w}$。
所以,同样通过所有新闻的加权平均,我们就得到了用户的最终表示:$\bm{u}=\sum_{j=1}^N\alpha’_j\bm{r_j}$
1.2.3 点击预测模型
本篇文章还有一个看起来比较出色的点就是他最后的点击预测阶段。
作者指出,以往的评分预测都是使用一个新闻表示和一个用户表示,在这些方法中,正例新闻和负例新闻往往都是通过随机采样得到的,这就浪费了负例新闻中的很多信息(我的理解是:训练集中一个用户的负例新闻数量远远大于正例新闻的数量)。另外,新闻总量很大,一次一条还是过于慢了。
所以,作者使用了一个负采样的策略。就是一次采样$K+1$个新闻,其中一个正例,$K$个负例。在训练时,当成一个多分类的任务,采用以下公式:
\[\begin{aligned} &\hat y_i'=\bm{r_i'^\mathrm Tu}\\ &\hat y_i=\frac{exp(\hat y_i')}{\sum_{j=0}^Kexp(\hat y_j')}\\ &L=-\sum_{y_j\in S}log(\hat y_j) \end{aligned}\]训练目标是在正例新闻集合$S$中,最小化似然函数$L$。使用梯度下降等优化算法,就可以更新模型中的所有参数。这种方法在利用了负例新闻的同时,还可以将计算复杂度降低到大约$K$分之一。
1.3 实验结果和其他有价值的东东
下图是一种很好的直观表示注意力的方法:

2. NAML: Neural News Recommendation with Attentive Multi-View Learning
2.1 核心思想
从新闻的多种成分(标题,类别,内容)中学习到有用的表示(即:将不同的成分看成新闻的多个视角)
有如下假设:
- 新闻包含多种成分,对学习其表示有所帮助(我理解为信息可以相互补充)
- 新闻的不同成分通常会蕴含着不同特性(比如标题很简明扼要,内容会长而具体)
2.2 模型
该模型基本与npa相同,只有在news model中,除新闻标题外又考虑了另外两个成分(新闻类别和新闻内容),作为多个view,并使用了一个view-level的attention机制。此外,user model和点击预测模型与npa完全一致。
