前言
本篇博客记录了我对LSTM的理论学习、PyTorch上LSTM和LSTMCell的学习,以及用LSTM对Seq2Seq框架+注意力机制的实现。还包括了很多有趣的细节,包括RNNs对批量序列数据Padding的处理,以及多层RNNs中Dropout的使用等等。
1 LSTM速览
1.1 LSTM流程图
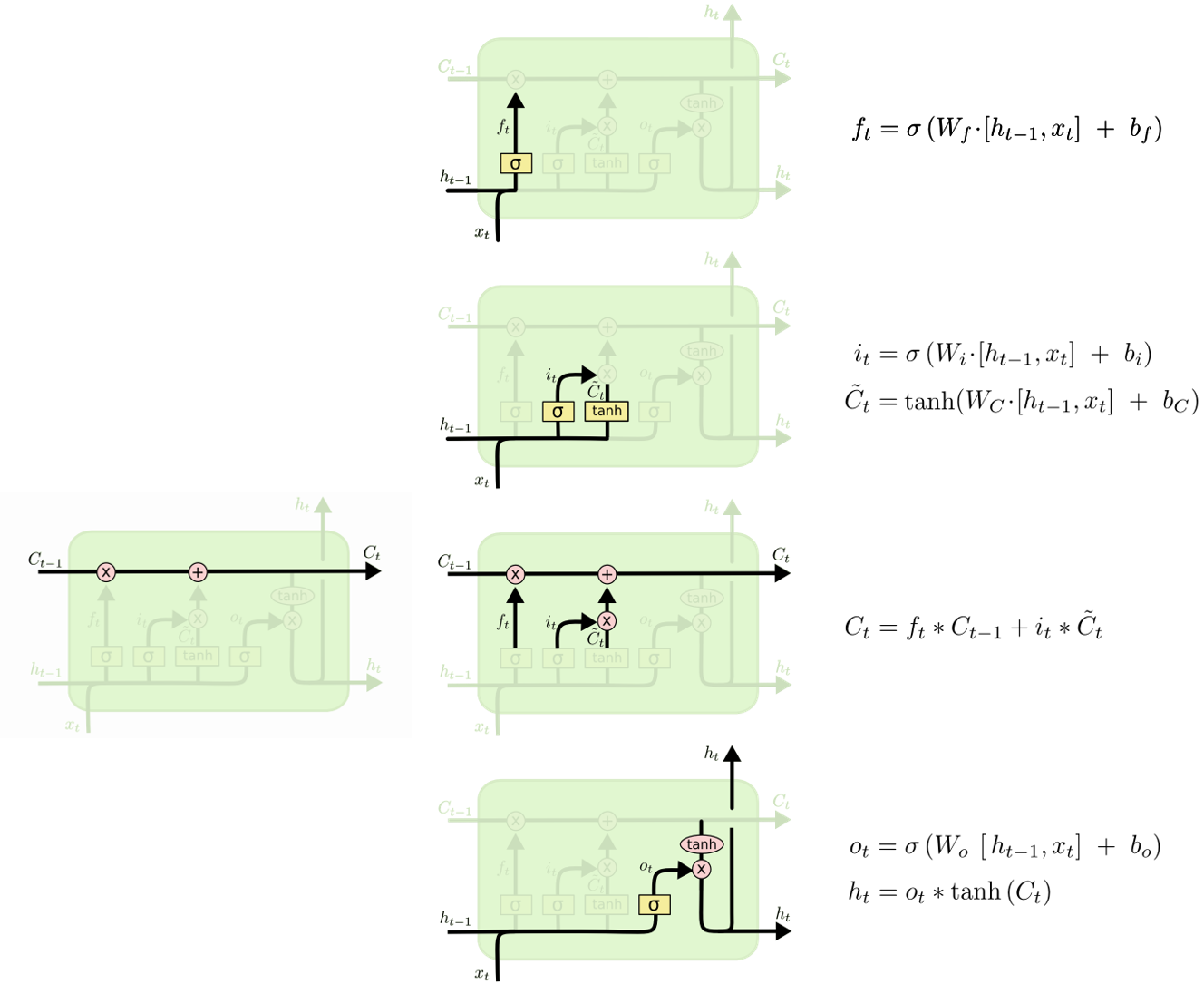
1.2 LSTM的关键
1.3 与RNN的对比
这里引用知乎-予以初始的回答,非常通俗易懂
RNN用于信息传输通路只有一条,并且该通路上的计算包含多次非线性激活操作。长记忆丢失是因为梯度消失,而梯度消失的主谋就是多层激活函数的嵌套,导致梯度反传时越乘越小(激活函数的导数<=1),乃至下溢出。所以后面的梯度传递不到前方,无法建立长时依赖。
LSTM引入了两条计算通道(C和h) 用于信息传输,其中C通道上的计算相对简单,较多的是矩阵的线性转换,没有太多的非线性激活操作。梯度反传时可以在C通道上平稳的传输到前方,从而建立长时依赖。所以C通道主要用于建立长时依赖,h通道用于建立短时依赖。
要说的是,LSTM的设计只是较RNN缓解了梯度消失问题,并没有完全解决。与Transformer的自注意力相比,LSTM的顺序输入的方式影响了模型的并行性,但符合人对序列的理解方式。
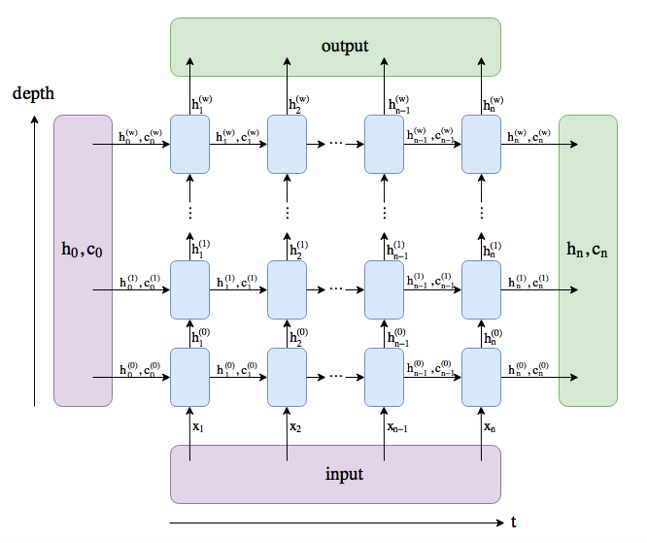
2 多层LSTM
层与层之间用于信息流通的其实还是隐藏状态$h_t^{(l)}$
3 PyTorch中的LSTM
由于深度学习框架对模型成熟的封装,RNN这类模型的输入输出、使用方法基本一致。这里以LSTM为例,可以很容易的掌握其他所有RNNs。
在PyTorch中,有两种形式:LSTM和LSTMCell。两者的关系如上面多层LSTM的图中,一个蓝色块就是LSTMCell,所有蓝色块放在一起就是LSTM。下面是官方文档中LSTM和LSTMCell的公式:
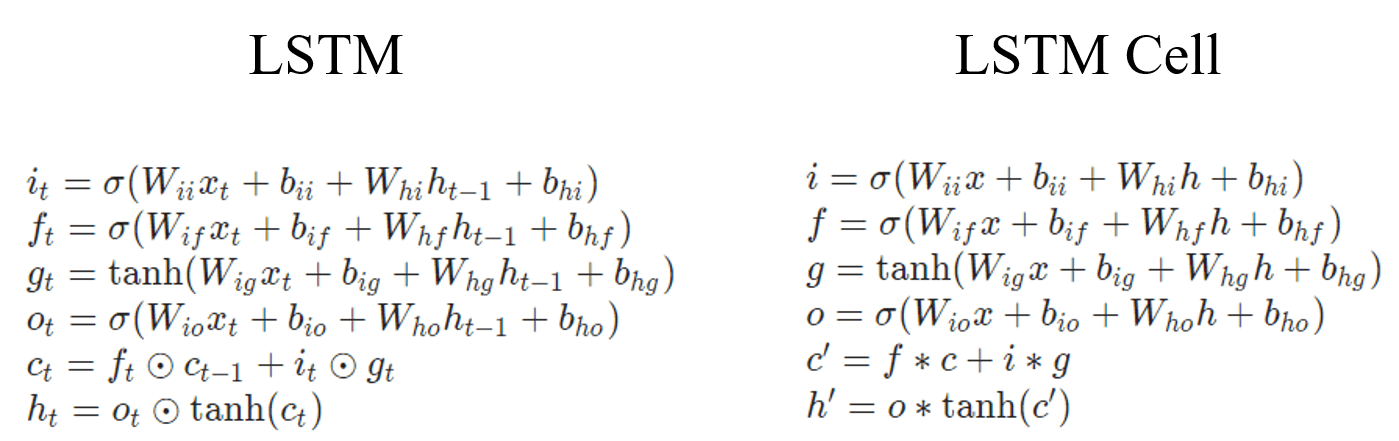
3.1 LSTM
3.2 LSTMCell
4 PyTorch实践:Encoder-Decoder模型
4.1 用LSTM写Encoder
# 由于成熟的封装,切换使用几种RNNs只需要换个名即可
str2rnn = {'lstm': nn.LSTM, 'gru': nn.GRU, 'rnn': nn.RNN}
class Encoder(nn.Module):
def __init__(self, n_src_words, d_model, src_pdx, n_layers, p_drop, bidirectional, rnn_type):
super().__init__()
self.d_model, self.n_layers, self.src_pdx = d_model, n_layers, src_pdx
self.n_directions = 2 if bidirectional else 1
self.input_embedding = nn.Embedding(n_src_words, d_model, padding_idx=src_pdx)
# 这里hidden_size=d_model/n_directions,是因为双向会堆叠一层导致最后的模型维度加倍,与Decoder不匹配
self.rnn = str2rnn[rnn_type](input_size=d_model, hidden_size=d_model // self.n_directions,
num_layers=n_layers, dropout=p_drop,
batch_first=True, bidirectional=bidirectional)
self.dropout = nn.Dropout(p=p_drop)
def forward(self, src_tokens):