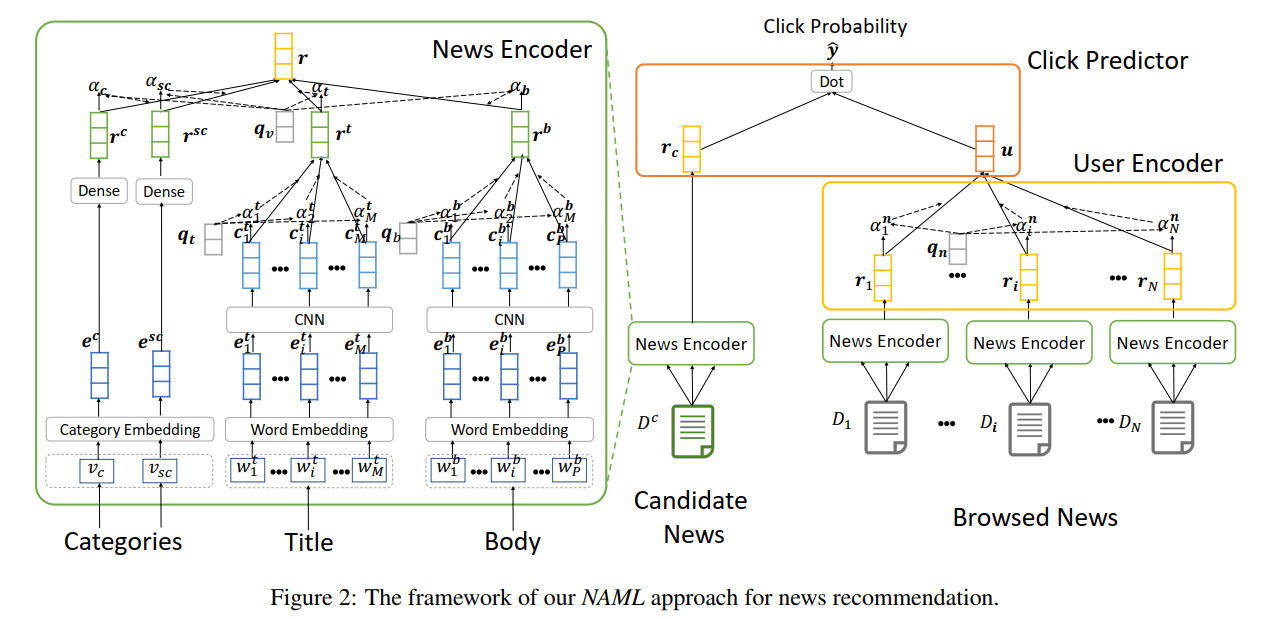
2.2.1 新闻表示模型
其中,新闻标题和新闻内容(与新闻标题相同,都是单词序列,只不过可能会更长)与npa模型中的表示学习方式相同,直接略过,最后的表示分别为$\bm{r^t}$和$\bm{r^b}$。只简单看一下对于新闻类别的表示是怎么得到的:
输入是新闻的类别ID $v_c$和子类别ID $v_{sc}$,通过两层网络得到他们的表示
- 嵌入层: 将离散的ID转换为低维稠密向量$\bm{e^c}$和$\bm{e^{sc}}$
- Dense层:将以上表示分别再经过非线性映射得到$\bm{r^c}$和$\bm{r^{sc}}$
得到四种view的表示后,再使用一个view-level的注意力机制。与npa中的方法相同,还是会为每个用户生成一个查询向量。最后的新闻表示就是四种view的加权平均。
2.3 实验结果和一些重要结论
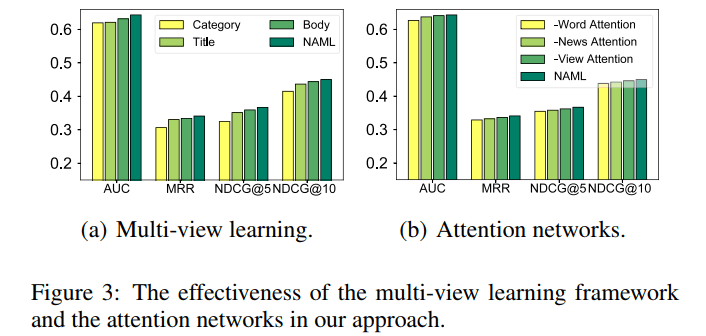
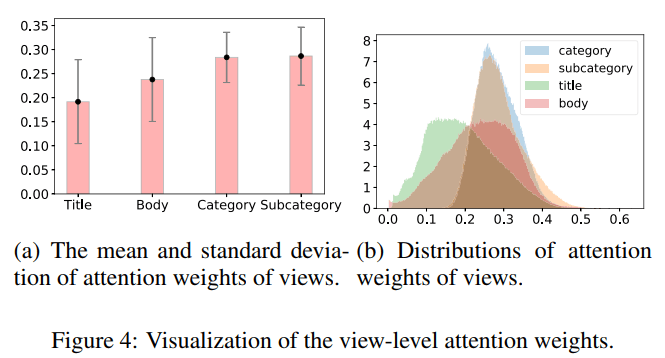
虽然这篇论文与npa基本差不多,但是它的实验给了我们不少的启示:可以看到view-attention的时候,新闻类别所获得的注意力竟然是最高的!
3. LSTUR: Neural News Recommendation with Long- and Short-termUser Representations
3.1 核心思想
通常,一个用户既会有长期的偏好,也会有短期的兴趣。
比如:一个NBA球迷,多年来都会关注篮球新闻,这就是长期的偏好。同时,很多用户的兴趣都会随时间变化,也有可能被短期内的特定事件或暂时的需求而触发。比如:不谙世事的hans也会在11月初关注美国大选。
3.2 模型
3.2.1 新闻表示模型
可以看到,在新闻表示的时候,它吸收了前两篇论文的优点。首先依旧采用了单词级别的注意力机制,并且依然使用了新闻类别这一成分(在上一论文的实验中验证过,新闻类别获得了最多的注意力)
但由于方法与前两篇论文一样,就不多费笔墨了,需要注意最后的新闻表示是由三个表示直接连接得到的。
3.2.2 用户表示模型
这篇文章主要对user model做出了创新。它指出,DKN等模型需要储存每个用户浏览的所有历史新闻,十分笨重、耗费资源。
- 长期偏好表示: 作者使用用户ID的嵌入$\bm{u_l}$来作为用户的长期偏好。具体的步骤这里也讲了:随机初始化+在模型训练时自动学习得到(这也解释了之前一系列基于用户ID的表示的具体步骤)
- 短期兴趣表示: 作者使用了GRU(gated recurrent networks)来根据用户的浏览历史(按时间顺序)学习用户的短期兴趣表示。若新闻序列为$(\bm{e_1,e_2,…,e_k})$,有如下公式(即GRU的几个公式):
- 长期表示与短期表示结合:
作者提出了两种方法,一种是使用用户的长期表示来初始化GRU的初始状态,取GRU的最终状态来作为用户表示(LSTUR-ini),另外一种是直接将用户的长期表示和GRU的最终状态拼接得到用户表示(LSTUR-con)。在实验中,两种方法的得分基本一致,但con方法更稳定。
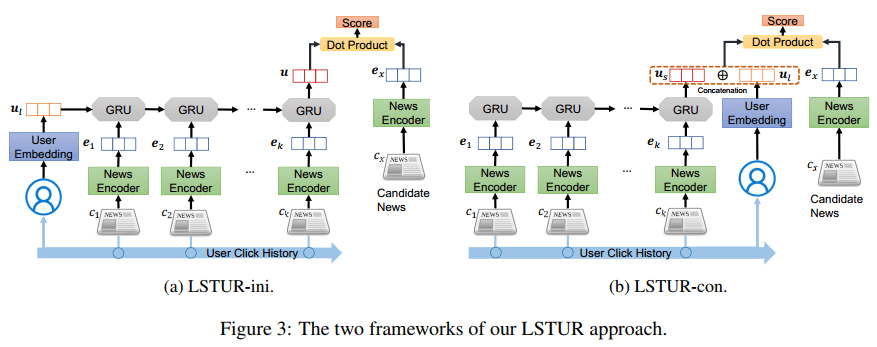
3.2.3 一个trick
作者考虑到在数据集中并不是所有用户都会有长期的偏好(我理解为推荐系统中的长尾效应),所以在训练过程中,作者以一定概率$p$遮掩了一些用户的长期偏好表示(直接设为0),在实验中取得效果的提升
3.3 实验结果及结论
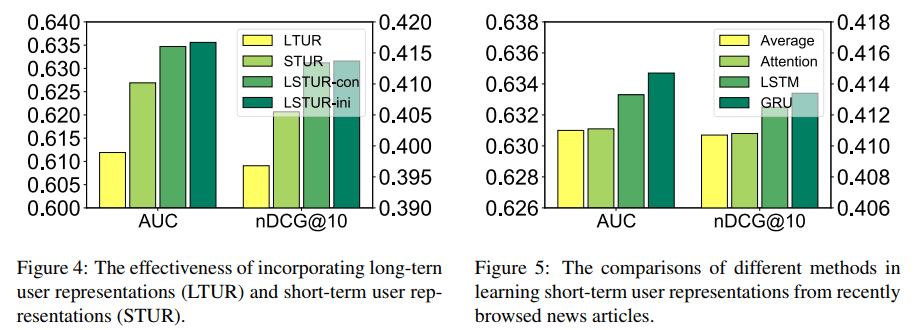
左图为两种长短期表示结合方法的对比,右图为LSTM和GRU的对比,GRU略胜一筹。
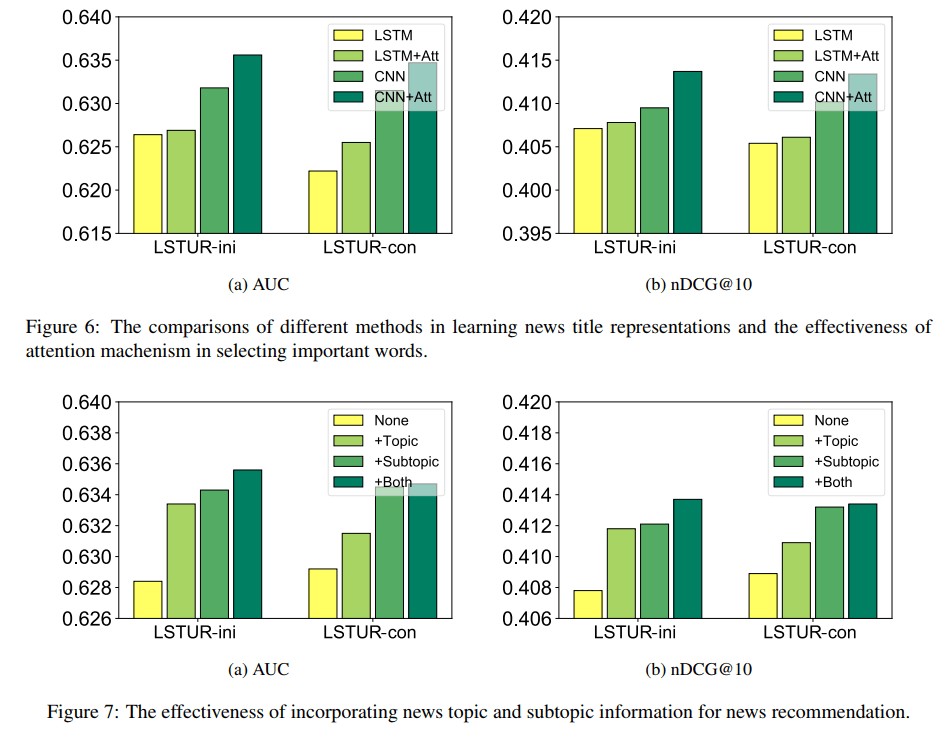
新闻标题表示中,使用CNN和LSTM的对比,CNN略胜一筹。另外,使用attention均会提升。
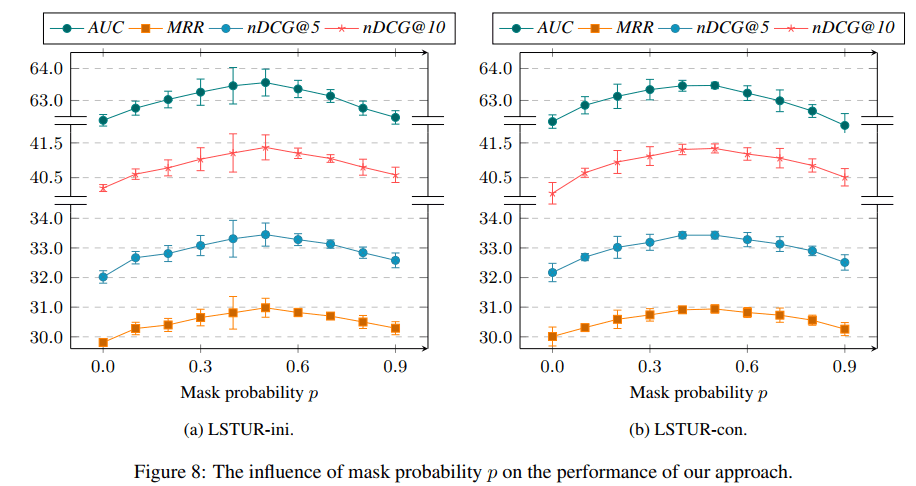
训练时的trick中,长期表示的遮掩概率$p$取值不同时的比较。
4. NRMS: Neural News Recommendation with Multi-Head Self-Attention