# - src_embed: (batch_size, src_len, d_model)
src_embed = self.dropout(self.input_embedding(src_tokens))
src_lens = src_tokens.ne(self.src_pdx).long().sum(dim=-1)
packed_src_embed = nn.utils.rnn.pack_padded_sequence(
src_embed, src_lens.to('cpu'), batch_first=True, enforce_sorted=False
)
packed_encoder_out, _ = self.rnn(packed_src_embed)
# - encoder_out: (batch_size, src_len, d_model) where 3rd is last layer [h_fwd; (h_bkwd)]
encoder_out, _ = nn.utils.rnn.pad_packed_sequence(packed_encoder_out, batch_first=True)
return encoder_out
4.2 用LSTMCell写带attention的Decoder
4.2.1 Attention Layer
class AttentionLayer(nn.Module):
# 2015 luong et, Effective Approaches to Attention-based Neural Machine Translation
def __init__(self, d_model, attn_type='general'):
super().__init__()
self.attn_type = attn_type
if attn_type == 'dot':
pass
elif attn_type == 'general':
self.W_align = nn.Linear(d_model, d_model, bias=False)
elif attn_type == 'concat':
self.W_align_source = nn.Linear(d_model, d_model, bias=False)
self.W_align_memory = nn.Linear(d_model, d_model, bias=False)
self.v_align = nn.Linear(d_model, 1, bias=False)
else:
raise Exception
def forward(self, source, memory, mask=None):
# - source: (batch_size, tgt_len, d_model), memory: (batch_size, src_len, d_model)
batch_size, src_len, tgt_len = memory.size(0), memory.size(1), source.size(1)
if self.attn_type == 'dot':
score = torch.matmul(source, memory.transpose(1, 2))
elif self.attn_type == 'general':
score = torch.matmul(self.W_align(source), memory.transpose(1, 2))
elif self.attn_type == 'concat':
# (batch_size, tgt_len, d_model) can't directly concat with (batch_size, src_len, d_model)
source = self.W_align_source(
source.view(batch_size, tgt_len, 1, -1).expand(batch_size, tgt_len, src_len, -1))
memory = self.W_align_memory(
memory.view(batch_size, 1, src_len, -1).expand(batch_size, tgt_len, src_len, -1))
score = self.v_align(source + memory).view(batch_size, tgt_len, src_len)
else:
raise Exception
# - score: (batch_size, tgt_len, src_len)
if mask != None:
score.masked_fill_(mask, -1e9)
attn = F.softmax(score, dim=-1)
return attn
4.2.2 Decoder
class Decoder(nn.Module):
def __init__(self, n_tgt_words, d_model, tgt_pdx, n_layers, p_drop, attn_type, rnn_type):
super().__init__()
self.d_models = d_model
self.input_embedding = nn.Embedding(n_tgt_words, d_model, padding_idx=tgt_pdx)
self.attention = AttentionLayer(d_model=d_model, attn_type=attn_type)
self.rnn = str2rnn[rnn_type](input_size=d_model, hidden_size=d_model, num_layers=n_layers,
dropout=p_drop, batch_first=True, bidirectional=False)
self.W_context = nn.Linear(2 * d_model, d_model, bias=False) # for concat [c; h]
self.dropout = nn.Dropout(p=p_drop)
def forward(self, prev_tgt_tokens, encoder_out, src_mask):
# - tgt_embed: (batch_size, tgt_len, d_model)
tgt_embed = self.dropout(self.input_embedding(prev_tgt_tokens))
# - decoder_states: (batch_size, tgt_len, d_model)
decoder_states, _ = self.rnn(tgt_embed)
# - attn: (batch_size, tgt_len, src_len), encoder_out: (batch_size, src_len, d_model)
attn = self.attention(source=decoder_states, memory=encoder_out, mask=src_mask.unsqueeze(1))
# - context: (batch_size, tgt_len, d_model)
context = torch.matmul(attn, encoder_out)
# - decoder_out: (batch_size, tgt_len, d_model)
decoder_out = self.dropout(self.W_context(torch.cat([context, decoder_states], dim=-1)))
return decoder_out