4.1 核心思想
从一个新闻标题中学习新闻的表示,或从一个用户浏览的历史新闻中学习用户的表示,很关键的一点是捕捉单词与单词、新闻与新闻之间的相关性。
我们看一下前几篇是怎么考虑的:前几篇论文中都使用了CNN,其目的很简单,是使用每个单词前后的几个词(也就是局部上下文)来共同表示这个单词。但作者指出,CNN的一个不足是不能捕捉”Long distance contexts of words”。
所以作者提出一种self-attention的方法,综合考虑任意两个单词(或新闻)间的关系。我猜这也是从Transformer模型中获得的启发。
4.2 模型
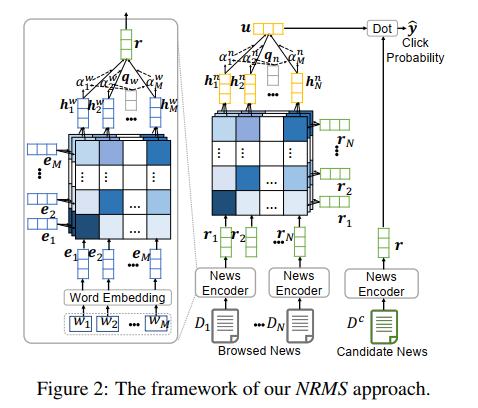
4.2.1 多头自注意力
作者在学习每一个单词的表示的时候,都会用到标题中的所有单词。这就是自注意力机制,具体公式如下:
\[\begin{aligned} &\alpha_{i,j}^k=\frac{\mathrm{exp}(\bm{e_i^\mathrm{T}}\bm{Q_k^we_j})}{\sum_{m=1}^M\mathrm{exp}(\bm{e_i^\mathrm{T}}\bm{Q_k^we_m})}\\ &\bm{h_{i,j}^w}=\bm{V_k^w}(\sum_{j=1}^M\alpha_{i,j}^k\bm{e_j})\\ &\bm{h_i^w}=[\bm{h_{i,1}^w;h_{i,2}^w;...;h_{i,h}^w}] \end{aligned}\]那么,什么是多头呢?就是图中堆叠起来的矩阵。为什么要用多头呢?我个人认为这与计算机视觉中卷积核的作用是类似的,不同的卷积核可以学习到不同的特征。同样,每个头也会关注到不同的层次。
其余内容与前几篇论文一样~
4.3 改进思路
这是本篇博客讲述的最后一篇论文,也是在MIND数据集中获得最好效果的一篇论文。作者提出了一些改进思路,供我们参考:
- 在使用self-attention的同时考虑单词或新闻的位置信息,即引入位置编码
- 考虑使用新闻的多种成分,但如果引入像新闻内容这样的长序列,这是对自注意力机制的一种挑战